The International Organization for Standardization , widely known as ISO, is an international standard-setting body composed of representatives from various national standards organizations. Founded on February 23, 1947, the organization promulgates worldwide proprietary, industrial and commercial...
Natural language processing is a field of computer science and linguistics concerned with the interactions between computers and human languages; it began as a branch of artificial intelligence....
Machine-readable dictionary is a dictionary stored as machine data instead of being printed on paper. It is an electronic dictionary and lexical database....
In linguistics, the lexicon of a language is its vocabulary, including its words and expressions. A lexicon is also a synonym of the word thesaurus. More formally, it is a language's inventory of lexemes. Coined in English 1603, the word "lexicon" derives from the Greek "λεξικόν" , neut...
Standardization is the process of developing and implementing technical standards.The goals of standardization can be to help with independence of single suppliers , compatibility, interoperability, safety, repeatability, or quality....
of principles and methods relating to language resources in the contexts of multilingual communication and cultural diversity
Cultural diversity
Cultural diversity is having different cultures respect each other's differences. It could also mean the variety of human societies or cultures in a specific region, or in the world as a whole...
.
Objectives of LMF
The goals of LMF are to provide a common model for the creation and use of lexical resource
Lexical resource
A lexical resource is a database consisting of one or several dictionaries.Depending on the type of languages that are addressed, the LR may be qualified as monolingual, bilingual or multilingual. For bilingual and multilingual LRs, the words may be connected or not connected, from a language to...
s, to manage the exchange of data between and among these resources, and to enable the merging of large number of individual electronic resources to form extensive global electronic resources.
Types of individual instantiations of LMF can include monolingual, bilingual or multilingual lexical resources. The same specifications are to be used for both small and large lexicons, for both simple and complex lexicons, for both written and spoken lexical representations. The descriptions range from morphology
Morphology (linguistics)
In linguistics, morphology is the identification, analysis and description, in a language, of the structure of morphemes and other linguistic units, such as words, affixes, parts of speech, intonation/stress, or implied context...
Computational semantics is the study of how to automate the process of constructing and reasoning with meaning representations of natural language expressions...
Computer-assisted translation, computer-aided translation, or CAT is a form of translation wherein a human translator translates texts using computer software designed to support and facilitate the translation process....
Most of the languages of Europe belong to Indo-European language family. These are divided into a number of branches, including Romance, Germanic, Balto-Slavic, Greek, and others. The Uralic languages also have a significant presence in Europe, including the national languages Hungarian, Finnish,...
but cover all natural languages. The range of targeted NLP applications
Application software
Application software, also known as an application or an "app", is computer software designed to help the user to perform specific tasks. Examples include enterprise software, accounting software, office suites, graphics software and media players. Many application programs deal principally with...
is not restricted. LMF is able to represent most lexicons, including WordNet
WordNet
WordNet is a lexical database for the English language. It groups English words into sets of synonyms called synsets, provides short, general definitions, and records the various semantic relations between these synonym sets...
, EDR and PAROLE lexicons.
History of LMF
In the past, lexicon standardization has been studied and developed by a series of projects like GENELEX, EDR, EAGLES, MULTEXT, PAROLE, SIMPLE and ISLE. Then, the ISO/TC37 National delegations decided to address standards dedicated to NLP and lexicon representation.
The work on LMF started in Summer 2003 by a new work item proposal issued by the US delegation. In Fall 2003, the French delegation issued a technical proposition for a data model
Data model
A data model in software engineering is an abstract model, that documents and organizes the business data for communication between team members and is used as a plan for developing applications, specifically how data is stored and accessed....
dedicated to NLP lexicons. In early 2004, the ISO/TC37 committee decided to form a common ISO project with Nicoletta Calzolari (CNR
Consiglio Nazionale delle Ricerche
The Consiglio Nazionale delle Ricerche or National Research Council, is an Italian public organization set up to support scientific and technological research. Its headquarters are in Rome.-History:The institution was founded in 1923...
-ILC Italy) as convenor and Gil Francopoulo (Tagmatica France) and Monte George (ANSI
American National Standards Institute
The American National Standards Institute is a private non-profit organization that oversees the development of voluntary consensus standards for products, services, processes, systems, and personnel in the United States. The organization also coordinates U.S. standards with international...
USA) as editors.
The first step in developing LMF was to design an overall framework based on the general features of existing lexicons and to develop a consistent terminology to describe the components of those lexicons. The next step was the actual design of a comprehensive model that best represented all of the lexicons in detail. A large panel of 60 experts contributed a wide range of requirements for LMF that covered many types of NLP lexicons. The editors of LMF worked closely with the panel of experts to identify the best solutions and reach a consensus on the design of LMF. Special attention was paid to the morphology in order to provide powerful mechanisms for handling problems in several languages that were known as difficult to handle. 13 versions have been written, dispatched (to the National nominated experts), commented and discussed during various ISO technical meetings. After five years of work, including numerous face-to-face meetings and e-mail exchanges, the editors arrived at a coherent UML model. In conclusion, LMF should be considered a synthesis of the state of the art in NLP lexicon field.
