

Linear classifier
Encyclopedia
In the field of machine learning
, the goal of statistical classification is to use an object's characteristics to identify which class (or group) it belongs to. A linear classifier achieves this by making a classification decision based on the value of a linear combination
of the characteristics. An object's characteristics are also known as feature values
and are typically presented to the machine in a vector called a feature vector
.
 If the input feature vector to the classifier is a real
If the input feature vector to the classifier is a real
vector , then the output score is
, then the output score is
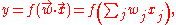
where is a real vector of weights and f is a function that converts the dot product
is a real vector of weights and f is a function that converts the dot product
of the two vectors into the desired output. (In other words, is a one-form
is a one-form
or linear functional
mapping onto R.) The weight vector
onto R.) The weight vector  is learned from a set of labeled training samples. Often f is a simple function that maps all values above a certain threshold to the first class and all other values to the second class. A more complex f might give the probability that an item belongs to a certain class.
is learned from a set of labeled training samples. Often f is a simple function that maps all values above a certain threshold to the first class and all other values to the second class. A more complex f might give the probability that an item belongs to a certain class.
For a two-class classification problem, one can visualize the operation of a linear classifier as splitting a high-dimensional input space with a hyperplane
: all points on one side of the hyperplane are classified as "yes", while the others are classified as "no".
A linear classifier is often used in situations where the speed of classification is an issue, since it is often the fastest classifier, especially when is sparse. However, decision tree
is sparse. However, decision tree
s can be faster. Also, linear classifiers often work very well when the number of dimensions in is large, as in document classification
is large, as in document classification
, where each element in is typically the number of occurrences of a word in a document (see document-term matrix
is typically the number of occurrences of a word in a document (see document-term matrix
). In such cases, the classifier should be well-regularized
.
 . Methods of the first class model conditional density functions
. Methods of the first class model conditional density functions
 . Examples of such algorithms include:
. Examples of such algorithms include:
The second set of methods includes discriminative model
s, which attempt to maximize the quality of the output on a training set
. Additional terms in the training cost function can easily perform regularization
of the final model. Examples of discriminative training of linear classifiers include
Note: Despite its name, LDA does not belong to the class of discriminative models in this taxonomy. However, its name makes sense when we compare LDA to the other main linear dimensionality reduction
algorithm: Principal Components Analysis
(PCA). LDA is a supervised learning
algorithm that utilizes the labels of the data, while PCA is an unsupervised learning
algorithm that ignores the labels. To summarize, the name is a historical artifact (see, p. 117).
Discriminative training often yields higher accuracy than modeling the conditional density functions. However, handling missing data is often easier with conditional density models.
All of the linear classifier algorithms listed above can be converted into non-linear algorithms operating on a different input space , using the kernel trick
, using the kernel trick
.
Machine learning
Machine learning, a branch of artificial intelligence, is a scientific discipline concerned with the design and development of algorithms that allow computers to evolve behaviors based on empirical data, such as from sensor data or databases...
, the goal of statistical classification is to use an object's characteristics to identify which class (or group) it belongs to. A linear classifier achieves this by making a classification decision based on the value of a linear combination
Linear combination
In mathematics, a linear combination is an expression constructed from a set of terms by multiplying each term by a constant and adding the results...
of the characteristics. An object's characteristics are also known as feature values
Features (pattern recognition)
In pattern recognition, features are the individual measurable heuristic properties of the phenomena being observed. Choosing discriminating and independent features is key to any pattern recognition algorithm being successful in classification...
and are typically presented to the machine in a vector called a feature vector
Feature vector
In pattern recognition and machine learning, a feature vector is an n-dimensional vector of numerical features that represent some object. Many algorithms in machine learning require a numerical representation of objects, since such representations facilitate processing andstatistical analysis...
.
Definition
Real number
In mathematics, a real number is a value that represents a quantity along a continuum, such as -5 , 4/3 , 8.6 , √2 and π...
vector
, then the output score iswhere
is a real vector of weights and f is a function that converts the dot productDot product
In mathematics, the dot product or scalar product is an algebraic operation that takes two equal-length sequences of numbers and returns a single number obtained by multiplying corresponding entries and then summing those products...
of the two vectors into the desired output. (In other words,
is a one-formOne-form
In linear algebra, a one-form on a vector space is the same as a linear functional on the space. The usage of one-form in this context usually distinguishes the one-forms from higher-degree multilinear functionals on the space. For details, see linear functional.In differential geometry, a...
or linear functional
Linear functional
In linear algebra, a linear functional or linear form is a linear map from a vector space to its field of scalars. In Rn, if vectors are represented as column vectors, then linear functionals are represented as row vectors, and their action on vectors is given by the dot product, or the...
mapping
onto R.) The weight vector is learned from a set of labeled training samples. Often f is a simple function that maps all values above a certain threshold to the first class and all other values to the second class. A more complex f might give the probability that an item belongs to a certain class.For a two-class classification problem, one can visualize the operation of a linear classifier as splitting a high-dimensional input space with a hyperplane
Hyperplane
A hyperplane is a concept in geometry. It is a generalization of the plane into a different number of dimensions.A hyperplane of an n-dimensional space is a flat subset with dimension n − 1...
: all points on one side of the hyperplane are classified as "yes", while the others are classified as "no".
