Computer science or computing science is the study of the theoretical foundations of information and computation and of practical techniques for their implementation and application in computer systems...
A comparison sort is a type of sorting algorithm that only reads the list elements through a single abstract comparison operation that determines which of two elements should occur first in the final sorted list...
In computer science, integer sorting is the algorithmic problem of sorting a collection of data values by numeric keys, each of which is an integer. Algorithms designed for integer sorting may also often be applied to sorting problems in which the keys are floating point numbers or text strings...
In computer science, a sorting algorithm is an algorithm that puts elements of a list in a certain order. The most-used orders are numerical order and lexicographical order...
that sorts data with integer keys by grouping keys by the individual digits which share the same significant
Significant figures
The significant figures of a number are those digits that carry meaning contributing to its precision. This includes all digits except:...
Positional notation or place-value notation is a method of representing or encoding numbers. Positional notation is distinguished from other notations for its use of the same symbol for the different orders of magnitude...
is required, but because integers can represent strings of characters (e.g., names or dates) and specially formatted floating point numbers, radix sort is not limited to integers. Radix sort dates back as far as 1887 to the work of Herman Hollerith
Herman Hollerith
Herman Hollerith was an American statistician who developed a mechanical tabulator based on punched cards to rapidly tabulate statistics from millions of pieces of data. He was the founder of one of the companies that later merged and became IBM.-Personal life:Hollerith was born in Buffalo, New...
on tabulating machines.
Most digital computers internally represent all of their data as electronic representations of binary numbers, so processing the digits of integer representations by groups of binary digit representations is most convenient. Two classifications of radix sorts are least significant digit (LSD) radix sorts and most significant digit (MSD) radix sorts. LSD radix sorts process the integer representations starting from the least significant digit and move towards the most significant digit. MSD radix sorts work the other way around.
The integer representations that are processed by sorting algorithms are often called "keys", which can exist all by themselves or be associated with other data. LSD radix sorts typically use the following sorting order: short keys come before longer keys, and keys of the same length are sorted lexicographically. This coincides with the normal order of integer representations, such as the sequence 1, 2, 3, 4, 5, 6, 7, 8, 9, 10. MSD radix sorts use lexicographic order, which is suitable for sorting strings, such as words, or fixed-length integer representations. A sequence such as "b, c, d, e, f, g, h, i, j, ba" would be lexicographically sorted as "b, ba, c, d, e, f, g, h, i, j". If lexicographic ordering is used to sort variable-length integer representations, then the representations of the numbers from 1 to 10 would be output as 1, 10, 2, 3, 4, 5, 6, 7, 8, 9, as if the shorter keys were left-justified and padded on the right with blank characters to make the shorter keys as long as the longest key for the purpose of determining sorted order.
Efficiency
Radix sort's efficiency is O(k·n) for n keys which have k or fewer digits. Note that this is not necessarily better than O(n·log(n)) when n is sufficiently small.
Least significant digit radix sorts
A least significant digit (LSD) radix sort is a fast stable sorting algorithm
Sorting algorithm
In computer science, a sorting algorithm is an algorithm that puts elements of a list in a certain order. The most-used orders are numerical order and lexicographical order...
which can be used to sort keys in integer representation order. Keys may be a string
String (computer science)
In formal languages, which are used in mathematical logic and theoretical computer science, a string is a finite sequence of symbols that are chosen from a set or alphabet....
of characters, or numerical digits in a given 'radix'. The processing of the keys begins at the least significant digit (i.e., the rightmost digit), and proceeds to the most significant digit (i.e., the leftmost digit). The sequence in which digits are processed by a LSD radix sort is the opposite of the sequence in which digits are processed by a most significant digit (MSD) radix sort.
In mathematics, big O notation is used to describe the limiting behavior of a function when the argument tends towards a particular value or infinity, usually in terms of simpler functions. It is a member of a larger family of notations that is called Landau notation, Bachmann-Landau notation, or...
(nk) time, where n is the number of keys, and k is the average key length. This kind of performance for variable-length keys can be achieved by grouping all of the keys that have the same length together and separately performing an LSD radix sort on each group of keys for each length, from shortest to longest, in order to avoid processing the whole list of keys on every sorting pass.
A radix sorting algorithm was originally used to sort punched card
Punched card
A punched card, punch card, IBM card, or Hollerith card is a piece of stiff paper that contains digital information represented by the presence or absence of holes in predefined positions...
s in several passes. A computer algorithm was invented for radix sort in 1954 at MIT
Massachusetts Institute of Technology
The Massachusetts Institute of Technology is a private research university located in Cambridge, Massachusetts. MIT has five schools and one college, containing a total of 32 academic departments, with a strong emphasis on scientific and technological education and research.Founded in 1861 in...
Harold H. Seward is a computer scientist and the developer of the radix sort algorithm in 1954 at MIT. He also developed the counting sort.-References:...
