The World Wide Web Consortium is the main international standards organization for the World Wide Web .Founded and headed by Tim Berners-Lee, the consortium is made up of member organizations which maintain full-time staff for the purpose of working together in the development of standards for the...
(W3C) that promotes common formats for data on the World Wide Web
World Wide Web
The World Wide Web is a system of interlinked hypertext documents accessed via the Internet...
Semantics is the study of meaning. It focuses on the relation between signifiers, such as words, phrases, signs and symbols, and what they stand for, their denotata....
content in web pages, the Semantic Web aims at converting the current web of unstructured documents into a "web of data". It builds on the W3C's Resource Description Framework
Resource Description Framework
The Resource Description Framework is a family of World Wide Web Consortium specifications originally designed as a metadata data model...
(RDF).
According to the W3C, "The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries."
The World Wide Web Consortium is the main international standards organization for the World Wide Web .Founded and headed by Tim Berners-Lee, the consortium is made up of member organizations which maintain full-time staff for the purpose of working together in the development of standards for the...
("W3C"), which oversees the development of proposed Semantic Web standards. He defines the Semantic Web as "a web of data that can be processed directly and indirectly by machines."
While its critics have questioned its feasibility, proponents argue that applications in industry, biology and human sciences research have already proven the validity of the original concept.
History
The concept of the Semantic Network Model was coined in the early sixties by the cognitive scientist Allan M. Collins
Allan M. Collins
Allan M. Collins is an American cognitive scientist and Professor Emeritus of Learning Sciences at Northwestern University's School of Education and Social Policy...
, linguist M. Ross Quillian and psychologist Elizabeth F. Loftus in various publications, as a form to represent semantically structured knowledge. It extends the network of hyperlink
Hyperlink
In computing, a hyperlink is a reference to data that the reader can directly follow, or that is followed automatically. A hyperlink points to a whole document or to a specific element within a document. Hypertext is text with hyperlinks...
ed human-readable web pages by inserting machine-readable metadata
Metadata
The term metadata is an ambiguous term which is used for two fundamentally different concepts . Although the expression "data about data" is often used, it does not apply to both in the same way. Structural metadata, the design and specification of data structures, cannot be about data, because at...
about pages and how they are related to each other, enabling automated agents to access the Web more intelligently and perform tasks on behalf of users. The term was coined by Tim Berners-Lee
Tim Berners-Lee
Sir Timothy John "Tim" Berners-Lee, , also known as "TimBL", is a British computer scientist, MIT professor and the inventor of the World Wide Web...
The World Wide Web Consortium is the main international standards organization for the World Wide Web .Founded and headed by Tim Berners-Lee, the consortium is made up of member organizations which maintain full-time staff for the purpose of working together in the development of standards for the...
("W3C"), which oversees the development of proposed Semantic Web standards. He defines the Semantic Web as "a web of data that can be processed directly and indirectly by machines."
Many of the technologies proposed by the W3C already existed before they were positioned under the W3C umbrella. These are used in various contexts, particularly those dealing with information that encompasses a limited and defined domain, and where sharing data is a common necessity, such as scientific research or data exchange among businesses. In addition, other technologies with similar goals have emerged, such as microformat
Microformat
A microformat is a web-based approach to semantic markup which seeks to re-use existing HTML/XHTML tags to convey metadata and other attributes in web pages and other contexts that support HTML, such as RSS...
s.
Purpose
The main purpose of the Semantic Web is driving the evolution of the current Web by enabling users to find, share, and combine information more easily.
Humans are capable of using the Web to carry out tasks such as finding the Irish
Irish language
Irish , also known as Irish Gaelic, is a Goidelic language of the Indo-European language family, originating in Ireland and historically spoken by the Irish people. Irish is now spoken as a first language by a minority of Irish people, as well as being a second language of a larger proportion of...
word for "folder", reserving a library book, and searching for the lowest price for a DVD. However, machines cannot accomplish all of these tasks without human direction, because web pages are designed to be read by people, not machines. The semantic web is a vision of information that can be readily interpreted by machines, so machines can perform more of the tedious work involved in finding, combining, and acting upon information on the web.
The Semantic Web, as originally envisioned, is a system that enables machines to "understand" and respond to complex human requests based on their meaning. Such an "understanding" requires that the relevant information sources is semantically structured, a challenging task.
Tim Berners-Lee originally expressed the vision of the Semantic Web as follows:
The Semantic Web is regarded as an integrator across different content, information applications and systems. It has applications in publishing, blogging, and many other areas.
Semantics is the study of meaning. It focuses on the relation between signifiers, such as words, phrases, signs and symbols, and what they stand for, their denotata....
The term metadata is an ambiguous term which is used for two fundamentally different concepts . Although the expression "data about data" is often used, it does not apply to both in the same way. Structural metadata, the design and specification of data structures, cannot be about data, because at...
", "ontologies" and "Semantic Web" are used inconsistently. In particular, these terms are used as everyday terminology by researchers and practitioners, spanning a vast landscape of different fields, technologies, concepts and application areas. Furthermore, there is confusion with regard to the current status of the enabling technologies envisioned to realize the Semantic Web. In a paper presented by Gerber, Barnard and Van der Merwe the Semantic Web landscape is charted and a brief summary of related terms and enabling technologies is presented. The architectural model proposed by Tim Berners-Lee is used as basis to present a status model that reflects current and emerging technologies.
