

Binary Ordered Compression for Unicode
Encyclopedia
Binary Ordered Compression for Unicode (BOCU) is a MIME
compatible Unicode compression scheme. BOCU-1 combines the wide applicability of UTF-8
with the compactness of Standard Compression Scheme for Unicode
(SCSU). This Unicode
encoding
is designed to be useful for compressing short strings, and maintains code point order. BOCU-1 is specified in a Unicode Technical Note.
For comparison SCSU was adopted as standard Unicode compression scheme with a byte/code point ratio similar to language-specific code page
s. SCSU has not been widely adopted, as it is not suitable for MIME “text” media types. For example, SCSU cannot be used directly in emails and similar protocols. SCSU requires a complicated encoder design for good performance. Usually, the zip, bzip2
, and other industry standard algorithms compact larger amounts of Unicode text more efficiently.
Both SCSU and BOCU-1 are IANA
registered charsets.
, and all ranges are inclusive.
Code points from
The difference between the current code point and the normalized previous code point is encoded as follows:
Each byte range is lexicographically ordered
with the following thirteen byte values excluded:
Any ASCII input
affects at most one code point, for SCSU
it can affect the entire document.
BOCU-1 offers a similar robustness also for input texts without the above mentioned values with the special reset code
The optional use of a signature
In theory UTF-1
and UTF-8
could encode the original UCS-4
set with 31 bits up to
the modern Unicode
set from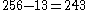 octets in multi-byte encodings. BOCU-1 needs at most four bytes consisting of a lead byte and one to three trail bytes. The trail bytes encode a remaining "modulo
octets in multi-byte encodings. BOCU-1 needs at most four bytes consisting of a lead byte and one to three trail bytes. The trail bytes encode a remaining "modulo
243" (base 243) difference, the lead byte determines the number of trail bytes and an initial difference.
Note that the reset byte
#6,737,994, which also mentions the specific BOCU-1 implementation. IBM
, which employed both of the inventors of BOCU-1 at the time it was created, states in the Unicode Technical Note that implementers of a "fully compliant version of BOCU-1" must contact IBM to request a royalty-free license. BOCU-1 is the only Unicode compression scheme described on the Unicode Web site that is known to be encumbered with intellectual property
restrictions.
By contrast, IBM also filed for a patent on UTF-EBCDIC
, but it chose in that case to make the documentation and encoding scheme “freely available to anyone concerned towards making the transformation format as part of the UCS standards,” instead of requiring implementers to request a license.
MIME
Multipurpose Internet Mail Extensions is an Internet standard that extends the format of email to support:* Text in character sets other than ASCII* Non-text attachments* Message bodies with multiple parts...
compatible Unicode compression scheme. BOCU-1 combines the wide applicability of UTF-8
UTF-8
UTF-8 is a multibyte character encoding for Unicode. Like UTF-16 and UTF-32, UTF-8 can represent every character in the Unicode character set. Unlike them, it is backward-compatible with ASCII and avoids the complications of endianness and byte order marks...
with the compactness of Standard Compression Scheme for Unicode
Standard Compression Scheme for Unicode
The Standard Compression Scheme for Unicode is a Unicode Technical Standard for reducing the number of bytes needed to represent Unicode text, especially if that text uses mostly characters from one or a small number of per-language character blocks. It does so by dynamically mapping values in the...
(SCSU). This Unicode
Unicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
encoding
Character encoding
A character encoding system consists of a code that pairs each character from a given repertoire with something else, such as a sequence of natural numbers, octets or electrical pulses, in order to facilitate the transmission of data through telecommunication networks or storage of text in...
is designed to be useful for compressing short strings, and maintains code point order. BOCU-1 is specified in a Unicode Technical Note.
For comparison SCSU was adopted as standard Unicode compression scheme with a byte/code point ratio similar to language-specific code page
Code page
Code page is another term for character encoding. It consists of a table of values that describes the character set for a particular language. The term code page originated from IBM's EBCDIC-based mainframe systems, but many vendors use this term including Microsoft, SAP, and Oracle Corporation...
s. SCSU has not been widely adopted, as it is not suitable for MIME “text” media types. For example, SCSU cannot be used directly in emails and similar protocols. SCSU requires a complicated encoder design for good performance. Usually, the zip, bzip2
Bzip2
bzip2 is a free and open source implementation of the Burrows–Wheeler algorithm. It is developed and maintained by Julian Seward. Seward made the first public release of bzip2, version 0.15, in July 1996.-Compression efficiency:...