. In many large applications needing speed, the computer radix sort is an improvement on (slower) comparison sorts.
A comparison sort is a type of sorting algorithm that only reads the list elements through a single abstract comparison operation that determines which of two elements should occur first in the final sorted list...
Heapsort is a comparison-based sorting algorithm to create a sorted array , and is part of the selection sort family. Although somewhat slower in practice on most machines than a well implemented quicksort, it has the advantage of a more favorable worst-case O runtime...
and mergesort) that require Ω(n · log n) comparisons, where n is the number of items to be sorted. Comparison sort
Comparison sort
A comparison sort is a type of sorting algorithm that only reads the list elements through a single abstract comparison operation that determines which of two elements should occur first in the final sorted list...
s can do no better than Ω(n · log n) execution time but offer the flexibility of being able to sort with respect to more complicated orderings than a lexicographic one; however, this ability is of little importance in many practical applications.
Definition
Each key is first figuratively dropped into one level of buckets corresponding to the value of the rightmost digit. Each bucket preserves the original order of the keys as the keys are dropped into the bucket. There is a one-to-one correspondence between the number of buckets and the number of values that can be represented by a digit. Then, the process repeats with the next neighboring digit until there are no more digits to process. In other words:
Take the least significant digit (or group of bits, both being examples of radices
Radix
In mathematical numeral systems, the base or radix for the simplest case is the number of unique digits, including zero, that a positional numeral system uses to represent numbers. For example, for the decimal system the radix is ten, because it uses the ten digits from 0 through 9.In any numeral...
) of each key.
Group the keys based on that digit, but otherwise keep the original order of keys. (This is what makes the LSD radix sort a stable sort).
Repeat the grouping process with each more significant digit.
The sort in step 2 is usually done using bucket sort
Bucket sort
Bucket sort, or bin sort, is a sorting algorithm that works by partitioning an array into a number of buckets. Each bucket is then sorted individually, either using a different sorting algorithm, or by recursively applying the bucket sorting algorithm. It is a distribution sort, and is a cousin of...
In computer science, counting sort is an algorithm for sorting a collection of objects according to keys that are small integers; that is, it is an integer sorting algorithm. It operates by counting the number of objects that have each distinct key value, and using arithmetic on those counts to...
, which are efficient in this case since there are usually only a small number of digits.
An example
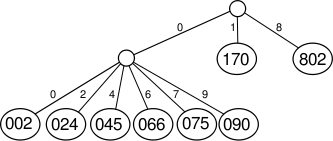
Original, unsorted list:
170, 45, 75, 90, 802, 24, 2, 66
Sorting by least significant digit (1s place) gives:
170, 90, 802, 2, 24, 45, 75, 66
Notice that we keep 802 before 2, because 802 occurred before 2 in the original list, and similarly for pairs 170 & 90 and 45 & 75. Sorting by next digit (10s place) gives:
802, 2, 24, 45, 66, 170, 75, 90
Sorting by most significant digit (100s place) gives:
2, 24, 45, 66, 75, 90, 170, 802
It is important to realize that each of the above steps requires just a single pass over the data, since each item can be placed in its correct bucket without having to be compared with other items.
Some LSD radix sort implementations allocate space for buckets by first counting the number of keys that belong in each bucket before moving keys into those buckets. The number of times that each digit occurs is stored in an array
Array data type
In computer science, an array type is a data type that is meant to describe a collection of elements , each selected by one or more indices that can be computed at run time by the program. Such a collection is usually called an array variable, array value, or simply array...
. Consider the previous list of keys viewed in a different way:
170, 045, 075,090, 002, 024, 802, 066
The first counting pass starts on the least significant digit of each key, producing an array of bucket sizes:
2 (bucket size for digits of 0: 170, 090)
2 (bucket size for digits of 2: 002, 802)
1 (bucket size for digits of 4: 024)
2 (bucket size for digits of 5: 045, 075)
1 (bucket size for digits of 6: 066)
A second counting pass on the next more significant digit of each key will produce an array of bucket sizes:
2 (bucket size for digits of 0: 002, 802)
1 (bucket size for digits of 2: 024)
1 (bucket size for digits of 4: 045)
1 (bucket size for digits of 6: 066)
2 (bucket size for digits of 7: 170, 075)
1 (bucket size for digits of 9: 090)
A third and final counting pass on the most significant digit of each key will produce an array of bucket sizes:
6 (bucket size for digits of 0: 002, 024, 045, 066, 075, 090)
1 (bucket size for digits of 1: 170)
1 (bucket size for digits of 8: 802)
At least one LSD radix sort implementation now counts the number of times that each digit occurs in each column for all columns in a single counting pass. (See the external links section.) Other LSD radix sort implementations allocate space for buckets dynamically as the space is needed.
Iterative version using queues
A simple version of an LSD radix sort can be achieved using queues as buckets.