Limitations of HTML
Many files on a typical computer can be loosely divided into human readable document
Document
The term document has multiple meanings in ordinary language and in scholarship. WordNet 3.1. lists four meanings :* document, written document, papers...
The term data refers to qualitative or quantitative attributes of a variable or set of variables. Data are typically the results of measurements and can be the basis of graphs, images, or observations of a set of variables. Data are often viewed as the lowest level of abstraction from which...
. Documents like mail messages, reports, and brochures are read by humans. Data, like calendars, addressbooks, playlists, and spreadsheets are presented using an application program which lets them be viewed, searched and combined in different ways.
Currently, the World Wide Web is based mainly on documents written in Hypertext Markup Language (HTML
HTML
HyperText Markup Language is the predominant markup language for web pages. HTML elements are the basic building-blocks of webpages....
), a markup convention that is used for coding a body of text interspersed with multimedia objects such as images and interactive forms. Metadata tags provide a method by which computers can categorise the content of web pages, for example:
With HTML and a tool to render it (perhaps web browser
Web browser
A web browser is a software application for retrieving, presenting, and traversing information resources on the World Wide Web. An information resource is identified by a Uniform Resource Identifier and may be a web page, image, video, or other piece of content...
In computing, a user agent is a client application implementing a network protocol used in communications within a client–server distributed computing system...
), one can create and present a page that lists items for sale. The HTML of this catalog page can make simple, document-level assertions such as "this document's title is 'Widget Superstore'", but there is no capability within the HTML itself to assert unambiguously that, for example, item number X586172 is an Acme Gizmo with a retail price of €199, or that it is a consumer product. Rather, HTML can only say that the span of text "X586172" is something that should be positioned near "Acme Gizmo" and "€199", etc. There is no way to say "this is a catalog" or even to establish that "Acme Gizmo" is a kind of title or that "€199" is a price. There is also no way to express that these pieces of information are bound together in describing a discrete item, distinct from other items perhaps listed on the page.
Semantic HTML is the use of HTML markup to reinforce the semantics, or meaning, of the information in webpages rather than merely to define its presentation . Semantic HTML is processed by regular web browsers as well as by many other user agents...
refers to the traditional HTML practice of markup following intention, rather than specifying layout details directly. For example, the use of denoting "emphasis" rather than , which specifies italics. Layout details are left up to the browser, in combination with Cascading Style Sheets
Cascading Style Sheets
Cascading Style Sheets is a style sheet language used to describe the presentation semantics of a document written in a markup language...
. But this practice falls short of specifying the semantics of objects such as items for sale or prices.
A microformat is a web-based approach to semantic markup which seeks to re-use existing HTML/XHTML tags to convey metadata and other attributes in web pages and other contexts that support HTML, such as RSS...
s represent unofficial attempts to extend HTML syntax to create machine-readable semantic markup about objects such as retail stores and items for sale.
Semantic Web solutions
The Semantic Web takes the solution further. It involves publishing in languages specifically designed for data: Resource Description Framework
Resource Description Framework
The Resource Description Framework is a family of World Wide Web Consortium specifications originally designed as a metadata data model...
The Web Ontology Language is a family of knowledge representation languages for authoring ontologies.The languages are characterised by formal semantics and RDF/XML-based serializations for the Semantic Web...
Extensible Markup Language is a set of rules for encoding documents in machine-readable form. It is defined in the XML 1.0 Specification produced by the W3C, and several other related specifications, all gratis open standards....
). HTML describes documents and the links between them. RDF, OWL, and XML, by contrast, can describe arbitrary things such as people, meetings, or airplane parts.
These technologies are combined in order to provide descriptions that supplement or replace the content of Web documents. Thus, content may manifest itself as descriptive data stored in Web-accessible database
Database
A database is an organized collection of data for one or more purposes, usually in digital form. The data are typically organized to model relevant aspects of reality , in a way that supports processes requiring this information...
s, or as markup within documents (particularly, in Extensible HTML (XHTML
XHTML
XHTML is a family of XML markup languages that mirror or extend versions of the widely-used Hypertext Markup Language , the language in which web pages are written....
) interspersed with XML, or, more often, purely in XML, with layout or rendering cues stored separately). The machine-readable descriptions enable content managers to add meaning to the content, i.e., to describe the structure of the knowledge we have about that content. In this way, a machine can process knowledge itself, instead of text, using processes similar to human deductive reasoning
Deductive reasoning
Deductive reasoning, also called deductive logic, is reasoning which constructs or evaluates deductive arguments. Deductive arguments are attempts to show that a conclusion necessarily follows from a set of premises or hypothesis...
Inference is the act or process of deriving logical conclusions from premises known or assumed to be true. The conclusion drawn is also called an idiomatic. The laws of valid inference are studied in the field of logic.Human inference Inference is the act or process of deriving logical conclusions...
