

BA model
Encyclopedia

Scale-free network
A scale-free network is a network whose degree distribution follows a power law, at least asymptotically. That is, the fraction P of nodes in the network having k connections to other nodes goes for large values of k as...
networks
Complex network
In the context of network theory, a complex network is a graph with non-trivial topological features—features that do not occur in simple networks such as lattices or random graphs but often occur in real graphs...
using a preferential attachment
Preferential attachment
A preferential attachment process is any of a class of processes in which some quantity, typically some form of wealth or credit, is distributed among a number of individuals or objects according to how much they already have, so that those who are already wealthy receive more than those who are not...
mechanism. Scale-free networks are widely observed in natural and man-made systems, including the Internet
Internet
The Internet is a global system of interconnected computer networks that use the standard Internet protocol suite to serve billions of users worldwide...
, the world wide web
World Wide Web
The World Wide Web is a system of interlinked hypertext documents accessed via the Internet...
, citation networks
Citation analysis
Citation analysis is the examination of the frequency, patterns, and graphs of citations in articles and books. It uses citations in scholarly works to establish links to other works or other researchers. Citation analysis is one of the most widely used methods of bibliometrics...
, and some social networks.
Concepts
Many observed networks fall into the class of scale-free networks, meaning that they have power-lawPower law
A power law is a special kind of mathematical relationship between two quantities. When the frequency of an event varies as a power of some attribute of that event , the frequency is said to follow a power law. For instance, the number of cities having a certain population size is found to vary...
(or scale-free) degree distributions, while random graph models such as the Erdős–Rényi (ER) model
Erdos–Rényi model
In graph theory, the Erdős–Rényi model, named for Paul Erdős and Alfréd Rényi, is either of two models for generating random graphs, including one that sets an edge between each pair of nodes with equal probability, independently of the other edges...
and the Watts–Strogatz (WS) model
Watts and Strogatz model
The Watts and Strogatz model is a random graph generation model that produces graphs with small-world properties, including short average path lengths and high clustering. It was proposed by Duncan J. Watts and Steven Strogatz in their joint 1998 Nature paper...
do not exhibit power laws. The Barabási–Albert model is one of several proposed models that generates scale-free networks. It incorporates two important general concepts: growth and preferential attachment
Preferential attachment
A preferential attachment process is any of a class of processes in which some quantity, typically some form of wealth or credit, is distributed among a number of individuals or objects according to how much they already have, so that those who are already wealthy receive more than those who are not...
. Both growth and preferential attachment exist widely in real networks.
Growth means that the number of nodes in the network increases over time.
Preferential attachment
Preferential attachment
A preferential attachment process is any of a class of processes in which some quantity, typically some form of wealth or credit, is distributed among a number of individuals or objects according to how much they already have, so that those who are already wealthy receive more than those who are not...
means that the more connected a node is, the more likely it is to receive new links. Nodes with higher degree
Degree (graph theory)
In graph theory, the degree of a vertex of a graph is the number of edges incident to the vertex, with loops counted twice. The degree of a vertex v is denoted \deg. The maximum degree of a graph G, denoted by Δ, and the minimum degree of a graph, denoted by δ, are the maximum and minimum degree...
have stronger ability to grab links added to the network. Intuitively, the preferential attachment can be understood if we think in terms of social networks connecting people. Here a link from A to B means that person A "knows" or "is acquainted with" person B. Heavily linked nodes represent well-known people with lots of relations. When a newcomer enters the community, s/he is more likely to become acquainted with one of those more visible people rather than with a relative unknown. Similarly, on the web, new pages link preferentially to hubs, i.e. very well known sites such as Google
Google
Google Inc. is an American multinational public corporation invested in Internet search, cloud computing, and advertising technologies. Google hosts and develops a number of Internet-based services and products, and generates profit primarily from advertising through its AdWords program...
or Wikipedia
Wikipedia
Wikipedia is a free, web-based, collaborative, multilingual encyclopedia project supported by the non-profit Wikimedia Foundation. Its 20 million articles have been written collaboratively by volunteers around the world. Almost all of its articles can be edited by anyone with access to the site,...
, rather than to pages that hardly anyone knows. If someone selects a new page to link to by randomly choosing an existing link, the probability of selecting a particular page would be proportional to its degree. This explains the preferential attachment probability rule.
Preferential attachment is an example of a positive feedback
Positive feedback
Positive feedback is a process in which the effects of a small disturbance on a system include an increase in the magnitude of the perturbation. That is, A produces more of B which in turn produces more of A. In contrast, a system that responds to a perturbation in a way that reduces its effect is...
cycle where initially random variations (one node initially having more links or having started accumulating links earlier than another) are automatically reinforced, thus greatly magnifying differences. This is also sometimes called the Matthew effect
Matthew effect
The Matthew effect may refer to:* Matthew effect , the phenomenon in sociology where "the rich get richer and the poor get poorer"* Matthew effect , the phenomenon in education that has been observed in research on how new readers acquire the skills to read...
, "the rich get richer", and in chemistry autocatalysis
Autocatalysis
A single chemical reaction is said to have undergone autocatalysis, or be autocatalytic, if the reaction product itself is the catalyst for that reaction....
.
Algorithm
The network begins with an initial network of m0 nodes. m0 ≥ 2 and the degree of each node in the initial network should be at least 1, otherwise it will always remain disconnected from the rest of the network.New nodes are added to the network one at a time. Each new node is connected to
 existing nodes with a probability that is proportional to the number of links that the existing nodes already have. Formally, the probability pi that the new node is connected to node i is
existing nodes with a probability that is proportional to the number of links that the existing nodes already have. Formally, the probability pi that the new node is connected to node i is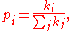
where ki is the degree of node i. Heavily linked nodes ("hubs") tend to quickly accumulate even more links, while nodes with only a few links are unlikely to be chosen as the destination for a new link. The new nodes have a "preference" to attach themselves to the already heavily linked nodes.
Degree distribution
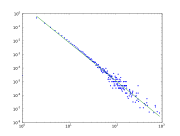