The following process is repeated for a number of times equal to the length of the longest key:
The integers are enqueued into an array of ten separate queues based on their digits from right to left. Computers often represent integers internally as fixed-length binary digits. Here, we will do something analogous with fixed-length decimal digits. So, using the numbers from the previous example, the queues for the 1st pass would be:
0: 170, 090
1: none
2: 002, 802
3: none
4: 024
5: 045, 075
6: 066
7–9: none
The queues are dequeued back into an array of integers, in increasing order. Using the same numbers, the array will look like this after the first pass:
170, 090, 002, 802, 024, 045, 075, 066
For the second pass:
Queues:
0: 002, 802
1: none
2: 024
3: none
4: 045
5: none
6: 066
7: 170, 075
8: none
9: 090
Array:
002, 802, 024, 045, 066, 170, 075, 090 (note that at this point only 802 and 170 are out of order)
For the third pass:
Queues:
0: 002, 024, 045, 066, 075, 090
1: 170
2–7: none
8: 802
9: none
Array:
002, 024, 045, 066, 075, 090, 170, 802 (sorted)
While this may not be the most efficient radix sort algorithm, it is relatively simple, and still quite efficient.
Example in C++
include
include
include
using namespace std;
void printSorted(int x[], int length);
vector < vector > buckets;
void radixSort(int x[],int length)
{
int temp;
int m=0;
int max=x[0];
// storing maximum of the array in max variable
for(int i=0; i< length; i++)
if(max < x[i])
max = x[i];
// the obtained maximum is decides the number of times the for loop below iterates
//Begin Radix Sort
for(int i=0; max!=0; max=max/10,i++)
{
//Determine which bucket each element should enter
for(int j=0;j
{
temp=(int)((x[j])/pow(10,i))%10;
buckets[temp].push_back((x[j]));
}
//Transfer results of buckets back into main array
for(int k=0;k<10;k++)
{
for(int l=0;l
{
x[m]=buckets[k][l];
m++;
}
//Clear previous bucket
buckets[k].clear;
}
m=0;
}
buckets.clear;
printSorted(x,length);
cout<<"\nAbove is the sorted list.\n";
cout<<"Enter any character or number to exit!!\n";
cin>>temp;
}
void printSorted(int x[], int length){
cout<<"Sorted List :: \n";
for(int i=0;i
cout<
}
int main{
int total_number_of_elements;
cout<<"Enter total Number of Elements to be entered\n";
cin>>total_number_of_elements;
int input[total_number_of_elements];
buckets.resize(10);
int number;
for(int i=0;i
{
cout<<"Enter "<
cin>>number;
input[i]=number;
}
radixSort(input,total_number_of_elements);
return 0;
}
Example in Python
This example written in the Python programming language will perform the radix sort for any radix (base) of 2 or greater. Simplicity of exposition is chosen over clever programming, and so the log function is used instead of bit shifting techniques.
python2.6 <
from math import log
def getDigit(num, base, digit_num):
# pulls the selected digit
return (num // base ** digit_num) % base
def makeBlanks(size):
# create a list of empty lists to hold the split by digit
return [ [] for i in range(size) ]
def split(a_list, base, digit_num):
buckets = makeBlanks(base)
for num in a_list:
# append the number to the list selected by the digit
buckets[getDigit(num, base, digit_num)].append(num)
return buckets
concatenate the lists back in order for the next step
def merge(a_list):
new_list = []
for sublist in a_list:
new_list.extend(sublist)
return new_list
def maxAbs(a_list):
# largest abs value element of a list
return max(abs(num) for num in a_list)
def radixSort(a_list, base):
# there are as many passes as there are digits in the longest number
passes = int(log(maxAbs(a_list), base) + 1)
new_list = list(a_list)
for digit_num in range(passes):
new_list = merge(split(new_list, base, digit_num))
return new_list
Most significant digit radix sorts
A most significant digit (MSD) radix sort can be used to sort keys in lexicographic order. Unlike a least significant digit (LSD) radix sort, a most significant digit radix sort does not necessarily preserve the original order of duplicate keys. A MSD radix sort starts processing the keys from the most significant digit, leftmost digit, to the least significant digit, rightmost digit. This sequence is opposite that of least significant digit (LSD) radix sorts. An MSD radix sort stops rearranging the position of a key when the processing reaches a unique prefix of the key. Some MSD radix sorts use one level of buckets in which to group the keys. See the counting sort
Counting sort
In computer science, counting sort is an algorithm for sorting a collection of objects according to keys that are small integers; that is, it is an integer sorting algorithm. It operates by counting the number of objects that have each distinct key value, and using arithmetic on those counts to...
Pigeonhole sorting, also known as count sort , is a sorting algorithm that is suitable for sorting lists of elements where the number of elements and the number of possible key values are approximately the same...
articles. Other MSD radix sorts use multiple levels of buckets, which form a trie
Trie
In computer science, a trie, or prefix tree, is an ordered tree data structure that is used to store an associative array where the keys are usually strings. Unlike a binary search tree, no node in the tree stores the key associated with that node; instead, its position in the tree defines the...
or a path in a trie. A postman's sort / postal sort is a kind of MSD radix sort.