Current stage
The ISO number is 24613. The LMF specification has been published officially as an International Standard on 17 November 2008.
LMF as one of the members of the ISO/TC37 family of standards
The ISO/TC37 standards are currently elaborated as high level specifications and deal with word segmentation (ISO 24614), annotations (ISO 24611 aka MAF, ISO 24612 aka LAF, ISO 24615 aka SynAF, and ISO 24617-1 aka SemAF/Time), feature structure
Feature structure
In phrase structure grammars, such as generalised phrase structure grammar, head-driven phrase structure grammar and lexical functional grammar, a feature structure is essentially a set of attribute-value pairs. For example the attribute named number might have the value singular. The value of an...
s (ISO 24610), multimedia containers (ISO 24616 aka MLIF), and lexicons
Lexical Markup Framework
ISO 24613:2008, Language resource management - Lexical markup framework , is the ISO International Organization for Standardization ISO/TC37 standard for natural language processing and machine-readable dictionary lexicons...
(ISO 24613).
These standards are based on low level specifications dedicated to constants, namely data categories (revision of ISO 12620), language code
Language code
A language code is a code that assigns letters and/or numbers as identifiers or classifiers for languages. These codes may be used to organize library collections or presentations of data, to choose the correct localizations and translations in computing, and as a shorthand designation for longer...
ISO 639 is a set of standards by the International Organization for Standardization that is concerned with representation of names for language and language groups....
A writing system is a symbolic system used to represent elements or statements expressible in language.-General properties:Writing systems are distinguished from other possible symbolic communication systems in that the reader must usually understand something of the associated spoken language to...
ISO 15924, Codes for the representation of names of scripts, defines two sets of codes for a number of writing systems . Each script is given both a four-letter code and a numeric one....
Country codes are short alphabetic or numeric geographical codes developed to represent countries and dependent areas, for use in data processing and communications. Several different systems have been developed to do this. The best known of these is ISO 3166-1...
ISO 3166 is a standard published by the International Organization for Standardization . It defines codes for the names of countries, dependent territories, special areas of geographical interest, and their principal subdivisions . The official name of the standard is Codes for the representation...
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
(ISO 10646).
The two level organization forms a coherent family of standards with the following common and simple rules:
the high level specification provides structural elements that are adorned by the standardized constants;
the low level specifications provide standardized constants as metadata.
Key standards used by LMF
The linguistics constants like /feminine/ or /transitive/ are not defined within LMF but are recorded in the Data Category Registry (DCR) that is maintained as a global resource by ISO/TC37 in compliance with ISO/IEC 11179-3:2003 http://hal.inria.fr/docs/00/12/14/74/PDF/LREC2006WS-RI-20AprilBis.pdf. And these constants are used to adorn the high level structural elements.
Unified Modeling Language is a standardized general-purpose modeling language in the field of object-oriented software engineering. The standard is managed, and was created, by the Object Management Group...
Object Management Group is a consortium, originally aimed at setting standards for distributed object-oriented systems, and is now focused on modeling and model-based standards.- Overview :...
(OMG). The structure is specified by means of UML class diagram
Diagram
A diagram is a two-dimensional geometric symbolic representation of information according to some visualization technique. Sometimes, the technique uses a three-dimensional visualization which is then projected onto the two-dimensional surface...
s. The examples are presented by means of UML instance (or object) diagrams.
Document Type Definition is a set of markup declarations that define a document type for SGML-family markup languages...
is given in an annex of the LMF document.
Model structure
LMF is composed of the following components:
The core package which is the structural skeleton which describes the basic hierarchy of information in a lexical entry.
Extensions of the core package which are expressed in a framework that describes the reuse of the core components in conjunction with the additional components required for a specific lexical resource.
The extensions are specifically dedicated to morphology
Morphology (linguistics)
In linguistics, morphology is the identification, analysis and description, in a language, of the structure of morphemes and other linguistic units, such as words, affixes, parts of speech, intonation/stress, or implied context...
Machine-readable dictionary is a dictionary stored as machine data instead of being printed on paper. It is an electronic dictionary and lexical database....
Natural language processing is a field of computer science and linguistics concerned with the interactions between computers and human languages; it began as a branch of artificial intelligence....
Natural language processing is a field of computer science and linguistics concerned with the interactions between computers and human languages; it began as a branch of artificial intelligence....
Computational semantics is the study of how to automate the process of constructing and reasoning with meaning representations of natural language expressions...
Natural language processing is a field of computer science and linguistics concerned with the interactions between computers and human languages; it began as a branch of artificial intelligence....
A Multilingual notation is a representation in a lexical resource that allows the translation between two or more words.-UML diagrams:For instance, within LMF, a multilingual notation could be as presented in the following diagram, for English / French translation...
Natural language processing is a field of computer science and linguistics concerned with the interactions between computers and human languages; it began as a branch of artificial intelligence....