, thereby obtaining more meaningful results and helping computers to perform automated information gathering and research
Research
Research can be defined as the scientific search for knowledge, or as any systematic investigation, to establish novel facts, solve new or existing problems, prove new ideas, or develop new theories, usually using a scientific method...
.
An example of a tag that would be used in a non-semantic web page:
cat
Encoding similar information in a semantic web page might look like this:
In computing, linked data describes a method of publishing structured data so that it can be interlinked and become more useful. It builds upon standard Web technologies such as HTTP and URIs, but rather than using them to serve web pages for human readers, it extends them to share information in a...
Giant Global Graph is a name coined by the inventor of the World Wide Web, Tim Berners-Lee in 2007, to help distinguish between the nature and significance of the content on the existing World Wide Web, and that of the next-generation web, or "Web 3.0"...
The World Wide Web is a system of interlinked hypertext documents accessed via the Internet...
. Berners-Lee posits that if the past was document sharing, the future is data sharing. His answer to the question of "how" provides three points of instruction. One, a URL should point to the data. Two, anyone accessing the URL should get data back. Three, relationships in the data should point to additional URLs with data.
Sir Timothy John "Tim" Berners-Lee, , also known as "TimBL", is a British computer scientist, MIT professor and the inventor of the World Wide Web...
has described the semantic web as a component of 'Web 3.0'.
"Semantic Web" is sometimes used as a synonym for "Web 3.0", though each term's definition varies.
Examples
When we talk about the Semantic Web, we speak about many "howto’s" which are often incomprehensible because the required notions of linguistics are very often ignored by most people.
Thus, we are going to rather imagine what is going to look like the future with the emergence of the Semantic Web.
Meta-Wiki
The sites of Wiki type soar. Their administrations and their objectives can be very different. These wikis are more and more specialized.
But most of wikis limit the search engines to index them because these search engines decrease the wikis' efficiency and record pages which are obsolete, by definition, outside the wiki (perpetual update).
Meta- search-engines are going to aggregate the obtained result by requesting individually at each of these wikis. The wikis become silos of available data for consultation by people and machines through access points (triplestore
Triplestore
A triplestore is a purpose-built database for the storage and retrieval of Resource Description Framework metadata.Much like a relational database, one stores information in a triplestore and retrieves it via a query language...
).
Semantic detectives & Semantic identity
The young bloggers are now on the labour market. The companies do not ask any longer for the judicial file of a new employee. To have information, the companies appeal in a systematic way to engines which are going to interrogate all the sites which reference and index the accessible information on the Web.
The differentiation between search engines is going to concern the capacity to respond at requests where the sense is going to take more and more importance (evolution of the requests with keywords towards the semantic requests).
There will be three types of person: the unknown, the "without splash" and the others. The others will have to erase in a systematic way the information which could carry disadvantages and which will be more and more accessible. It will be the same engines of semantic search which also charge this service.
Profile Privacy/Consumer/Public
The Web's children became parents. They use tools which can limit the access and the spreading of the information by their children. So, the parents can see at any time the web's logs of their children but they also have a net which is going to filter their "private" identity before it is broadcasted on the network.
For example, a third-part trust entity, along with their mobile telephone provider, the post office and the bank, will possess the consumer’s identity so as to mask the address of delivery and the payment of this consumer.
A public identity also exists to spread a resume (CV), a blog or an avatar for example but the data remain the property of the owner of the server who hosts this data. So, the mobile telephone provider offers a personal server who will contain one public zone who will automatically be copied on the network after every modification. If I want that my resume is not any longer on the network, I just have to erase it of my public zone from my server. So, the mobile telephone provider creates a controllable silo of information for every public profile.
Personal agent
In a few years, the last generation of robot is now mobile and transcribes the human voice. However, it has to transfer the semantic interpretation to more powerful computers. These servers can so interpret the sense of simple sentences and interrogate other servers to calculate the answer to be given. Example:
"Arthur returned at him. He ordered a pizza by his personal digital agent. His agent is going to send the information to the home server which will accept or not the purchase. It refuses because it received the order of the Arthur's parents to buy only a well-balanced menu. So, the home server displays on the TV3D the authorized menus to allow Arthur to choose a new meal."
Research assistant
In 20??, the Semantic Web is now a reality.
Marc is a researcher. He has a new idea. He is going to clarify it with his digital assistant which is immediately going to show him the incoherence of his demonstration by using the accessible knowledge in silos on the Web. Marc will be able to modify his reasoning or to find the proofs which demonstrate that the existing knowledge is false and so to advance the scientific knowledge within the Semantic Web.
Challenges
Some of the challenges for the Semantic Web include vastness, vagueness, uncertainty, inconsistency, and deceit. Automated reasoning systems will have to deal with all of these issues in order to deliver on the promise of the Semantic Web.
SNOMED CT , is a systematically organised computer processable collection of medical terminology covering most areas of clinical information such as diseases, findings, procedures, microorganisms, substances, etc...
medical terminology ontology alone contains 370,000 class names, and existing technology has not yet been able to eliminate all semantically duplicated terms. Any automated reasoning system will have to deal with truly huge inputs.