Recursion is the process of repeating items in a self-similar way. For instance, when the surfaces of two mirrors are exactly parallel with each other the nested images that occur are a form of infinite recursion. The term has a variety of meanings specific to a variety of disciplines ranging from...
subdividing MSD radix sort algorithm works as follows:
Take the most significant digit of each key.
Sort the list of elements based on that digit, grouping elements with the same digit into one bucket
Bucket (computing)
In computing, the term bucket can have several meanings. It is used both as a live metaphor, and as a generally accepted technical term in some specialised areas. A bucket is most commonly a type of data buffer or a type of document in which data is divided into regions.-Features of a...
.
Recursively sort each bucket, starting with the next digit to the right.
Concatenate the buckets together in order.
Implementation
A two-pass method can be used to first find out how big each bucket needs to be and then place each key (or pointer to the key) into the appropriate bucket. A single-pass system can also be used, where each bucket is dynamically allocated and resized as needed, but this runs the risk of serious memory fragmentation, discontiguous allocations of memory, which may degrade performance. This memory fragmentation could be avoided if a fixed allocation of buckets is used for all possible values of a digit, but, for an 8-bit digit, this would require 256 (28) buckets, even if not all of the buckets were used. So, this approach might use up all available memory quickly and go into paging space, where data is stored and accessed on a hard drive or some other secondary memory device instead of main memory, which would radically degrade performance. A fixed allocation approach would only make sense if each digit was very small, such as a single bit.
Recursive forward radix sort example
Sort the list:
170, 045, 075, 090, 002, 024, 802, 066
Sorting by most significant digit (100s place) gives: Zero hundreds bucket: 045, 075, 090, 002, 024, 066 One hundreds bucket: 170 Eight hundreds bucket: 802
Sorting by next digit (10s place) is only needed for those numbers in the zero hundreds bucket (no other buckets contain more than one item): Zero tens bucket: 002 Twenties bucket: 024 Forties bucket: 045 Sixties bucket: 066 Seventies bucket: 075 Nineties bucket: 090
Sorting by least significant digit (1s place) is not needed, as there is no tens bucket with more than one number. Therefore, the now sorted zero hundreds bucket is concatenated, joined in sequence, with the one hundreds bucket and eight hundreds bucket to give: 002, 024, 045, 066, 075, 090, 170, 802
This example used base ten digits for the sake of readability, but of course binary digits or perhaps byte
Byte
The byte is a unit of digital information in computing and telecommunications that most commonly consists of eight bits. Historically, a byte was the number of bits used to encode a single character of text in a computer and for this reason it is the basic addressable element in many computer...
s might make more sense for a binary computer to process.
In-place MSD radix sort implementations
Binary MSD radix sort, also called binary quicksort, can be implemented in-place by splitting the input array into two bins - the 0's bin and the 1's bin. The 0's bin is grown from the beginning of the array, whereas the 1's bin is grown from the end of the array. The 0's bin boundary is placed before the first array element. The 1's bin boundary is placed after the last array element. The most significant bit of the first array element is examined. If this bit is a 1, then the first element is swapped with the element in front of the 1's bin boundary (the last element of the array), and the 1's bin is grown by one element by decrementing the 1's boundary array index. If this bit is a 0, then the first element remains at its current location, and the 0's bin is grown by one element. The next array element examined is the one in front of the 0's bin boundary (i.e. the first element that is not in the 0's bin or the 1's bin). This process continues until the 0's bin and the 1's bin reach each other. The 0's bin and the 1's bin are then sorted recursively based on the next bit of each array element. Recursive processing continues until the least significant bit has been used for sorting. Handling signed integers requires treating the most significant bit with the opposite sense, followed by unsigned treatment of the rest of the bits.
In-place MSD binary-radix sort can be extended to larger radix and retain in-place capability. Counting sort
Counting sort
In computer science, counting sort is an algorithm for sorting a collection of objects according to keys that are small integers; that is, it is an integer sorting algorithm. It operates by counting the number of objects that have each distinct key value, and using arithmetic on those counts to...
is used to determine the size of each bin and their starting index. Swapping is used to place the current element into its bin, followed by expanding the bin boundary. As the array elements are scanned the bins are skipped over and only elements between bins are processed, until the entire array has been processed and all elements end up in their respective bins. The number of bins is the same as the radix used - e.g. 16 bins for 16-Radix. Each pass is based on a single digit (e.g. 4-bits per digit in the case of 16-Radix), starting from the most significant digit. Each bin is then processed recursively using the next digit, until all digits have been used for sorting.