A morphological pattern is a set of associations and/or operations that build the various forms of a lexeme, possibly by inflection, agglutination, compounding or derivation.-Note:...
A multiword expression is a lexeme made up of a sequence of two or more lexemes that has properties that are not predictable from the properties of the individual lexemes or their normal mode of combination....
A pattern, from the French patron, is a type of theme of recurring events or objects, sometimes referred to as elements of a set of objects.These elements repeat in a predictable manner...
A pattern, from the French patron, is a type of theme of recurring events or objects, sometimes referred to as elements of a set of objects.These elements repeat in a predictable manner...
s.
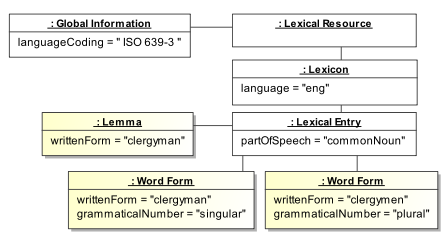
A tiny example
In the following example, the lexical entry is associated with a lemma clergyman and two inflected forms clergyman and clergymen. The language coding is set for the whole lexical resource. The language value is set for the whole lexicon as shown in the following UML
Unified Modeling Language
Unified Modeling Language is a standardized general-purpose modeling language in the field of object-oriented software engineering. The standard is managed, and was created, by the Object Management Group...
A lexical resource is a database consisting of one or several dictionaries.Depending on the type of languages that are addressed, the LR may be qualified as monolingual, bilingual or multilingual. For bilingual and multilingual LRs, the words may be connected or not connected, from a language to...
, Global Information, Lexicon, Lexical Entry, Lemma, and Word Form define the structure of the lexicon. They are specified within the LMF document.
On the contrary, languageCoding, language, partOfSpeech
Lexical category
In grammar, a part of speech is a linguistic category of words , which is generally defined by the syntactic or morphological behaviour of the lexical item in question. Common linguistic categories include noun and verb, among others...
In linguistics, grammatical number is a grammatical category of nouns, pronouns, and adjective and verb agreement that expresses count distinctions ....
, singular, plural are data categories that are taken from the Data Category Registry. These marks adorn the structure. The values ISO 639-3, clergyman, clergymen are plain character strings. The value eng is taken from the list of languages as defined by ISO 639-3
ISO 639-3
ISO 639-3:2007, Codes for the representation of names of languages — Part 3: Alpha-3 code for comprehensive coverage of languages, is an international standard for language codes in the ISO 639 series. The standard describes three‐letter codes for identifying languages. It extends the ISO 639-2...
.
With some additional information like dtdVersion and feat, the same data can be expressed by the following XML
XML
Extensible Markup Language is a set of rules for encoding documents in machine-readable form. It is defined in the XML 1.0 Specification produced by the W3C, and several other related specifications, all gratis open standards....
fragment:
This example is rather simple, while LMF can represent much more complex linguistic descriptions the XML tagging is correspondingly complex.
The International Conference on Language Resources and Evaluation is a biennial conference organised by the European Language Resources Association with the support of institutions and organisations involved in Natural language processing....
The International Conference on Language Resources and Evaluation is a biennial conference organised by the European Language Resources Association with the support of institutions and organisations involved in Natural language processing....
Computational lexicology is that branch of computational linguistics, which is concerned with the use of computers in the study of lexicon. It has been more narrowly described by some scholars as the use of computers in the study of machine-readable dictionaries...
Lexical semantics is a subfield of linguistic semantics. It is the study of how and what the words of a language denote . Words may either be taken to denote things in the world, or concepts, depending on the particular approach to lexical semantics.The units of meaning in lexical semantics are...
In linguistics, morphology is the identification, analysis and description, in a language, of the structure of morphemes and other linguistic units, such as words, affixes, parts of speech, intonation/stress, or implied context...
for explanations concerning paradigms and morphosyntax
Machine translation, sometimes referred to by the abbreviation MT is a sub-field of computational linguistics that investigates the use of computer software to translate text or speech from one natural language to another.On a basic...
for a presentation of the different types of multilingual notations (see section Approaches)
A morphological pattern is a set of associations and/or operations that build the various forms of a lexeme, possibly by inflection, agglutination, compounding or derivation.-Note:...
for the difference between a paradigm and a paradigm pattern
WordNet is a lexical database for the English language. It groups English words into sets of synonyms called synsets, provides short, general definitions, and records the various semantic relations between these synonym sets...
for a presentation of the most famous semantic lexicon for the English language
UTX is a set of formats for user-created dictionaries. Dictionary, in this case, means a set of pairs that consist of source language entry, target language entry, etc....
(UTX) for a user-oriented, alternative format for machine-readable dictionaries
Universal Networking Language is a declarative formal language specifically designed to represent semantic data extracted from natural language texts...
The source of this article is wikipedia, the free encyclopedia. The text of this article is licensed under the GFDL.