

Frank–Wolfe algorithm
Encyclopedia
In mathematical optimization, the reduced gradient method of Frank and Wolfe is an iterative method
for nonlinear programming
. Also known as the Frank–Wolfe algorithm and the convex combination algorithm, the reduced gradient method was proposed by Marguerite Frank and Phil Wolfe in 1956 as an algorithm
for quadratic programming
. In phase one
, the reduced gradient method finds a feasible solution to the linear constraints, if one exists. Thereafter, at each iteration, the method takes a descent step
in the negative gradient direction
, so reducing the objective function; this gradient descent
step is "reduced" to remain in the polyhedral
feasible region of the linear constraints. Because quadratic programming is a generalization of linear programming, the reduced gradient method is a generalization of Dantzig's simplex algorithm
for linear programming
.
The reduced gradient method is an iterative method for nonlinear programming
, a method that need not be restricted to quadratic programming. While the method is slower than competing methods and has been abandoned as a general purpose method of nonlinear programming, it remains widely used for specially structured problems of large scale optimization. In particular, the reduced gradient method remains popular and effective for finding approximate minimum–cost flow
s in transportation network
s, which often have enormous size.
Where the n×n matrix E is positive semidefinite, h is an n×1 vector, and represents a feasible region defined by a mix of linear inequality and equality constraints (for example Ax ≤ b, Cx = d).
represents a feasible region defined by a mix of linear inequality and equality constraints (for example Ax ≤ b, Cx = d).
 and let
and let  be any point in
be any point in  .
.
Step 2. Convergence test. If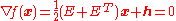 then Stop, we have found the minimum.
then Stop, we have found the minimum.
Step 3. Direction-finding subproblem. The approximation of the problem that is obtained by replacing the function f with its first-order Taylor expansion
around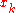 is found. Solve for
is found. Solve for  :
:
Step 4. Step size determination. Find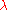 that minimizes
that minimizes 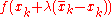 subject to
subject to 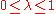 . If
. If 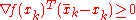 then Stop, we have found the minimum in
then Stop, we have found the minimum in 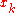 .
.
Step 5. Update. Let , let
, let 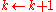 and go back to Step 2.
and go back to Step 2.
Iterative method
In computational mathematics, an iterative method is a mathematical procedure that generates a sequence of improving approximate solutions for a class of problems. A specific implementation of an iterative method, including the termination criteria, is an algorithm of the iterative method...
for nonlinear programming
Nonlinear programming
In mathematics, nonlinear programming is the process of solving a system of equalities and inequalities, collectively termed constraints, over a set of unknown real variables, along with an objective function to be maximized or minimized, where some of the constraints or the objective function are...
. Also known as the Frank–Wolfe algorithm and the convex combination algorithm, the reduced gradient method was proposed by Marguerite Frank and Phil Wolfe in 1956 as an algorithm
Algorithm
In mathematics and computer science, an algorithm is an effective method expressed as a finite list of well-defined instructions for calculating a function. Algorithms are used for calculation, data processing, and automated reasoning...
for quadratic programming
Quadratic programming
Quadratic programming is a special type of mathematical optimization problem. It is the problem of optimizing a quadratic function of several variables subject to linear constraints on these variables....
. In phase one
Simplex algorithm
In mathematical optimization, Dantzig's simplex algorithm is a popular algorithm for linear programming. The journal Computing in Science and Engineering listed it as one of the top 10 algorithms of the twentieth century....
, the reduced gradient method finds a feasible solution to the linear constraints, if one exists. Thereafter, at each iteration, the method takes a descent step
Gradient descent
Gradient descent is a first-order optimization algorithm. To find a local minimum of a function using gradient descent, one takes steps proportional to the negative of the gradient of the function at the current point...
in the negative gradient direction
Gradient descent
Gradient descent is a first-order optimization algorithm. To find a local minimum of a function using gradient descent, one takes steps proportional to the negative of the gradient of the function at the current point...
, so reducing the objective function; this gradient descent
Gradient descent
Gradient descent is a first-order optimization algorithm. To find a local minimum of a function using gradient descent, one takes steps proportional to the negative of the gradient of the function at the current point...
step is "reduced" to remain in the polyhedral
Polyhedron
In elementary geometry a polyhedron is a geometric solid in three dimensions with flat faces and straight edges...
feasible region of the linear constraints. Because quadratic programming is a generalization of linear programming, the reduced gradient method is a generalization of Dantzig's simplex algorithm
Simplex algorithm
In mathematical optimization, Dantzig's simplex algorithm is a popular algorithm for linear programming. The journal Computing in Science and Engineering listed it as one of the top 10 algorithms of the twentieth century....
for linear programming
Linear programming
Linear programming is a mathematical method for determining a way to achieve the best outcome in a given mathematical model for some list of requirements represented as linear relationships...
.
The reduced gradient method is an iterative method for nonlinear programming
Nonlinear programming
In mathematics, nonlinear programming is the process of solving a system of equalities and inequalities, collectively termed constraints, over a set of unknown real variables, along with an objective function to be maximized or minimized, where some of the constraints or the objective function are...
, a method that need not be restricted to quadratic programming. While the method is slower than competing methods and has been abandoned as a general purpose method of nonlinear programming, it remains widely used for specially structured problems of large scale optimization. In particular, the reduced gradient method remains popular and effective for finding approximate minimum–cost flow
Flow network
In graph theory, a flow network is a directed graph where each edge has a capacity and each edge receives a flow. The amount of flow on an edge cannot exceed the capacity of the edge. Often in Operations Research, a directed graph is called a network, the vertices are called nodes and the edges are...
s in transportation network
Transportation network
Transportation network may refer to:* Transport network, physical infrastructure* Transportation network , the mathematical graph theory...
s, which often have enormous size.
Problem statement
- Minimize
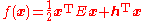
- subject to
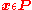 .
.
Where the n×n matrix E is positive semidefinite, h is an n×1 vector, and
represents a feasible region defined by a mix of linear inequality and equality constraints (for example Ax ≤ b, Cx = d).Algorithm
Step 1. Initialization. Let and let be any point in .Step 2. Convergence test. If
then Stop, we have found the minimum.Step 3. Direction-finding subproblem. The approximation of the problem that is obtained by replacing the function f with its first-order Taylor expansion
Taylor series
In mathematics, a Taylor series is a representation of a function as an infinite sum of terms that are calculated from the values of the function's derivatives at a single point....
around
is found. Solve for :
- Minimize

- Subject to
 \bar{x}_k).
\bar{x}_k).
Step 4. Step size determination. Find
that minimizes subject to . If then Stop, we have found the minimum in .Step 5. Update. Let
, let and go back to Step 2.