Vagueness: These are imprecise concepts like "young" or "tall". This arises from the vagueness of user queries, of concepts represented by content providers, of matching query terms to provider terms and of trying to combine different knowledge bases with overlapping but subtly different concepts. Fuzzy logic
Fuzzy logic
Fuzzy logic is a form of many-valued logic; it deals with reasoning that is approximate rather than fixed and exact. In contrast with traditional logic theory, where binary sets have two-valued logic: true or false, fuzzy logic variables may have a truth value that ranges in degree between 0 and 1...
is the most common technique for dealing with vagueness.
Uncertainty: These are precise concepts with uncertain values. For example, a patient might present a set of symptoms which correspond to a number of different distinct diagnoses each with a different probability. Probabilistic
Probabilistic logic
The aim of a probabilistic logic is to combine the capacity of probability theory to handle uncertainty with the capacity of deductive logic to exploit structure. The result is a richer and more expressive formalism with a broad range of possible application areas...
reasoning techniques are generally employed to address uncertainty.
Inconsistency: These are logical contradictions which will inevitably arise during the development of large ontologies, and when ontologies from separate sources are combined. Deductive reasoning
Deductive reasoning
Deductive reasoning, also called deductive logic, is reasoning which constructs or evaluates deductive arguments. Deductive arguments are attempts to show that a conclusion necessarily follows from a set of premises or hypothesis...
The principle of explosion, or the principle of Pseudo-Scotus, is the law of classical logic and intuitionistic and similar systems of logic, according to which any statement can be proven from a contradiction...
A paraconsistent logic is a logical system that attempts to deal with contradictions in a discriminating way. Alternatively, paraconsistent logic is the subfield of logic that is concerned with studying and developing paraconsistent systems of logic.Inconsistency-tolerant logics have been...
are two techniques which can be employed to deal with inconsistency.
Deceit: This is when the producer of the information is intentionally misleading the consumer of the information. Cryptography
Cryptography
Cryptography is the practice and study of techniques for secure communication in the presence of third parties...
techniques are currently utilized to alleviate this threat.
This list of challenges is illustrative rather than exhaustive, and it focuses on the challenges to the "unifying logic" and "proof" layers of the Semantic Web. The World Wide Web Consortium
World Wide Web Consortium
The World Wide Web Consortium is the main international standards organization for the World Wide Web .Founded and headed by Tim Berners-Lee, the consortium is made up of member organizations which maintain full-time staff for the purpose of working together in the development of standards for the...
(W3C) Incubator Group for Uncertainty Reasoning for the World Wide Web (URW3-XG) final report lumps these problems together under the single heading of "uncertainty". Many of the techniques mentioned here will require extensions to the Web Ontology Language
Web Ontology Language
The Web Ontology Language is a family of knowledge representation languages for authoring ontologies.The languages are characterised by formal semantics and RDF/XML-based serializations for the Semantic Web...
(OWL) for example to annotate conditional probabilities. This is an area of active research.
Standards
Standardization for Semantic Web in the context of Web 3.0 is under the care of W3C.
Components
The term "Semantic Web" is often used more specifically to refer to the formats and technologies that enable it. The collection, structuring and recovery of linked data are enabled by technologies that provide a formal description
Description logic
Description logic is a family of formal knowledge representation languages. It is more expressive than propositional logic but has more efficient decision problems than first-order predicate logic....
of concepts, terms, and relationships within a given knowledge domain. These technologies are specified as W3C standards and include:
RDF Schema is a set of classes with certain properties using the RDF extensible knowledge representation language, providing basic elements for the description of ontologies, otherwise called RDF vocabularies, intended to structure RDF resources...
SPARQL is an RDF query language; its name is an acronym that stands for SPARQL Protocol and RDF Query Language. It was made a standard by the RDF Data Access Working Group of the World Wide Web Consortium, and considered as one of the key technologies of semantic web...
, an RDF query language
Notation3 (N3), designed with human-readability in mind
N-Triples is a format for storing and transmitting data. It is a line-based, plain text serialisation format for RDF graphs, and a subset of the Turtle format. N-Triples should not be confused with Notation 3 which is a superset of Turtle...
Turtle is a serialization format for Resource Description Framework graphs. A subset of Tim Berners-Lee and Dan Connolly's Notation3 language, it was defined by Dave Beckett, and is a superset of the minimal N-Triples format. Unlike full N3, Turtle doesn't go beyond RDF's graph model...
The Web Ontology Language is a family of knowledge representation languages for authoring ontologies.The languages are characterised by formal semantics and RDF/XML-based serializations for the Semantic Web...
(OWL), a family of knowledge representation languages
Extensible Markup Language is a set of rules for encoding documents in machine-readable form. It is defined in the XML 1.0 Specification produced by the W3C, and several other related specifications, all gratis open standards....
provides an elemental syntax for content structure within documents, yet associates no semantics with the meaning of the content contained within. XML is not at present a necessary component of Semantic Web technologies in most cases, as alternative syntaxes exists, such as Turtle
Turtle (syntax)
Turtle is a serialization format for Resource Description Framework graphs. A subset of Tim Berners-Lee and Dan Connolly's Notation3 language, it was defined by Dave Beckett, and is a superset of the minimal N-Triples format. Unlike full N3, Turtle doesn't go beyond RDF's graph model...
