

UTF-1
Encyclopedia
UTF-1 is a way of transforming ISO 10646/Unicode
into a stream of byte
s. Due to the design it is not possible to resynchronise if decoding starts in the middle of a character (this makes truncation hard, among other things) and simple byte-oriented search routines cannot be reliably used with it. UTF-1 is also fairly slow due to its use of division by a number which is not a power of 2. Due to these issues, UTF-1 never gained wide acceptance and has been almost totally replaced by UTF-8
.
; a single Unicode
code point can be encoded in one, two, three, or five octets. While the ASCII
range is encoded as one octet, as in UTF-8
, the ASCII octets 0x21 - 0x7E (decimal 33 - 126) are also used in UTF-1 multi-byte encodings; therefore UTF-1 is unsuited for many Internet protocols, including MIME
.
UTF-1 does not use the C0 and C1 control codes
in other encodings – any 0x
00–0x20 or 0x7F–0x9F octet stands for the corresponding code points in ISO-8859-1 (U+0000–0020 and U+007F–009F, respectively). This design with 66 protected octets tried to be ISO 2022
compatible.
The UTF-1 encoding scheme uses "modulo
190" arithmetic ( ); it was designed to encode the complete 31 bits of the original Universal Character Set
); it was designed to encode the complete 31 bits of the original Universal Character Set
(UCS-4).
For comparison, UTF-8 protects all 128 ASCII octets, and needs two bits in trail bytes of multi-byte encodings for this purpose, resulting in "modulo 64" arithmetic (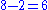 ,
, 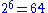 ). BOCU-1
). BOCU-1
protects only the minimal set required for MIME-compatibility (0x00, 0x07–0x0F, 0x1A–0x1B, and 0x20), resulting in "modulo 243" arithmetic ( ).
).
Unicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
into a stream of byte
Byte
The byte is a unit of digital information in computing and telecommunications that most commonly consists of eight bits. Historically, a byte was the number of bits used to encode a single character of text in a computer and for this reason it is the basic addressable element in many computer...
s. Due to the design it is not possible to resynchronise if decoding starts in the middle of a character (this makes truncation hard, among other things) and simple byte-oriented search routines cannot be reliably used with it. UTF-1 is also fairly slow due to its use of division by a number which is not a power of 2. Due to these issues, UTF-1 never gained wide acceptance and has been almost totally replaced by UTF-8
UTF-8
UTF-8 is a multibyte character encoding for Unicode. Like UTF-16 and UTF-32, UTF-8 can represent every character in the Unicode character set. Unlike them, it is backward-compatible with ASCII and avoids the complications of endianness and byte order marks...
.
Design
UTF-1 is a multi-byte encoding like UTF-8UTF-8
UTF-8 is a multibyte character encoding for Unicode. Like UTF-16 and UTF-32, UTF-8 can represent every character in the Unicode character set. Unlike them, it is backward-compatible with ASCII and avoids the complications of endianness and byte order marks...
; a single Unicode
Unicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
code point can be encoded in one, two, three, or five octets. While the ASCII
ASCII
The American Standard Code for Information Interchange is a character-encoding scheme based on the ordering of the English alphabet. ASCII codes represent text in computers, communications equipment, and other devices that use text...
range is encoded as one octet, as in UTF-8
UTF-8
UTF-8 is a multibyte character encoding for Unicode. Like UTF-16 and UTF-32, UTF-8 can represent every character in the Unicode character set. Unlike them, it is backward-compatible with ASCII and avoids the complications of endianness and byte order marks...
, the ASCII octets 0x21 - 0x7E (decimal 33 - 126) are also used in UTF-1 multi-byte encodings; therefore UTF-1 is unsuited for many Internet protocols, including MIME
MIME
Multipurpose Internet Mail Extensions is an Internet standard that extends the format of email to support:* Text in character sets other than ASCII* Non-text attachments* Message bodies with multiple parts...
.
UTF-1 does not use the C0 and C1 control codes
C0 and C1 control codes
Most character encodings, in addition to representing printable characters, may also represent additional information about the text, such as the position of a cursor, an instruction to start a new line, or a message that the text has been received...
in other encodings – any 0x
Hexadecimal
In mathematics and computer science, hexadecimal is a positional numeral system with a radix, or base, of 16. It uses sixteen distinct symbols, most often the symbols 0–9 to represent values zero to nine, and A, B, C, D, E, F to represent values ten to fifteen...
