
Twisting properties
Encyclopedia
Starting with a sample  observed from a random variable
observed from a random variable
X having a given distribution law
with a non-set parameter, a parametric inference
problem consists of computing suitable values – call them estimates
– of this parameter precisely on the basis of the sample. An estimate is suitable if replacing it with the unknown parameter does not cause major damage in next computations. In algorithmic inference
, suitability of an estimate reads in terms of compatibility with the observed sample.
In turn, parameter compatibility is a probability measure that we derive from the probability distribution of the random variable to which the parameter refers. In this way we identify a random parameter Θ compatible with an observed sample.
Given a sampling mechanism , the rationale of this operation lies in using the Z seed distribution law to determine both the X distribution law for the given θ, and the Θ distribution law given an X sample. Hence, we may derive the latter distribution directly from the former if we are able to relate domains of the sample space to subsets of Θ support
, the rationale of this operation lies in using the Z seed distribution law to determine both the X distribution law for the given θ, and the Θ distribution law given an X sample. Hence, we may derive the latter distribution directly from the former if we are able to relate domains of the sample space to subsets of Θ support
. In more abstract terms, we speak about twisting properties of samples with properties of parameters and identify the former with statistics that are suitable for this exchange, so denoting a well behavior w.r.t. the unknown parameters. The operational goal is to write the analytic expression of the cumulative distribution function
 , in light of the observed value s of a statistic S, as a function of the S distribution law when the X parameter is exactly θ.
, in light of the observed value s of a statistic S, as a function of the S distribution law when the X parameter is exactly θ.
 for the random variable X, we model
for the random variable X, we model  to be equal to
to be equal to  . Focusing on a relevant statistic
. Focusing on a relevant statistic  for the parameterθ, the master equation reads
for the parameterθ, the master equation reads
 .
.
When s is a well-behaved statistic
w.r.t the parameter, we are sure that a monotone relation exists for each between s and θ. We are also assured that Θ, as a function of
between s and θ. We are also assured that Θ, as a function of  for given s, is a random variable since the master equation provides solutions that are feasible and independent of other (hidden) parameters .
for given s, is a random variable since the master equation provides solutions that are feasible and independent of other (hidden) parameters .
The direction of the monotony determines for any a relation between events of the type
a relation between events of the type  or vice versa
or vice versa  , where
, where  is computed by the master equation with
is computed by the master equation with  . In the case that s assumes discrete values the first relation changes into
. In the case that s assumes discrete values the first relation changes into  where
where  is the size of the s discretization grain, idem with the opposite monotony trend. Resuming these relations on all seeds, for s continuous we have either
is the size of the s discretization grain, idem with the opposite monotony trend. Resuming these relations on all seeds, for s continuous we have either

or

For s discrete we have an interval where lies, because of
lies, because of  .
.
The whole logical contrivance is called a twisting argument. A procedure implementing it is as follows.
of parameters . Also Fraser’s constructive probabilities devised for the same purpose do not treat this point completely.
 drawn from a Gamma distribution, whose specification requires values for the parameters λ and k, a twisting argument may be stated by following the below procedure. Given the meaning of these parameters we know that
drawn from a Gamma distribution, whose specification requires values for the parameters λ and k, a twisting argument may be stated by following the below procedure. Given the meaning of these parameters we know that
where and
and  . This leads to a
. This leads to a
joint cumulative distribution function .
.
Using the first factorization and replacing with
with  in order to have a distribution of
in order to have a distribution of  that is independent of
that is independent of  , we have
, we have

