
ICDL crawling
Encyclopedia
ICDL crawling is an open distributed web crawling
technology
based on Website Parse Template
(WPT).
 Website Parse Template (WPT)
Website Parse Template (WPT)
is an XML
based open format
which provides HTML
structure description of Web page
s. The WPT format allows web crawlers to generate Semantic Web
’s RDF triples
for Web pages. WPT is compatible with existing Semantic Web
concepts defined by W3C (RDF
, OWL
) and UNL
specifications.
considering HTML
structure templates represented in WPT files
.
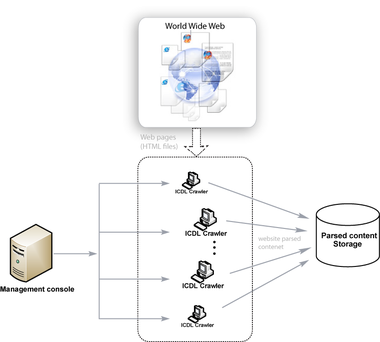
Distributed crawling is carried out by an open source
client application
installed on volunteers’ personal computer
s (PCs). After authentication
procedures, the application registers each PC as a distributed crawling node. The crawler periodically receives tasks from the management console to download specified websites, parse their content
and submit the results into parsed content storage. Crawling processes are activated when the users’ computers are idle.
Internet content parse results from several crawlers are compared by the management console to increase crawling results' accuracy. Crawling results can be stored to be used by thematic and general search engines
with different search algorithm
s, such as Google
, Live, Yahoo!
, Froogle, etc.
Distributed web crawling
Distributed web crawling is a distributed computing technique whereby Internet search engines employ many computers to index the Internet via web crawling. Such systems may allow for users to voluntarily offer their own computing and bandwidth resources towards crawling web pages...
technology
Technology
Technology is the making, usage, and knowledge of tools, machines, techniques, crafts, systems or methods of organization in order to solve a problem or perform a specific function. It can also refer to the collection of such tools, machinery, and procedures. The word technology comes ;...
based on Website Parse Template
Website Parse Template
Website Parse Template is an XML-based open format which provides HTML structure description of website pages. WPT format allows web crawlers to generate Semantic Web’s RDFs for web pages...
(WPT).
What is Website Parse Template?
Website Parse Template
Website Parse Template is an XML-based open format which provides HTML structure description of website pages. WPT format allows web crawlers to generate Semantic Web’s RDFs for web pages...
is an XML
XML
Extensible Markup Language is a set of rules for encoding documents in machine-readable form. It is defined in the XML 1.0 Specification produced by the W3C, and several other related specifications, all gratis open standards....
based open format
Open format
An open file format is a published specification for storing digital data, usually maintained by a standards organization, which can therefore be used and implemented by anyone. For example, an open format can be implementable by both proprietary and free and open source software, using the typical...
which provides HTML
HTML
HyperText Markup Language is the predominant markup language for web pages. HTML elements are the basic building-blocks of webpages....
structure description of Web page
Web page
A web page or webpage is a document or information resource that is suitable for the World Wide Web and can be accessed through a web browser and displayed on a monitor or mobile device. This information is usually in HTML or XHTML format, and may provide navigation to other web pages via hypertext...
s. The WPT format allows web crawlers to generate Semantic Web
Semantic Web
The Semantic Web is a collaborative movement led by the World Wide Web Consortium that promotes common formats for data on the World Wide Web. By encouraging the inclusion of semantic content in web pages, the Semantic Web aims at converting the current web of unstructured documents into a "web of...
’s RDF triples
Resource Description Framework
The Resource Description Framework is a family of World Wide Web Consortium specifications originally designed as a metadata data model...
for Web pages. WPT is compatible with existing Semantic Web
Semantic Web
The Semantic Web is a collaborative movement led by the World Wide Web Consortium that promotes common formats for data on the World Wide Web. By encouraging the inclusion of semantic content in web pages, the Semantic Web aims at converting the current web of unstructured documents into a "web of...
concepts defined by W3C (RDF
Resource Description Framework
The Resource Description Framework is a family of World Wide Web Consortium specifications originally designed as a metadata data model...