, and other industry standard algorithms compact larger amounts of Unicode text more efficiently.
Both SCSU and BOCU-1 are IANA
Internet Assigned Numbers Authority
The Internet Assigned Numbers Authority is the entity that oversees global IP address allocation, autonomous system number allocation, root zone management in the Domain Name System , media types, and other Internet Protocol-related symbols and numbers...
registered charsets.
Details
All numbers in this section are hexadecimalHexadecimal
In mathematics and computer science, hexadecimal is a positional numeral system with a radix, or base, of 16. It uses sixteen distinct symbols, most often the symbols 0–9 to represent values zero to nine, and A, B, C, D, E, F to represent values ten to fifteen...
, and all ranges are inclusive.
Code points from
U+0000 to U+0020 are encoded in BOCU-1 as the corresponding byte value. All other code points (that is, U+0021 through U+D7FF and U+E000 through U+10FFFF) are encoded as a difference between the code point and a normalized version of the most recently encoded code point that was not an ASCII space (U+0020). The initial state is U+0040. The normalization mapping is as follows:| Code range | Normalized code point | Notes |
|---|---|---|
U+3040 to U+309F |
U+3070 |
Hiragana Hiragana is a Japanese syllabary, one basic component of the Japanese writing system, along with katakana, kanji, and the Latin alphabet . Hiragana and katakana are both kana systems, in which each character represents one mora... |
U+4E00 to U+9FA5 |
U+7711 |
Unihan |
U+AC00 to U+D7A3 |
U+C1D1 |
Hangul Hangul Hangul,Pronounced or ; Korean: 한글 Hangeul/Han'gŭl or 조선글 Chosŏn'gŭl/Joseongeul the Korean alphabet, is the native alphabet of the Korean language. It is a separate script from Hanja, the logographic Chinese characters which are also sometimes used to write Korean... |
U+0020 |
encoder state kept as is | Space |
U+hhhh00 to U+hhhh7F(excluding ranges above) |
U+hhhh40 |
middle of 128 |
U+hhhh80 to U+hhhhFF(excluding ranges above) |
U+hhhhC0 |
middle of 128 |
The difference between the current code point and the normalized previous code point is encoded as follows:
| Difference range | Byte sequence range (see below) |
|---|---|
-10FF9F to -2DD0D |
21 F0 58 D9 to 21 FF FF FF |
-2DD0C to -2912 |
22 01 01 to 24 FF FF |
-2911 to -41 |
25 01 to 4F FF |
-40 to 3F |
50 to CF |
40 to 2910 |
D0 01 to FA FF |
2911 to 2DD0B |
FB 01 01 to FD FF FF |
2DD0C to 10FFBF |
FE 01 01 01 to FE 19 B4 54 |
Each byte range is lexicographically ordered
Lexicographical order
In mathematics, the lexicographic or lexicographical order, , is a generalization of the way the alphabetical order of words is based on the alphabetical order of letters.-Definition:Given two partially ordered sets A and B, the lexicographical order on...
with the following thirteen byte values excluded:
00 07 08 09 0A 0B 0C 0D 0E 0F 1A 1B 20. For example, the byte sequence FC 06 FF, coding for a difference of 1156B, is immediately followed by the byte sequence FC 10 01, coding for a difference of 1156C.Any ASCII input
U+0000 to U+007F excluding space U+0020 resets the encoder to U+0040. Because the above mentioned values cover line end code points U+000D and U+000A as is (0D 0A), the encoder is in a known state at the begin of each line. The corruption of a single byte therefore affects at most one line. For comparison, the corruption of a single byte in UTF-8UTF-8
UTF-8 is a multibyte character encoding for Unicode. Like UTF-16 and UTF-32, UTF-8 can represent every character in the Unicode character set. Unlike them, it is backward-compatible with ASCII and avoids the complications of endianness and byte order marks...
affects at most one code point, for SCSU
Standard Compression Scheme for Unicode
The Standard Compression Scheme for Unicode is a Unicode Technical Standard for reducing the number of bytes needed to represent Unicode text, especially if that text uses mostly characters from one or a small number of per-language character blocks. It does so by dynamically mapping values in the...
it can affect the entire document.