. Turtle is a de facto standard, but has not been through a formal standardization process.
XML Schema is a language for providing and restricting the structure and content of elements contained within XML documents.
RDF is a simple language for expressing data model
Data model
A data model in software engineering is an abstract model, that documents and organizes the business data for communication between team members and is used as a plan for developing applications, specifically how data is stored and accessed....
The concept of resource is primitive in the Web architecture, and is used in the definition of its fundamental elements. The term was first introduced to refer to targets of Uniform Resource Locators , but its definition has been further extended to include the referent of any Uniform Resource...
s") and their relationships. An RDF-based model can be represented in a variety of syntaxes, e.g., RDF/XML, N3, Turtle, and RDFa. RDF is a fundamental standard of the Semantic Web.
RDF Schema extends RDF and is a vocabulary for describing properties and classes of RDF-based resources, with semantics for generalized-hierarchies of such properties and classes.
OWL adds more vocabulary for describing properties and classes: among others, relations between classes (e.g. disjointness), cardinality (e.g. "exactly one"), equality, richer typing of properties, characteristics of properties (e.g. symmetry), and enumerated classes.
SPARQL is a protocol and query language for semantic web data sources.
Usability is the ease of use and learnability of a human-made object. The object of use can be a software application, website, book, tool, machine, process, or anything a human interacts with. A usability study may be conducted as a primary job function by a usability analyst or as a secondary job...
and usefulness of the Web and its interconnected resources
Resource (computer science)
A resource, or system resource, is any physical or virtual component of limited availability within a computer system. Every device connected to a computer system is a resource. Every internal system component is a resource...
through:
Servers which expose existing data systems using the RDF and SPARQL standards. Many converters to RDF exist from different applications. Relational database
Relational database
A relational database is a database that conforms to relational model theory. The software used in a relational database is called a relational database management system . Colloquial use of the term "relational database" may refer to the RDBMS software, or the relational database itself...
s are an important source. The semantic web server attaches to the existing system without affecting its operation.
Documents "marked up" with semantic information (an extension
Extension (computing)
Software extension, is a file containing programming that serves to extend the capabilities of or data available to a more basic program. It is a kind of list of commands which are directly included in the program. This term often coincides with the plug-in...
An HTML element is an individual component of an HTML document. HTML documents are composed of a tree of HTML elements and other nodes, such as text nodes. Each element can have attributes specified. Elements can also have content, including other elements and text. HTML elements represent...
Information in its most restricted technical sense is a message or collection of messages that consists of an ordered sequence of symbols, or it is the meaning that can be interpreted from such a message or collection of messages. Information can be recorded or transmitted. It can be recorded as...
A web search engine is designed to search for information on the World Wide Web and FTP servers. The search results are generally presented in a list of results often referred to as SERPS, or "search engine results pages". The information may consist of web pages, images, information and other...
A Web crawler is a computer program that browses the World Wide Web in a methodical, automated manner or in an orderly fashion. Other terms for Web crawlers are ants, automatic indexers, bots, Web spiders, Web robots, or—especially in the FOAF community—Web scutters.This process is called Web...
Artificial intelligence is the intelligence of machines and the branch of computer science that aims to create it. AI textbooks define the field as "the study and design of intelligent agents" where an intelligent agent is a system that perceives its environment and takes actions that maximize its...
information about the human-understandable content of the document (such as the creator, title, description, etc., of the document) or it could be purely metadata representing a set of facts (such as resources and services elsewhere in the site). (Note that anything that can be identified with a Uniform Resource Identifier (URI
Uniform Resource Identifier
In computing, a uniform resource identifier is a string of characters used to identify a name or a resource on the Internet. Such identification enables interaction with representations of the resource over a network using specific protocols...
) can be described, so the semantic web can reason about animals, people, places, ideas, etc.) Semantic markup is often generated automatically, rather than manually.
Common metadata vocabularies (ontologies) and maps between vocabularies that allow document creators to know how to mark up their documents so that agents can use the information in the supplied metadata (so that Author in the sense of 'the Author of the page' won't be confused with Author in the sense of a book that is the subject of a book review).
Automated agents to perform tasks for users of the semantic web using this data
Web-based services (often with agents of their own) to supply information specifically to agents (for example, a Trust service that an agent could ask if some online store has a history of poor service or spamming)
Practical feasibility
Critics (e.g. Which Semantic Web?) question the basic feasibility of a complete or even partial fulfillment of the semantic web. Cory Doctorow
Cory Doctorow
Cory Efram Doctorow is a Canadian-British blogger, journalist, and science fiction author who serves as co-editor of the blog Boing Boing. He is an activist in favour of liberalising copyright laws and a proponent of the Creative Commons organization, using some of their licences for his books...
Metacrap is a portmanteau drawn from metadata and crap. The origin of the word is unknown, but it was popularized by Cory Doctorow in a 2001 essay titled "Metacrap: Putting the torch to seven straw-men of the meta-utopia."...
