

Comparison sort
Encyclopedia

Sorting algorithm
In computer science, a sorting algorithm is an algorithm that puts elements of a list in a certain order. The most-used orders are numerical order and lexicographical order...
that only reads the list elements through a single abstract comparison operation (often a "less than or equal to" operator) that determines which of two elements should occur first in the final sorted list. The only requirement is that the operator obey two of the properties of a total order
Total order
In set theory, a total order, linear order, simple order, or ordering is a binary relation on some set X. The relation is transitive, antisymmetric, and total...
:
- if a ≤ b and b ≤ c then a ≤ c (transitivity)
- for all a and b, either a ≤ b or b < a (totalness or trichotomy).
It is possible that both a ≤ b and b ≤ a; in this case either may come first in the sorted list. In a stable sort, the input order determines the sorted order in this case.
A metaphor for thinking about comparison sorts is that someone has a set of unlabelled weights and a balance scale. Their goal is to line up the weights in order by their weight without any information except that obtained by placing two weights on the scale and seeing which one is heavier (or if they weigh the same).
Examples

- Quick sort
- Heap sort
- Merge sortMerge sortMerge sort is an O comparison-based sorting algorithm. Most implementations produce a stable sort, meaning that the implementation preserves the input order of equal elements in the sorted output. It is a divide and conquer algorithm...
- Intro sort
- Insertion sortInsertion sortInsertion sort is a simple sorting algorithm: a comparison sort in which the sorted array is built one entry at a time. It is much less efficient on large lists than more advanced algorithms such as quicksort, heapsort, or merge sort...
- Selection sortSelection sortSelection sort is a sorting algorithm, specifically an in-place comparison sort. It has O time complexity, making it inefficient on large lists, and generally performs worse than the similar insertion sort...
- Bubble sortBubble sortBubble sort, also known as sinking sort, is a simple sorting algorithm that works by repeatedly stepping through the list to be sorted, comparing each pair of adjacent items and swapping them if they are in the wrong order. The pass through the list is repeated until no swaps are needed, which...
- Odd-even sortOdd-even sortIn computing, an odd–even sort or odd–even transposition sort is a relatively simple sorting algorithm, developed originally for use on parallel processors with local interconnections. It is a comparison sort related to bubble sort, with which it shares many characteristics...
- Cocktail sortCocktail sortCocktail sort, also known as bidirectional bubble sort, cocktail shaker sort, shaker sort , ripple sort, shuffle sort, shuttle sort or happy hour sort, is a variation of bubble sort that is both a stable sorting algorithm and a comparison sort...
- Cycle sortCycle sortCycle sort is an in-place, unstable sorting algorithm, a comparison sort that is theoretically optimal in terms of the total number of writes to the original array, unlike any other in-place sorting algorithm...
- Merge insertion (Ford-Johnson) sort
- SmoothsortSmoothsortSmoothsort is a comparison-based sorting algorithm. It is a variation of heapsort developed by Edsger Dijkstra in 1981. Like heapsort, smoothsort's upper bound is O...
- TimsortTimsortTimsort is a hybrid sorting algorithm, derived from merge sort and insertion sort, designed to perform well on many kinds of real-world data. It was invented by Tim Peters in 2002 for use in the Python programming language. The algorithm is designed to find subsets of the data which are already...
There are many integer sorting
Integer sorting
In computer science, integer sorting is the algorithmic problem of sorting a collection of data values by numeric keys, each of which is an integer. Algorithms designed for integer sorting may also often be applied to sorting problems in which the keys are floating point numbers or text strings...
algorithms that are not comparison sorts; they include:
- Radix sortRadix sortIn computer science, radix sort is a non-comparative integer sorting algorithm that sorts data with integer keys by grouping keys by the individual digits which share the same significant position and value...
(examines individual bits of keys) - Counting sortCounting sortIn computer science, counting sort is an algorithm for sorting a collection of objects according to keys that are small integers; that is, it is an integer sorting algorithm. It operates by counting the number of objects that have each distinct key value, and using arithmetic on those counts to...
(indexes using key values) - Bucket sortBucket sortBucket sort, or bin sort, is a sorting algorithm that works by partitioning an array into a number of buckets. Each bucket is then sorted individually, either using a different sorting algorithm, or by recursively applying the bucket sorting algorithm. It is a distribution sort, and is a cousin of...
(examines bits of keys)
Performance limits and advantages of different sorting techniques
There are fundamental limits on the performance of comparison sorts. A comparison sort must have a lower bound of Ω(n log n) comparison operations. This is a consequence of the limited information available through comparisons alone — or, to put it differently, of the vague algebraic structure of totally ordered sets. In this sense, mergesort, heapsort, and introsort are asymptotically optimalAsymptotically optimal
In computer science, an algorithm is said to be asymptotically optimal if, roughly speaking, for large inputs it performs at worst a constant factor worse than the best possible algorithm...
in terms of the number of comparisons they must perform, although this metric neglects other operations. The three non-comparison sorts above achieve O(n) performance by using operations other than comparisons, allowing them to sidestep this lower bound (assuming elements are constant-sized).