Average path length
The average path lengthAverage path length
Average path length is a concept in network topology that is defined as the average number of steps along the shortest paths for all possible pairs of network nodes...
of the BA model increases approximately logarithmically with the size of the network. The actual form has a double logarithmic correction and goes as
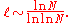
The BA model has a systematically shorter average path length than a random graph.
Node degree correlations
Correlations between the degrees of connected nodes develop spontaneously in the BA model because of the way the network evolves. The probability,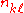 , of finding a link between nodes of degrees
, of finding a link between nodes of degrees 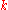 and
and 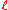 in the BA model is given by
in the BA model is given by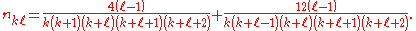
This is certainly not the result expected if the distributions were uncorrelated,
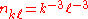
Clustering coefficient
While there is no analytical result for the clustering coefficientClustering coefficient
In graph theory, a clustering coefficient is a measure of degree to which nodes in a graph tend to cluster together. Evidence suggests that in most real-world networks, and in particular social networks, nodes tend to create tightly knit groups characterised by a relatively high density of ties...
of the BA model, the empirically determined clustering coefficients are generally significantly higher for the BA model than for random networks. The clustering coefficient also scales with network size following approximately a power law
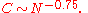
This behavior is still distinct from the behavior of small world networks where clustering is independent of system size.
In the case of hierarchical networks, clustering as a function of node degree also follows a power-law,
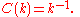
This result was obtained analytically by Dorogovtsev, Goltsev and Mendes.
Spectral properties
The spectral density of BA model has a different shape from the semicircular spectral density of random graph. It has a triangle-like shape with the top lying well above the semicircle and edges decaying as a power law.Model A
Model A retains growth but does not include preferential attachment. The probability of a new node connecting to any pre-existing node is equal. The resulting degree distribution in this limit is exponential, indicating that growth alone is not sufficient to produce a scale-free structure.Model B
Model B retains preferential attachment but eliminates growth. The model begins with a fixed number of disconnected nodes and adds links, preferentially choosing high degree nodes as link destinations. Though the degree distribution early in the simulation looks scale-free, the distribution is not stable, and it eventually becomes nearly Gaussian as the network nears saturation. So preferential attachment alone is not sufficient to produce a scale-free structure.The failure of models A and B to lead to a scale-free distribution indicates that growth and preferential attachment are needed simultaneously to reproduce the stationary power-law distribution observed in real networks.
History
The first use of a preferential attachment mechanism to explain power-law distributions appears to have been by YuleUdny Yule
George Udny Yule FRS , usually known as Udny Yule, was a British statistician, born at Beech Hill, a house in Morham near Haddington, Scotland and died in Cambridge, England. His father, also George Udny Yule, and a nephew, were knighted. His uncle was the noted orientalist Sir Henry Yule...
in 1925, although Yule's mathematical treatment is opaque by modern standards because of the lack of appropriate tools for analyzing stochastic processes. The modern master equation method, which yields a more transparent derivation, was applied to the problem by Herbert Simon
Herbert Simon
Herbert Alexander Simon was an American political scientist, economist, sociologist, and psychologist, and professor—most notably at Carnegie Mellon University—whose research ranged across the fields of cognitive psychology, cognitive science, computer science, public administration, economics,...
in 1955 in the course of studies of the sizes of cities and other phenomena. It was first applied to the growth of networks by Derek de Solla Price
Derek J. de Solla Price
Derek John de Solla Price was a physicist, historian of science, and information scientist,credited as the father of scientometrics.-Biography:...
in 1976
who was interested in the networks of citation between scientific papers. The name "preferential attachment" and the present popularity of scale-free network models is due to the work of Albert-László Barabási
Albert-Laszlo Barabasi
Albert-László Barabási is a physicist, best known for his work in the research of network theory. He is the former Emil T...
and Réka Albert, who rediscovered the process independently in 1999 and applied it to degree distributions on the web.