") is from the perspective of human behavior and personal preferences. For example, people lie: they may include spurious metadata into Web pages in an attempt to mislead Semantic Web engines that naively assume the metadata's veracity. This phenomenon was well-known with metatags that fooled the AltaVista ranking algorithm into elevating the ranking of certain Web pages: the Google indexing engine specifically looks for such attempts at manipulation. Peter Gärdenfors
Peter Gärdenfors
Bjorn Peter Gärdenfors is a professor of cognitive science at the University of Lund, Sweden. He is a member of the Royal Swedish Academy of Letters, History and Antiquities and recipient of the Gad Rausing Prize . He received his doctorate from Lund University in 1974; his thesis title was...
Timo Honkela, PhD is Chief Research Scientist at the Department of Information and Computer Science at Aalto University School of Science...
point out that logic-based semantic web technologies cover only a fraction of the relevant phenomena related to semantics.
Where semantic web technologies have found a greater degree of practical adoption, it has tended to be among core specialized communities and organizations for intra-company projects. The practical constraints toward adoption have appeared less challenging where domain and scope is more limited than that of the general public and the World-Wide Web.
Scientific American is a popular science magazine. It is notable for its long history of presenting science monthly to an educated but not necessarily scientific public, through its careful attention to the clarity of its text as well as the quality of its specially commissioned color graphics...
article by Berners-Lee described an expected evolution of the existing Web to a Semantic Web. A complete evolution as described by Berners-Lee has yet to occur. In 2006, Berners-Lee and colleagues stated that: "This simple idea, however, remains largely unrealized." While the idea is still in the making, it seems to evolve quickly and inspire many. Between 2007–2010 several scholars have explored the social potential of the semantic web in the business and health sectors, and for social networking. They have also explored the broader evolution of democracy: how a society forms its common will in a democratic manner through a semantic web.
Censorship and privacy
Enthusiasm about the semantic web could be tempered by concerns regarding censorship
Internet censorship
Internet censorship is the control or suppression of the publishing of, or access to information on the Internet. It may be carried out by governments or by private organizations either at the behest of government or on their own initiative...
Privacy is the ability of an individual or group to seclude themselves or information about themselves and thereby reveal themselves selectively...
. For instance, text-analyzing techniques can now be easily bypassed by using other words, metaphors for instance, or by using images in place of words. An advanced implementation of the semantic web would make it much easier for governments to control the viewing and creation of online information, as this information would be much easier for an automated content-blocking machine to understand. In addition, the issue has also been raised that, with the use of FOAF
FOAF (software)
FOAF is a machine-readable ontology describing persons, their activities and their relations to other people and objects. Anyone can use FOAF to describe him or herself...
files and geo location meta-data, there would be very little anonymity associated with the authorship of articles on things such as a personal blog
Blog
A blog is a type of website or part of a website supposed to be updated with new content from time to time. Blogs are usually maintained by an individual with regular entries of commentary, descriptions of events, or other material such as graphics or video. Entries are commonly displayed in...
. Some of these concerns were addressed in the "Policy Aware Web" project and is an active research and development topic.
Doubling output formats
Another criticism of the semantic web is that it would be much more time-consuming to create and publish content because there would need to be two formats for one piece of data: one for human viewing and one for machines. However, many web application
Web application
A web application is an application that is accessed over a network such as the Internet or an intranet. The term may also mean a computer software application that is coded in a browser-supported language and reliant on a common web browser to render the application executable.Web applications are...
s in development are addressing this issue by creating a machine-readable format upon the publishing of data or the request of a machine for such data. The development of microformat
Microformat
A microformat is a web-based approach to semantic markup which seeks to re-use existing HTML/XHTML tags to convey metadata and other attributes in web pages and other contexts that support HTML, such as RSS...
s has been one reaction to this kind of criticism. Another argument in defense of the feasibility of semantic web is the likely falling price of human intelligence tasks in digital labor markets, such as the Amazon Mechanical Turk
Amazon Mechanical Turk
The Amazon Mechanical Turk is a crowdsourcing Internet marketplace that enables computer programmers to co-ordinate the use of human intelligence to perform tasks that computers are unable to do yet. It is one of the suites of Amazon Web Services...
GRDDL is a markup format for Gleaning Resource Descriptions from Dialects of Languages. It is a W3C Recommendation, and enables users to obtain RDF triples out of XML documents, including XHTML. The GRDDL specification shows examples using XSLT, however it was intended to be abstract enough to...
(Gleaning Resource Descriptions from Dialects of Language) mechanism allows existing material (including microformats) to be automatically interpreted as RDF
Resource Description Framework
The Resource Description Framework is a family of World Wide Web Consortium specifications originally designed as a metadata data model...
, so publishers only need to use a single format, such as HTML.
Projects
This section lists some of the many projects and tools that exist to create Semantic Web solutions.
DBpedia is a project aiming to extract structured content from the information created as part of the Wikipedia project. This structured information is then made available on the World Wide Web. DBpedia allows users to query relationships and properties associated with Wikipedia resources,...
is an effort to publish structured data extracted from Wikipedia: the data is published in RDF and made available on the Web for use under the GNU Free Documentation License
GNU Free Documentation License
The GNU Free Documentation License is a copyleft license for free documentation, designed by the Free Software Foundation for the GNU Project. It is similar to the GNU General Public License, giving readers the rights to copy, redistribute, and modify a work and requires all copies and...