with m denoting the sample size, and
and  are the observed statistics (hence with indices denoted by capital letters),
are the observed statistics (hence with indices denoted by capital letters),  the Incomplete Gamma function
the Incomplete Gamma function
and the Fox's H function that can be approximated with a Gamma distribution again with proper parameters (for instance estimated through the method of moments) as a function of k and m.
the Fox's H function that can be approximated with a Gamma distribution again with proper parameters (for instance estimated through the method of moments) as a function of k and m.
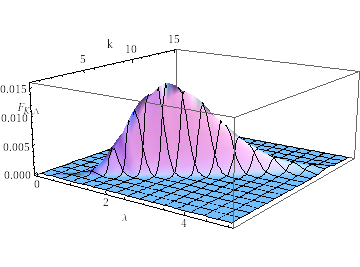
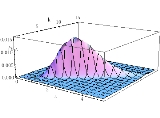
 With a sample size
With a sample size  and
and 
 , you may find the joint p.d.f. of the Gamma parameters K and
, you may find the joint p.d.f. of the Gamma parameters K and  on the left. The marginal distribution of K is reported in the picture on the right.
on the left. The marginal distribution of K is reported in the picture on the right.
observed from a random variableRandom variable
In probability and statistics, a random variable or stochastic variable is, roughly speaking, a variable whose value results from a measurement on some type of random process. Formally, it is a function from a probability space, typically to the real numbers, which is measurable functionmeasurable...
X having a given distribution law
Cumulative distribution function
In probability theory and statistics, the cumulative distribution function , or just distribution function, describes the probability that a real-valued random variable X with a given probability distribution will be found at a value less than or equal to x. Intuitively, it is the "area so far"...
with a non-set parameter, a parametric inference
Parametric statistics
Parametric statistics is a branch of statistics that assumes that the data has come from a type of probability distribution and makes inferences about the parameters of the distribution. Most well-known elementary statistical methods are parametric....
problem consists of computing suitable values – call them estimates
Estimator
In statistics, an estimator is a rule for calculating an estimate of a given quantity based on observed data: thus the rule and its result are distinguished....
– of this parameter precisely on the basis of the sample. An estimate is suitable if replacing it with the unknown parameter does not cause major damage in next computations. In algorithmic inference
Algorithmic inference
Algorithmic inference gathers new developments in the statistical inference methods made feasible by the powerful computing devices widely available to any data analyst...
, suitability of an estimate reads in terms of compatibility with the observed sample.
In turn, parameter compatibility is a probability measure that we derive from the probability distribution of the random variable to which the parameter refers. In this way we identify a random parameter Θ compatible with an observed sample.
Given a sampling mechanism
, the rationale of this operation lies in using the Z seed distribution law to determine both the X distribution law for the given θ, and the Θ distribution law given an X sample. Hence, we may derive the latter distribution directly from the former if we are able to relate domains of the sample space to subsets of Θ supportSupport (mathematics)
In mathematics, the support of a function is the set of points where the function is not zero, or the closure of that set . This concept is used very widely in mathematical analysis...
. In more abstract terms, we speak about twisting properties of samples with properties of parameters and identify the former with statistics that are suitable for this exchange, so denoting a well behavior w.r.t. the unknown parameters. The operational goal is to write the analytic expression of the cumulative distribution function
Cumulative distribution function
In probability theory and statistics, the cumulative distribution function , or just distribution function, describes the probability that a real-valued random variable X with a given probability distribution will be found at a value less than or equal to x. Intuitively, it is the "area so far"...
, in light of the observed value s of a statistic S, as a function of the S distribution law when the X parameter is exactly θ.Method
Given a sampling mechanism for the random variable X, we model to be equal to . Focusing on a relevant statistic for the parameterθ, the master equation reads.When s is a well-behaved statistic
Well-behaved statistic
A well-behaved statistic is a term sometimes used in the theory of statistics to describe part of a procedure. This usage is broadly similar to the use of well-behaved in more general mathematics...
w.r.t the parameter, we are sure that a monotone relation exists for each
between s and θ. We are also assured that Θ, as a function of for given s, is a random variable since the master equation provides solutions that are feasible and independent of other (hidden) parameters .The direction of the monotony determines for any
a relation between events of the type or vice versa , where is computed by the master equation with . In the case that s assumes discrete values the first relation changes into where is the size of the s discretization grain, idem with the opposite monotony trend. Resuming these relations on all seeds, for s continuous we have eitheror
For s discrete we have an interval where
lies, because of .The whole logical contrivance is called a twisting argument. A procedure implementing it is as follows.
Algorithm
| Generating a parameter distribution law through a twisting argument |
|---|
from a random variable with parameter θ unknown,
|
 (if any);
(if any); where:
where:

 if s does not decrease with θ
if s does not decrease with θ if s does not increase with θ and
if s does not increase with θ and if s does not decrease with θ and
if s does not decrease with θ and  if s does not increase with θ for
if s does not increase with θ for  .
.Remark
The rationale behind twisting arguments does not change when parameters are vectors, though some complication arises from the management of joint inequalities. Instead, the difficulty of dealing with a vector of parameters proved to be the Achilles heel of Fisher's approach to the fiducial distributionFiducial inference
Fiducial inference is one of a number of different types of statistical inference. These are rules, intended for general application, by which conclusions can be drawn from samples of data. In modern statistical practice, attempts to work with fiducial inference have fallen out of fashion in...
of parameters . Also Fraser’s constructive probabilities devised for the same purpose do not treat this point completely.
Example
For drawn from a Gamma distribution, whose specification requires values for the parameters λ and k, a twisting argument may be stated by following the below procedure. Given the meaning of these parameters we know that  |
for fixed λ, and |
 |
for fixed k |
where
and . This leads to ajoint cumulative distribution function
.Using the first factorization and replacing
with in order to have a distribution of that is independent of , we havewith m denoting the sample size,
and are the observed statistics (hence with indices denoted by capital letters), the Incomplete Gamma functionIncomplete gamma function
In mathematics, the gamma function is defined by a definite integral. The incomplete gamma function is defined as an integral function of the same integrand. There are two varieties of the incomplete gamma function: the upper incomplete gamma function is for the case that the lower limit of...
and
the Fox's H function that can be approximated with a Gamma distribution again with proper parameters (for instance estimated through the method of moments) as a function of k and m. and , you may find the joint p.d.f. of the Gamma parameters K and on the left. The marginal distribution of K is reported in the picture on the right.