A linear classifier is often used in situations where the speed of classification is an issue, since it is often the fastest classifier, especially when
is sparse. However, decision treeDecision tree learning
Decision tree learning, used in statistics, data mining and machine learning, uses a decision tree as a predictive model which maps observations about an item to conclusions about the item's target value. More descriptive names for such tree models are classification trees or regression trees...
s can be faster. Also, linear classifiers often work very well when the number of dimensions in
is large, as in document classificationDocument classification
Document classification or document categorization is a problem in both library science, information science and computer science. The task is to assign a document to one or more classes or categories. This may be done "manually" or algorithmically...
, where each element in
is typically the number of occurrences of a word in a document (see document-term matrixDocument-term matrix
A document-term matrix or term-document matrix is a mathematical matrix that describes the frequency of terms that occur in a collection of documents. In a document-term matrix, rows correspond to documents in the collection and columns correspond to terms. There are various schemes for determining...
). In such cases, the classifier should be well-regularized
Regularization (machine learning)
In statistics and machine learning, regularization is any method of preventing overfitting of data by a model. It is used for solving ill-conditioned parameter-estimation problems...
.
Generative models vs. discriminative models
There are two broad classes of methods for determining the parameters of a linear classifier. Methods of the first class model conditional density functionsConditional probability
In probability theory, the "conditional probability of A given B" is the probability of A if B is known to occur. It is commonly notated P, and sometimes P_B. P can be visualised as the probability of event A when the sample space is restricted to event B...
. Examples of such algorithms include:
- Linear Discriminant Analysis (or Fisher's linear discriminant)Linear discriminant analysisLinear discriminant analysis and the related Fisher's linear discriminant are methods used in statistics, pattern recognition and machine learning to find a linear combination of features which characterizes or separates two or more classes of objects or events...
(LDA)—assumes Gaussian conditional density models - Naive Bayes classifierNaive Bayes classifierA naive Bayes classifier is a simple probabilistic classifier based on applying Bayes' theorem with strong independence assumptions...
—assumes independent binomial conditional density models.
The second set of methods includes discriminative model
Discriminative model
Discriminative models are a class of models used in machine learning for modeling the dependence of an unobserved variable y on an observed variable x...
s, which attempt to maximize the quality of the output on a training set
Training set
A training set is a set of data used in various areas of information science to discover potentially predictive relationships. Training sets are used in artificial intelligence, machine learning, genetic programming, intelligent systems, and statistics...
. Additional terms in the training cost function can easily perform regularization
Regularization (machine learning)
In statistics and machine learning, regularization is any method of preventing overfitting of data by a model. It is used for solving ill-conditioned parameter-estimation problems...
of the final model. Examples of discriminative training of linear classifiers include
- Logistic regressionLogistic regressionIn statistics, logistic regression is used for prediction of the probability of occurrence of an event by fitting data to a logit function logistic curve. It is a generalized linear model used for binomial regression...
—maximum likelihood estimation of assuming that the observed training set was generated by a binomial model that depends on the output of the classifier.
assuming that the observed training set was generated by a binomial model that depends on the output of the classifier. - PerceptronPerceptronThe perceptron is a type of artificial neural network invented in 1957 at the Cornell Aeronautical Laboratory by Frank Rosenblatt. It can be seen as the simplest kind of feedforward neural network: a linear classifier.- Definition :...
—an algorithm that attempts to fix all errors encountered in the training set - Support vector machineSupport vector machineA support vector machine is a concept in statistics and computer science for a set of related supervised learning methods that analyze data and recognize patterns, used for classification and regression analysis...
—an algorithm that maximizes the marginMargin (machine learning)In machine learning the margin of a single data point is defined to be the distance from the data point to a decision boundary. Note that there are many distances and decision boundaries that may be appropriate for certain datasets and goals. A margin classifier is a classifier that explicitly...
between the decision hyperplane and the examples in the training set.
Note: Despite its name, LDA does not belong to the class of discriminative models in this taxonomy. However, its name makes sense when we compare LDA to the other main linear dimensionality reduction
Dimensionality reduction
In machine learning, dimension reduction is the process of reducing the number of random variables under consideration, and can be divided into feature selection and feature extraction.-Feature selection:...
algorithm: Principal Components Analysis
Principal components analysis
Principal component analysis is a mathematical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of uncorrelated variables called principal components. The number of principal components is less than or equal to...
(PCA). LDA is a supervised learning
Supervised learning
Supervised learning is the machine learning task of inferring a function from supervised training data. The training data consist of a set of training examples. In supervised learning, each example is a pair consisting of an input object and a desired output value...
algorithm that utilizes the labels of the data, while PCA is an unsupervised learning
Unsupervised learning
In machine learning, unsupervised learning refers to the problem of trying to find hidden structure in unlabeled data. Since the examples given to the learner are unlabeled, there is no error or reward signal to evaluate a potential solution...
algorithm that ignores the labels. To summarize, the name is a historical artifact (see, p. 117).
Discriminative training often yields higher accuracy than modeling the conditional density functions. However, handling missing data is often easier with conditional density models.
All of the linear classifier algorithms listed above can be converted into non-linear algorithms operating on a different input space
, using the kernel trickKernel trick
For machine learning algorithms, the kernel trick is a way of mapping observations from a general set S into an inner product space V , without ever having to compute the mapping explicitly, in the hope that the observations will gain meaningful linear structure in V...
.