, thus allowing Semantic Web agents to provide inferencing and advanced querying over the Wikipedia-derived dataset and facilitating interlinking, re-use and extension in other data-sources.
FOAF is a machine-readable ontology describing persons, their activities and their relations to other people and objects. Anyone can use FOAF to describe him or herself...
(or FoaF), which uses RDF to describe the relationships people have to other people and the "things" around them. FOAF permits intelligent agents to make sense of the thousands of connections people have with each other, their jobs and the items important to their lives; connections that may or may not be enumerated in searches using traditional web search engines. Because the connections are so vast in number, human interpretation of the information may not be the best way of analyzing them.
FOAF is an example of how the Semantic Web attempts to make use of the relationships within a social context.
GoodRelations for e-commerce
A huge potential for Semantic Web technologies lies in adding data structure and typed links to the vast amount of offer data, product model features, and tendering / request for quotation data.
The GoodRelations ontology is a popular vocabulary for expressing product information, prices, payment options, etc. It also allows expressing demand in a straightforward fashion.
GoodRelations has been adopted by Google, BestBuy, Overstock, Yahoo, OpenLink Software, O'Reilly Media, the Book Mashup, and many others.
SIOC
The Semantically-Interlinked Online Communities project (SIOC, pronounced "shock") provides a vocabulary of terms and relationships that model web data spaces. Examples of such data spaces include, among others: discussion forums, blog
Blog
A blog is a type of website or part of a website supposed to be updated with new content from time to time. Blogs are usually maintained by an individual with regular entries of commentary, descriptions of events, or other material such as graphics or video. Entries are commonly displayed in...
A mailing list is a collection of names and addresses used by an individual or an organization to send material to multiple recipients. The term is often extended to include the people subscribed to such a list, so the group of subscribers is referred to as "the mailing list", or simply "the...
s, shared bookmarks and image galleries.
SIMILE
Semantic Interoperability of Metadata and Information in unLike Environments
SIMILE was a joint project, conducted by the MIT Libraries and MIT CSAIL and funded by the Mellon Foundation, which sought to enhance interoperability among digital assets, schemata/vocabularies/ontologies, meta data, and services. With completion of the project, many of its tools were open sourced and spun out to simile-widgets, a community-managed site.
NextBio
A database consolidating high-throughput life sciences experimental data tagged and connected via biomedical ontologies. Nextbio
Nextbio
NextBio is a privately owned software company that provides a platform for drug companies and life science researchers to search, discover, and share knowledge across public and proprietary data...
is accessible via a search engine interface. Researchers can contribute their findings for incorporation to the database. The database currently supports gene or protein expression data and sequence centric data and is steadily expanding to support other biological data types.
ANTOM
ANTOM automates the categorization of text documents, and enables the retrieval of information by semantic search
Semantic search
Semantic search seeks to improve search accuracy by understanding searcher intent and the contextual meaning of terms as they appear in the searchable dataspace, whether on the Web or within a closed system, to generate more relevant results. Author Seth Grimes lists "11 approaches that join...
Acronyms and initialisms are abbreviations formed from the initial components in a phrase or a word. These components may be individual letters or parts of words . There is no universal agreement on the precise definition of the various terms , nor on written usage...
The Linking Open Data project is a W3C-led effort to create openly accessible, and interlinked, RDF Data on the Web. The data in question takes the form of RDF Data Sets drawn from a broad collection of data sources. There is a focus on the Linked Data
Linked Data
In computing, linked data describes a method of publishing structured data so that it can be interlinked and become more useful. It builds upon standard Web technologies such as HTTP and URIs, but rather than using them to serve web pages for human readers, it extends them to share information in a...
style of publishing RDF on the Web.
OpenPSI
OpenPSI (OpenPSI project) is a sponsored academic project that aims to create a UK government linked data service that supports research. It is a collaboration between the University of Southampton
University of Southampton
The University of Southampton is a British public university located in the city of Southampton, England, a member of the Russell Group. The origins of the university can be dated back to the founding of the Hartley Institution in 1862 by Henry Robertson Hartley. In 1902, the Institution developed...
The Office of Public Sector Information is the body responsible for the operation of Her Majesty's Stationery Office and of other public information services of the United Kingdom...
at The National Archives and is supported by JISC funding.
GoPubMed
Is the first semantic search engine for the life sciences. It uses the GeneOntology (GO) and the Medical Subject Headings (MeSH) to semantically filter millions of biomedical abstracts from MEDLINE. The public website GoPubMed.com allows users to verify papers including their background information.
See also
Agris: International Information System for the Agricultural Sciences and Technology
Business Semantics Management encompasses the technology, methodology, organization, and culture that brings business stakeholders together to collaboratively realize the reconciliation of their heterogeneous metadata; and consequently the application of the derived business semantics patterns to...
Computational semantics is the study of how to automate the process of constructing and reasoning with meaning representations of natural language expressions...
The term Corporate Semantic Web is used to describe the application of Semantic Web technologies and Knowledge Management methodologies in corporate environments....