, OWL
Web Ontology Language
The Web Ontology Language is a family of knowledge representation languages for authoring ontologies.The languages are characterised by formal semantics and RDF/XML-based serializations for the Semantic Web...
) and UNL
Universal Networking Language
Universal Networking Language is a declarative formal language specifically designed to represent semantic data extracted from natural language texts...
specifications.
Distributed ICDL crawling
ICDL crawling involves parsing of websites’ contentWeb content
Web content is the textual, visual or aural content that is encountered as part of the user experience on websites. It may include, among other things: text, images, sounds, videos and animations....
considering HTML
HTML
HyperText Markup Language is the predominant markup language for web pages. HTML elements are the basic building-blocks of webpages....
structure templates represented in WPT files
Computer file
A computer file is a block of arbitrary information, or resource for storing information, which is available to a computer program and is usually based on some kind of durable storage. A file is durable in the sense that it remains available for programs to use after the current program has finished...
.
Distributed crawling is carried out by an open source
Open source
The term open source describes practices in production and development that promote access to the end product's source materials. Some consider open source a philosophy, others consider it a pragmatic methodology...
client application
Client (computing)
A client is an application or system that accesses a service made available by a server. The server is often on another computer system, in which case the client accesses the service by way of a network....
installed on volunteers’ personal computer
Personal computer
A personal computer is any general-purpose computer whose size, capabilities, and original sales price make it useful for individuals, and which is intended to be operated directly by an end-user with no intervening computer operator...
s (PCs). After authentication
Authentication
Authentication is the act of confirming the truth of an attribute of a datum or entity...
procedures, the application registers each PC as a distributed crawling node. The crawler periodically receives tasks from the management console to download specified websites, parse their content
Web content
Web content is the textual, visual or aural content that is encountered as part of the user experience on websites. It may include, among other things: text, images, sounds, videos and animations....
and submit the results into parsed content storage. Crawling processes are activated when the users’ computers are idle.
Internet content parse results from several crawlers are compared by the management console to increase crawling results' accuracy. Crawling results can be stored to be used by thematic and general search engines
Web search engine
A web search engine is designed to search for information on the World Wide Web and FTP servers. The search results are generally presented in a list of results often referred to as SERPS, or "search engine results pages". The information may consist of web pages, images, information and other...
with different search algorithm
Search algorithm
In computer science, a search algorithm is an algorithm for finding an item with specified properties among a collection of items. The items may be stored individually as records in a database; or may be elements of a search space defined by a mathematical formula or procedure, such as the roots...
s, such as Google
Google
Google Inc. is an American multinational public corporation invested in Internet search, cloud computing, and advertising technologies. Google hosts and develops a number of Internet-based services and products, and generates profit primarily from advertising through its AdWords program...
, Live, Yahoo!
Yahoo!
Yahoo! Inc. is an American multinational internet corporation headquartered in Sunnyvale, California, United States. The company is perhaps best known for its web portal, search engine , Yahoo! Directory, Yahoo! Mail, Yahoo! News, Yahoo! Groups, Yahoo! Answers, advertising, online mapping ,...
, Froogle, etc.
See also
- Website Parse TemplateWebsite Parse TemplateWebsite Parse Template is an XML-based open format which provides HTML structure description of website pages. WPT format allows web crawlers to generate Semantic Web’s RDFs for web pages...
- Distributed web crawlingDistributed web crawlingDistributed web crawling is a distributed computing technique whereby Internet search engines employ many computers to index the Internet via web crawling. Such systems may allow for users to voluntarily offer their own computing and bandwidth resources towards crawling web pages...
- Web search engineWeb search engineA web search engine is designed to search for information on the World Wide Web and FTP servers. The search results are generally presented in a list of results often referred to as SERPS, or "search engine results pages". The information may consist of web pages, images, information and other...
- Web crawlerWeb crawlerA Web crawler is a computer program that browses the World Wide Web in a methodical, automated manner or in an orderly fashion. Other terms for Web crawlers are ants, automatic indexers, bots, Web spiders, Web robots, or—especially in the FOAF community—Web scutters.This process is called Web...
- OMFICA