Nevertheless, comparison sorts offer the notable advantage that control over the comparison function allows sorting of many different datatypes and fine control over how the list is sorted. For example, reversing the result of the comparison function allows the list to be sorted in reverse; for instance, one can sort a list of tuple
Tuple
In mathematics and computer science, a tuple is an ordered list of elements. In set theory, an n-tuple is a sequence of n elements, where n is a positive integer. There is also one 0-tuple, an empty sequence. An n-tuple is defined inductively using the construction of an ordered pair...
s in lexicographic order by just creating a comparison function that compares each part in sequence:
function tupleCompare((lefta, leftb, leftc), (righta, rightb, rightc))
if lefta ≠ righta
return compare(lefta, righta)
else if leftb ≠ rightb
return compare(leftb, rightb)
else
return compare(leftc, rightc)
Balanced ternary
Balanced ternary
Balanced ternary is a non-standard positional numeral system , useful for comparison logic. It is a ternary system, but unlike the standard ternary system, the digits have the values −1, 0, and 1...
notation allows comparisons to be made in one step, whose result will be one of "less than", "greater than" or "equal to".
Comparison sorts generally adapt more easily to complex orders such as the order of floating-point numbers. Additionally, once a comparison function is written, any comparison sort can be used without modification; non-comparison sorts typically require specialized versions for each datatype.
This flexibility, together with the efficiency of the above comparison sorting algorithms on modern computers, has led to widespread preference for comparison sorts in most practical work.
Number of comparisons required to sort a list
The number of comparisons that a comparison sort algorithm requires increases in proportion to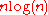 , where
, where  is the number of elements to sort. This bound is asymptotically tight:
is the number of elements to sort. This bound is asymptotically tight:Given a list of distinct numbers (we can assume this because this is a worst-case analysis), there are n factorial
Factorial
In mathematics, the factorial of a non-negative integer n, denoted by n!, is the product of all positive integers less than or equal to n...
permutations exactly one of which is the list in sorted order. The sort algorithm must gain enough information from the comparisons to identify the correct permutation. If the algorithm always completes after at most f(n) steps, it cannot distinguish more than 2f(n) cases because the keys are distinct and each comparison has only two possible outcomes. Therefore,
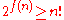 , or equivalently
, or equivalently 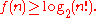
From Stirling's approximation
Stirling's approximation
In mathematics, Stirling's approximation is an approximation for large factorials. It is named after James Stirling.The formula as typically used in applications is\ln n! = n\ln n - n +O\...
we know that
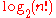 is
is 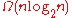 . This provides the lower-bound part of the claim.
. This provides the lower-bound part of the claim.An identical upper bound follows from the existence of the algorithms that attain this bound in the worst case.
The above argument provides an absolute, rather than only asymptotic lower bound on the number of comparisons, namely
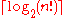 comparisons. This lower bound is fairly good (it can be approached within a linear tolerance by a simple merge sort), but it is known to be inexact. For example,
comparisons. This lower bound is fairly good (it can be approached within a linear tolerance by a simple merge sort), but it is known to be inexact. For example, 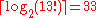 , but the minimal number of comparisons to sort 13 elements has been proved to be 34
, but the minimal number of comparisons to sort 13 elements has been proved to be 34.
Determining the exact number of comparisons needed to sort a given number of entries is a computationally hard problem even for small n, and no simple formula for the solution is known. For some of the few concrete values that have been computed, see .
Lower bound for the average number of comparisons
A similar bound applies to the average number of comparisons. Assuming that- all keys are distinct, i.e. every comparison will give either a>b or a
- the input is a random permutation, chosen uniformly from the set of all possible permutations of n elements,
it is impossible to determine which order the input is in with fewer than log2(n!) comparisons on average.
This can be most easily seen using concepts from information theory
Information theory
Information theory is a branch of applied mathematics and electrical engineering involving the quantification of information. Information theory was developed by Claude E. Shannon to find fundamental limits on signal processing operations such as compressing data and on reliably storing and...
. The Shannon entropy of such a random permutation is log2(n!) bits. Since a comparison can give only two results, the maximum amount of information it provides is 1 bit. Therefore after k comparisons the remaining entropy of the permutation, given the results of those comparisons, is at least log2(n!) - k bits on average. To perform the sort, complete information is needed, so the remaining entropy must be 0. It follows that k must be at least log2(n!).
Note that this differs from the worst case argument given above, in that it does not allow rounding up to the nearest integer. For example, for n = 3, the lower bound for the worst case is 3, the lower bound for the average case as shown above is approximately 2.58, while the highest lower bound for the average case is 8/3, approximately 2.67.
In the case that multiple items may have the same key, there is no obvious statistical interpretation for the term "average case", so an argument like the above cannot be applied without making specific assumptions about the distribution of keys.