In-place binary-radix sort and n-bit-radix sort discussed in paragraphs above are both not stable algorithms
Sorting algorithm
In computer science, a sorting algorithm is an algorithm that puts elements of a list in a certain order. The most-used orders are numerical order and lexicographical order...
.
Stable MSD radix sort implementations
MSD Radix Sort can be implemented as a stable algorithm, but requires the use of a memory buffer of the same size as the input array. This extra memory allows the input buffer to be scanned from the first array element to last, and move the array elements to the destination bins in the same order. Thus, equal elements will be placed in the memory buffer in the same order they were in the input array. The MSD-based algorithm uses the extra memory buffer as the output on the first level of recursion, but swaps the input and output on the next level of recursion, to avoid the overhead of copying the output result back to the input buffer. Each of the bins are recursively processed, as is done for the in-place MSD Radix Sort. After the sort by the last digit has been completed, the output buffer is checked to see if it is the original input array, and if it's not, then a single copy is performed. If the digit size is chosen such that the key size divided by the digit size is an even number, the copy at the end is avoided.
Hybrid approaches
Radix sort, such as two pass method where Counting sort
Counting sort
In computer science, counting sort is an algorithm for sorting a collection of objects according to keys that are small integers; that is, it is an integer sorting algorithm. It operates by counting the number of objects that have each distinct key value, and using arithmetic on those counts to...
is used during the first pass of each level of recursion, has a large constant overhead. Thus, when the bins get small, other sorting algorithms should be used, such as Insertion sort
Insertion sort
Insertion sort is a simple sorting algorithm: a comparison sort in which the sorted array is built one entry at a time. It is much less efficient on large lists than more advanced algorithms such as quicksort, heapsort, or merge sort...
Insertion sort is a simple sorting algorithm: a comparison sort in which the sorted array is built one entry at a time. It is much less efficient on large lists than more advanced algorithms such as quicksort, heapsort, or merge sort...
is fast for small arrays, stable, in-place, and can significantly speed up Radix Sort.
Application to parallel computing
Note that this recursive sorting algorithm has particular application to parallel computing
Parallel computing
Parallel computing is a form of computation in which many calculations are carried out simultaneously, operating on the principle that large problems can often be divided into smaller ones, which are then solved concurrently . There are several different forms of parallel computing: bit-level,...
, as each of the bins can be sorted independently. In this case, each bin is passed to the next available processor. A single processor would be used at the start (the most significant digit). Then, by the second or third digit, all available processors would likely be engaged. Ideally, as each subdivision is fully sorted, fewer and fewer processors would be utilized. In the worst case, all of the keys will be identical or nearly identical to each other, with the result that there will be little to no advantage to using parallel computing to sort the keys.
In the top level of recursion, opportunity for parallelism is in the Counting sort
Counting sort
In computer science, counting sort is an algorithm for sorting a collection of objects according to keys that are small integers; that is, it is an integer sorting algorithm. It operates by counting the number of objects that have each distinct key value, and using arithmetic on those counts to...
portion of the algorithm. Counting is highly parallel, amenable to the parallel_reduce pattern, and splits the work well across multiple cores until reaching memory bandwidth limit. This portion of the algorithm has data-independent parallelism. Processing each bin in subsequent recursion levels is data-dependent, however. For example, if all keys were of the same value, then there would be only a single bin with any elements in it, and no parallelism would be available. For random inputs all bins would be near equally populated and a large amount of parallelism opportunity would be available.
Note that there are faster sorting algorithms available, for example optimal complexity O(log(n)) are those of the Three Hungarians and Richard Cole and Batcher's bitonic mergesort has an algorithmic complexity of O(log2(n)), all of which have a lower algorithmic time complexity to radix sort on a CREW-PRAM
Parallel Random Access Machine
In computer science, Parallel Random Access Machine is a shared memory abstract machine. As its name indicates, the PRAM was intended as the parallel computing analogy to the random access machine...
In computer science, Parallel Random Access Machine is a shared memory abstract machine. As its name indicates, the PRAM was intended as the parallel computing analogy to the random access machine...
sorts were described in 1991 by David Powers with a parallelized quicksort that can operate in O(log(n)) time on a CRCW-PRAM
Parallel Random Access Machine
In computer science, Parallel Random Access Machine is a shared memory abstract machine. As its name indicates, the PRAM was intended as the parallel computing analogy to the random access machine...
with n processors by performing partitioning implicitly, as well as a radixsort that operates using the same trick in O(k), where k is the maximum keylength. However, neither the PRAM
Parallel Random Access Machine
In computer science, Parallel Random Access Machine is a shared memory abstract machine. As its name indicates, the PRAM was intended as the parallel computing analogy to the random access machine...
architecture or a single sequential processor can actually be built in a way that will scale without the number of constant fanout
Fanout
In digital electronics, the fan-out of a logic gate output is the number of gate inputs to which it is connected.In most designs, logic gates are connected together to form more complex circuits. While no more than one logic gate output is connected to any single input, it is common for one output...