00–0x20 or 0x7F–0x9F octet stands for the corresponding code points in ISO-8859-1 (U+0000–0020 and U+007F–009F, respectively). This design with 66 protected octets tried to be ISO 2022
ISO/IEC 2022
ISO/IEC 2022 Information technology—Character code structure and extension techniques, is an ISO standard specifying...
compatible.
The UTF-1 encoding scheme uses "modulo
Modulo operation
In computing, the modulo operation finds the remainder of division of one number by another.Given two positive numbers, and , a modulo n can be thought of as the remainder, on division of a by n...
190" arithmetic (
); it was designed to encode the complete 31 bits of the original Universal Character SetUniversal Character Set
The Universal Character Set , defined by the International Standard ISO/IEC 10646, Information technology — Universal multiple-octet coded character set , is a standard set of characters upon which many character encodings are based...
(UCS-4).
For comparison, UTF-8 protects all 128 ASCII octets, and needs two bits in trail bytes of multi-byte encodings for this purpose, resulting in "modulo 64" arithmetic (
, ). BOCU-1Binary Ordered Compression for Unicode
Binary Ordered Compression for Unicode is a MIME compatible Unicode compression scheme. BOCU-1 combines the wide applicability of UTF-8 with the compactness of Standard Compression Scheme for Unicode . This Unicode encoding is designed to be useful for compressing short strings, and maintains code...
protects only the minimal set required for MIME-compatibility (0x00, 0x07–0x0F, 0x1A–0x1B, and 0x20), resulting in "modulo 243" arithmetic (
).| codepoint | UTF-16BE | UTF-16LE | UTF-8 | UTF-1 |
|---|---|---|---|---|
| U+007F | 007F | 7F00 | 7F | 7F |
| U+0080 | 0080 | 8000 | C280 | 80 |
| U+009F | 009F | 9F00 | C29F | 9F |
| U+00A0 | 00A0 | A000 | C2A0 | A0A0 |
| U+00BF | 00BF | BF00 | C2BF | A0BF |
| U+00C0 | 00C0 | C000 | C380 | A0C0 |
| U+00FF | 00FF | FF00 | C3BF | A0FF |
| U+0100 | 0100 | 0001 | C480 | A121 |
| U+015D | 015D | 5D01 | C59D | A17E |
| U+015E | 015E | 5E01 | C59E | A1A0 |
| U+01BD | 01BD | BD01 | C6BD | A1FF |
| U+01BE | 01BE | BE01 | C6BE | A221 |
| U+07FF | 07FF | FF07 | DFBF | AA72 |
| U+0800 | 0800 | 0008 | E0A080 | AA73 |
| U+0FFF | 0FFF | FF0F | E0BFBF | B548 |
| U+1000 | 1000 | 0010 | E18080 | B549 |
| U+4015 | 4015 | 1540 | E48095 | F5FF |
| U+4016 | 4016 | 1640 | E48096 | F62121 |
| U+D7FF | D7FF | FFD7 | ED9FBF | F72FC3 |
| U+E000 | E000 | 00E0 | EE8080 | F73A79 |
| U+F8FF | F8FF | FFF8 | EFA3BF | F75C3C |
| U+FDD0 | FDD0 | D0FD | EFB790 | F762BA |
| U+FDEF | FDEF | EFFD | EFB7AF | F762D9 |
| U+FEFF | FEFF | FFFE | EFBBBF | F7644C |
| U+FFFD | FFFD | FDFF | EFBFBD | F765AD |
| U+FFFE | FFFE | FEFF | EFBFBE | F765AE |
| U+FFFF | FFFF | FFFF | EFBFBF | F765AF |
| U+10000 | D800DC00 | 00D800DC | F0908080 | F765B0 |
| U+38E2D | D8A3DE2D | A3D82DDE | F0B8B8AD | FBFFFF |
| U+38E2E | D8A3DE2E | A3D82EDE | F0B8B8AE | FC21212121 |
| U+FFFFF | DBBFDFFF | BFDBFFDF | F3BFBFBF | FC2137B27A |
| U+100000 | DBC0DC00 | C0DB00DC | F4808080 | FC2137B27B |
| U+10FFFF | DBFFDFFF | FFDBFFDF | F48FBFBF | FC21396E6C |