BOCU-1 offers a similar robustness also for input texts without the above mentioned values with the special reset code
0xFF. When a decoder finds this octet it resets its state to U+0040 as for a line end. The use of 0xFF reset bytes is not recommended in the BOCU-1 specification, because it conflicts with other BOCU-1 design goals, notably the binary order.The optional use of a signature
U+FEFF at the begin of BOCU-1 encoded texts, i.e. the BOCU-1 byte sequence FB EE 28, changes the initial state U+0040 to U+FE80. In other words the signature cannot simply be stripped as in most other Unicode encoding schemes. Adding a reset byte after the signature (FB EE 28 FF) could avoid this effect, but the BOCU-1 specification does not recommend this practice.In theory UTF-1
UTF-1
UTF-1 is a way of transforming ISO 10646/Unicode into a stream of bytes. Due to the design it is not possible to resynchronise if decoding starts in the middle of a character and simple byte-oriented search routines cannot be reliably used with it. UTF-1 is also fairly slow due to its use of...
and UTF-8
UTF-8
UTF-8 is a multibyte character encoding for Unicode. Like UTF-16 and UTF-32, UTF-8 can represent every character in the Unicode character set. Unlike them, it is backward-compatible with ASCII and avoids the complications of endianness and byte order marks...
could encode the original UCS-4
Universal Character Set
The Universal Character Set , defined by the International Standard ISO/IEC 10646, Information technology — Universal multiple-octet coded character set , is a standard set of characters upon which many character encodings are based...
set with 31 bits up to
7FFFFFFF. BOCU-1 and UTF-16 can encodethe modern Unicode
Unicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
set from
U+0000 to U+10FFFF. Excluding the thirteen protected code points encoded as single octets BOCU-1 can use octets in multi-byte encodings. BOCU-1 needs at most four bytes consisting of a lead byte and one to three trail bytes. The trail bytes encode a remaining "moduloModulo operation
In computing, the modulo operation finds the remainder of division of one number by another.Given two positive numbers, and , a modulo n can be thought of as the remainder, on division of a by n...
243" (base 243) difference, the lead byte determines the number of trail bytes and an initial difference.
Note that the reset byte
0xFF is not protected and can occur as trail byte.Patent
The general BOCU algorithm is covered by United States PatentUnited States patent law
United States patent law was established "to promote the Progress of Science and useful Arts, by securing for limited Times to Authors and Inventors the exclusive Right to their respective Writings and Discoveries;" as provided by the United States Constitution. Congress implemented these...
#6,737,994, which also mentions the specific BOCU-1 implementation. IBM
IBM
International Business Machines Corporation or IBM is an American multinational technology and consulting corporation headquartered in Armonk, New York, United States. IBM manufactures and sells computer hardware and software, and it offers infrastructure, hosting and consulting services in areas...
, which employed both of the inventors of BOCU-1 at the time it was created, states in the Unicode Technical Note that implementers of a "fully compliant version of BOCU-1" must contact IBM to request a royalty-free license. BOCU-1 is the only Unicode compression scheme described on the Unicode Web site that is known to be encumbered with intellectual property
Intellectual property
Intellectual property is a term referring to a number of distinct types of creations of the mind for which a set of exclusive rights are recognized—and the corresponding fields of law...
restrictions.
By contrast, IBM also filed for a patent on UTF-EBCDIC
UTF-EBCDIC
UTF-EBCDIC is a character encoding used to represent Unicode characters. It is meant to be EBCDIC-friendly, so that legacy EBCDIC applications on mainframes may process the characters without much difficulty. Its advantages for existing EBCDIC-based systems are similar to UTF-8's advantages for...
, but it chose in that case to make the documentation and encoding scheme “freely available to anyone concerned towards making the transformation format as part of the UCS standards,” instead of requiring implementers to request a license.
See also
- UTF-1UTF-1UTF-1 is a way of transforming ISO 10646/Unicode into a stream of bytes. Due to the design it is not possible to resynchronise if decoding starts in the middle of a character and simple byte-oriented search routines cannot be reliably used with it. UTF-1 is also fairly slow due to its use of...
contains a comparison of the UTF-1, UTF-8UTF-8UTF-8 is a multibyte character encoding for Unicode. Like UTF-16 and UTF-32, UTF-8 can represent every character in the Unicode character set. Unlike them, it is backward-compatible with ASCII and avoids the complications of endianness and byte order marks...
, and BOCU-1 designs - International Components for UnicodeInternational Components for UnicodeInternational Components for Unicode is an open source project of mature C/C++ and Java libraries for Unicode support, software internationalization and software globalization. ICU is widely portable to many operating systems and environments. It gives applications the same results on all...
A library that can convert between BOCU-1 and other Unicode encodings