gate delays per cycle increasing as O(log(n)), so that in effect a pipelined version of Batcher's bitonic mergesort and the O(log(n)) PRAM
Parallel Random Access Machine
In computer science, Parallel Random Access Machine is a shared memory abstract machine. As its name indicates, the PRAM was intended as the parallel computing analogy to the random access machine...
sorts are all O(log2(n)) in terms of clock cycles, with Powers acknowledging that Batcher's would have lower constant in terms of gate delays than his Parallel Quicksort and Radixsort, or Cole's Mergesort
Merge sort
Merge sort is an O comparison-based sorting algorithm. Most implementations produce a stable sort, meaning that the implementation preserves the input order of equal elements in the sorted output. It is a divide and conquer algorithm...
A sorting network is an abstract mathematical model of a network of wires and comparator modules that is used to sort a sequence of numbers. Each comparator connects two wires and sorts the values by outputting the smaller value to one wire, and the larger to the other...
of O(nlog2(n)).
Incremental trie-based radix sort
Another way to proceed with an MSD radix sort is to use more memory to create a trie
Trie
In computer science, a trie, or prefix tree, is an ordered tree data structure that is used to store an associative array where the keys are usually strings. Unlike a binary search tree, no node in the tree stores the key associated with that node; instead, its position in the tree defines the...
to represent the keys and then traverse the trie to visit each key in order. A depth-first traversal
Depth-first search
Depth-first search is an algorithm for traversing or searching a tree, tree structure, or graph. One starts at the root and explores as far as possible along each branch before backtracking....
of a trie starting from the root node will visit each key in order. A depth-first traversal of a trie, or any other kind of acyclic
Directed acyclic graph
In mathematics and computer science, a directed acyclic graph , is a directed graph with no directed cycles. That is, it is formed by a collection of vertices and directed edges, each edge connecting one vertex to another, such that there is no way to start at some vertex v and follow a sequence of...
tree structure, is equivalent to traversing a maze via the right-hand rule.
A trie essentially represents a set of strings or numbers, and a radix sort which uses a trie structure is not necessarily stable, which means that the original order of duplicate keys is not necessarily preserved, because a set does not contain duplicate elements. Additional information will have to be associated with each key to indicate the population count or original order of any duplicate keys in a trie-based radix sort if keeping track of that information is important for a particular application. It may even be desirable to discard any duplicate strings as the trie creation proceeds if the goal is to find only unique strings in sorted order. Some people sort a list of strings first and then make a separate pass through the sorted list to discard duplicate strings, which can be slower than using a trie to simultaneously sort and discard duplicate strings in one pass.
One of the advantages of maintaining the trie structure is that the trie makes it possible to determine quickly if a particular key is a member of the set of keys in a time that is proportional to the length of the key, k, in O(k) time, that is independent of the total number of keys. Determining set membership in a plain list, as opposed to determining set membership in a trie, requires binary search, O(k log(n)) time; linear search
Linear search
In computer science, linear search or sequential search is a method for finding a particular value in a list, that consists of checking every one of its elements, one at a time and in sequence, until the desired one is found....
, O(kn) time; or some other method whose execution time is in some way dependent on the total number, n, of all of the keys in the worst case. It is sometimes possible to determine set membership in a plain list in O(k) time, in a time that is independent of the total number of keys, such as when the list is known to be in an arithmetic sequence or some other computable sequence.
Maintaining the trie structure also makes it possible to insert new keys into the set incrementally or delete keys from the set incrementally while maintaining sorted order in O(k) time, in a time that is independent of the total number of keys. In contrast, other radix sorting algorithms must, in the worst case, re-sort the entire list of keys each time that a new key is added or deleted from an existing list, requiring O(kn) time.
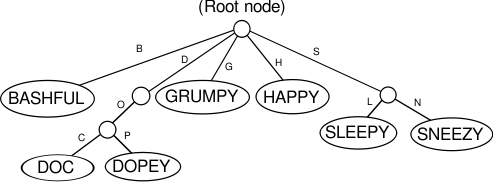
Snow White analogy
If the nodes were rooms connected by hallways, then here is how Snow White might proceed to visit all of the dwarfs if the place were dark, keeping her right hand on a wall at all times:
She travels down hall B to find Bashful.
She continues moving forward with her right hand on the wall, which takes her around the room and back up hall B.
She moves down halls D, O, and C to find Doc.
Continuing to follow the wall with her right hand, she goes back up hall C, then down hall P, where she finds Dopey.
She continues back up halls P, O, D, and then goes down hall G to find Grumpy.
She goes back up hall G, with her right hand still on the wall, and goes down hall H to the room where Happy is.
She travels back up hall H and turns right down halls S and L, where she finds Sleepy.
She goes back up hall L, down hall N, where she finally finds Sneezy.
She travels back up halls N and S to her starting point and knows that she is done.