Entity–attribute–value model is a data model to describe entities where the number of attributes that can be used to describe them is potentially vast, but the number that will actually apply to a given entity is relatively modest. In mathematics, this model is known as a sparse matrix...
In computing, linked data describes a method of publishing structured data so that it can be interlinked and become more useful. It builds upon standard Web technologies such as HTTP and URIs, but rather than using them to serve web pages for human readers, it extends them to share information in a...
Ontology learning is a subtask of information extraction. The goal of ontology learning is to semi-automatically extract relevant concepts and relations from a given corpus or other kinds of data sets to form an ontology.The automatic creation of ontologies is a task that involves many disciplines...
Semantic advertising applies semantic technologies to online advertising solutions. The function of semantic advertising technology is to semantically analyze every web page in order to properly understand and classify the meaning of a web page and accordingly ensure that the web page contains the...
Semantic computing is a field of computing that combines elements of semantic analysis, natural language processing, data mining and related fields.Semantic computing addresses three core problems:...
The Semantic Sensor Web is an approach to annotating sensor data with spatial, temporal, and thematic semantic metadata. This technique builds on current standardization efforts within the Open Geospatial Consortium Sensor Web Enablement and extends them with Semantic Web technologies to...
Semantic Web Services, like conventional web services, are the server end of a client–server system for machine-to-machine interaction via the World Wide Web...
Smart-M3 is a name of an open source software project that aims to provide a "Semantic Web" information sharing infrastructure between software entities and devices. It combines the ideas of distributed, networked systems and semantic web...
The concept of the Social Semantic Web subsumes developments in which social interactions on the Web lead to the creation of explicit and semantically rich knowledge representations. The Social Semantic Web can be seen as a Web of collective knowledge systems, which are able to provide useful...
Website Parse Template is an XML-based open format which provides HTML structure description of website pages. WPT format allows web crawlers to generate Semantic Web’s RDFs for web pages...



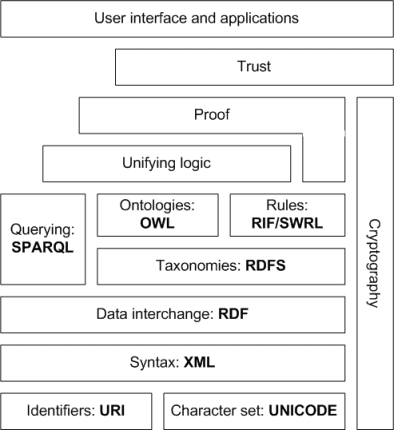 The Semantic Web StackSemantic Web StackThe Semantic Web Stack, also known as Semantic Web Cake or Semantic Web Layer Cake, illustrates the architecture of the Semantic Web.- Overview :...
The Semantic Web StackSemantic Web StackThe Semantic Web Stack, also known as Semantic Web Cake or Semantic Web Layer Cake, illustrates the architecture of the Semantic Web.- Overview :...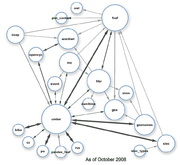 The Linking Open Data project is a W3C-led effort to create openly accessible, and interlinked, RDF Data on the Web. The data in question takes the form of RDF Data Sets drawn from a broad collection of data sources. There is a focus on the Linked DataLinked DataIn computing, linked data describes a method of publishing structured data so that it can be interlinked and become more useful. It builds upon standard Web technologies such as HTTP and URIs, but rather than using them to serve web pages for human readers, it extends them to share information in a...
The Linking Open Data project is a W3C-led effort to create openly accessible, and interlinked, RDF Data on the Web. The data in question takes the form of RDF Data Sets drawn from a broad collection of data sources. There is a focus on the Linked DataLinked DataIn computing, linked data describes a method of publishing structured data so that it can be interlinked and become more useful. It builds upon standard Web technologies such as HTTP and URIs, but rather than using them to serve web pages for human readers, it extends them to share information in a...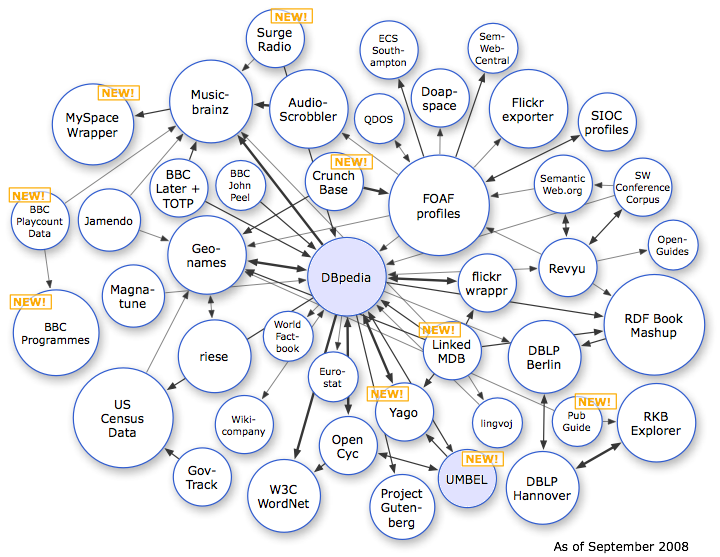{kind=link}