These series of steps serve to illustrate the path taken in the trie by Snow White via a depth-first traversal
Depth-first search
Depth-first search is an algorithm for traversing or searching a tree, tree structure, or graph. One starts at the root and explores as far as possible along each branch before backtracking....
to visit the dwarfs by the ascending order of their names, Bashful, Doc, Dopey, Grumpy, Happy, Sleepy, and Sneezy. The algorithm for performing some operation on the data associated with each node of a tree first, such as printing the data, and then moving deeper into the tree is called a pre-order traversal, which is a kind of depth-first traversal
Depth-first search
Depth-first search is an algorithm for traversing or searching a tree, tree structure, or graph. One starts at the root and explores as far as possible along each branch before backtracking....
. A pre-order traversal is used to process the contents of a trie in ascending order. If Snow White wanted to visit the dwarfs by the descending order of their names, then she could walk backwards while following the wall with her right hand, or, alternatively, walk forward while following the wall with her left hand. The algorithm for moving deeper into a tree first until no further descent to unvisited nodes is possible and then performing some operation on the data associated with each node is called post-order traversal, which is another kind of depth-first traversal. A post-order traversal is used to process the contents of a trie in descending order.
In computer science, a trie, or prefix tree, is an ordered tree data structure that is used to store an associative array where the keys are usually strings. Unlike a binary search tree, no node in the tree stores the key associated with that node; instead, its position in the tree defines the...
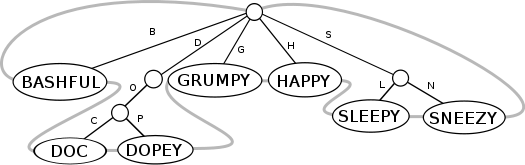
in the diagram essentially represents a null string, an empty string, which can be useful for keeping track of the number of blank lines in a list of words. The null string can be associated with a circularly linked list
Linked list
In computer science, a linked list is a data structure consisting of a group of nodes which together represent a sequence. Under the simplest form, each node is composed of a datum and a reference to the next node in the sequence; more complex variants add additional links...
with the null string initially as its only member, with the forward and backward pointers both initially pointing to the null string. The circularly linked list can then be expanded as each new key is inserted into the trie
Trie
In computer science, a trie, or prefix tree, is an ordered tree data structure that is used to store an associative array where the keys are usually strings. Unlike a binary search tree, no node in the tree stores the key associated with that node; instead, its position in the tree defines the...
. The circularly linked list is represented in the following diagram as thick, grey, horizontally linked lines:
If a new key, other than the null string, is inserted into a leaf node of the trie
Trie
In computer science, a trie, or prefix tree, is an ordered tree data structure that is used to store an associative array where the keys are usually strings. Unlike a binary search tree, no node in the tree stores the key associated with that node; instead, its position in the tree defines the...
, then the computer can go to the last preceding node where there was a key or a bifurcation to perform a depth-first search
Depth-first search
Depth-first search is an algorithm for traversing or searching a tree, tree structure, or graph. One starts at the root and explores as far as possible along each branch before backtracking....
to find the lexicographic successor or predecessor of the inserted key for the purpose of splicing the new key into the circularly linked list
Linked list
In computer science, a linked list is a data structure consisting of a group of nodes which together represent a sequence. Under the simplest form, each node is composed of a datum and a reference to the next node in the sequence; more complex variants add additional links...
. The last preceding node where there was a key or a bifurcation, a fork in the path, is a parent node in the type of trie shown here, where only unique string prefixes are represented as paths in the trie. If there is already a key associated with the parent node that would have been visited during a movement away from the root during a right-hand, forward-moving, depth-first traversal, then that immediately ends the depth-first search, as that key is the predecessor of the inserted key. For example, if Bashful is inserted into the trie, then the predecessor is the null string in the parent node, which is the root node in this case. In other words, if the key that is being inserted is on the leftmost branch of the parent node, then any string contained in the parent node is the lexicographic predecessor of the key that is being inserted, else the lexicographic predecessor of the key that is being inserted exists down the parent node's branch that is immediately to the left of the branch where the new key is being inserted. For example, if Grumpy were the last key inserted into the trie, then the computer would have a choice of trying to find either the predecessor, Dopey, or the successor, Happy, with a depth-first search
Depth-first search
Depth-first search is an algorithm for traversing or searching a tree, tree structure, or graph. One starts at the root and explores as far as possible along each branch before backtracking....
starting from the parent node of Grumpy. With no additional information to indicate which path is longer, the computer might traverse the longer path, D, O, P. If Dopey were the last key inserted into the trie, then the depth-first search starting from the parent node of Dopey would soon find the predecessor, "Doc", because that would be the only choice.
If a new key is inserted into an internal node, then a depth-first search can be started from the internal node to find the lexicographic successor. For example, if the literal string "DO" were inserted in the node at the end of the path D, O, then a depth-first search could be started from that internal node to find the successor, "DOC", for the purpose of splicing the new string into the circularly linked list
Linked list
In computer science, a linked list is a data structure consisting of a group of nodes which together represent a sequence. Under the simplest form, each node is composed of a datum and a reference to the next node in the sequence; more complex variants add additional links...
.
Forming the circularly linked list requires more memory but allows the keys to be visited more directly in either ascending or descending order via a linear traversal of the linked list
Linked list
In computer science, a linked list is a data structure consisting of a group of nodes which together represent a sequence. Under the simplest form, each node is composed of a datum and a reference to the next node in the sequence; more complex variants add additional links...
Depth-first search is an algorithm for traversing or searching a tree, tree structure, or graph. One starts at the root and explores as far as possible along each branch before backtracking....
of the entire trie. This concept of a circularly linked trie structure is similar to the concept of a threaded binary tree
Threaded binary tree
A threaded binary tree defined as follows:"A binary tree is threaded by making all right child pointers that would normally be null point to the inorder successor of the node, and all left child pointers that would normally be null point to the inorder predecessor of the node."A threaded binary...
. This structure will be called a circularly threaded trie.
In computer science, a trie, or prefix tree, is an ordered tree data structure that is used to store an associative array where the keys are usually strings. Unlike a binary search tree, no node in the tree stores the key associated with that node; instead, its position in the tree defines the...
is used to sort numbers, the number representations must all be the same length unless you are willing to perform a breadth-first traversal
Breadth-first search
In graph theory, breadth-first search is a graph search algorithm that begins at the root node and explores all the neighboring nodes...
Depth-first search is an algorithm for traversing or searching a tree, tree structure, or graph. One starts at the root and explores as far as possible along each branch before backtracking....
, as in the above diagram, the number representations will always be on the leaf nodes of the trie
Trie
In computer science, a trie, or prefix tree, is an ordered tree data structure that is used to store an associative array where the keys are usually strings. Unlike a binary search tree, no node in the tree stores the key associated with that node; instead, its position in the tree defines the...
. Note how similar in concept this particular example of a trie is to the recursive forward radix sort example which involves the use of buckets instead of a trie. Performing a radix sort with the buckets is like creating a trie and then discarding the non-leaf nodes.
Bubble sort, also known as sinking sort, is a simple sorting algorithm that works by repeatedly stepping through the list to be sorted, comparing each pair of adjacent items and swapping them if they are in the wrong order. The pass through the list is repeated until no swaps are needed, which...
Merge sort is an O comparison-based sorting algorithm. Most implementations produce a stable sort, meaning that the implementation preserves the input order of equal elements in the sorted output. It is a divide and conquer algorithm...
JavaScript is a prototype-based scripting language that is dynamic, weakly typed and has first-class functions. It is a multi-paradigm language, supporting object-oriented, imperative, and functional programming styles....
IEEE 754–1985 was an industry standard for representingfloating-pointnumbers in computers, officially adopted in 1985 and superseded in 2008 byIEEE 754-2008. During its 23 years, it was the most widely used format for...
Donald Ervin Knuth is a computer scientist and Professor Emeritus at Stanford University.He is the author of the seminal multi-volume work The Art of Computer Programming. Knuth has been called the "father" of the analysis of algorithms...
. The Art of Computer Programming, Volume 3: Sorting and Searching, Third Edition. Addison-Wesley, 1997. ISBN 0-201-89685-0. Section 5.2.5: Sorting by Distribution, pp. 168–179.
Thomas H. Cormen is the co-author of Introduction to Algorithms, along with Charles Leiserson, Ron Rivest, and Cliff Stein. He is a Full Professor of computer science at Dartmouth College and currently Chair of the Dartmouth College Department of Computer Science. Between 2004 and 2008 he directed...
Charles Eric Leiserson is a computer scientist, specializing in the theory of parallel computing and distributed computing, and particularly practical applications thereof; as part of this effort, he developed the Cilk multithreaded language...
Clifford Stein, a computer scientist, is currently a professor of industrial engineering and operations research at Columbia University in New York, NY, where he also holds an appointment in the Department of Computer Science. Stein is chair of the Industrial Engineering and Operations Research...
Introduction to Algorithms is a book by Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. It is used as the textbook for algorithms courses at many universities. It is also one of the most commonly cited references for algorithms in published papers, with over 4600...
, Second Edition. MIT Press and McGraw-Hill, 2001. ISBN 0-262-03293-7. Section 8.3: Radix sort, pp. 170–173.
Efficient Trie-Based Sorting of Large Sets of Strings, by Ranjan Sinha and Justin Zobel. This paper describes a method of creating tries of buckets which figuratively burst into sub-tries when the buckets hold more than a predetermined capacity of strings, hence the name, "Burstsort".
The source of this article is wikipedia, the free encyclopedia. The text of this article is licensed under the GFDL.