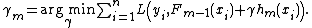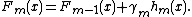Gradient boosting
Encyclopedia
Gradient boosting is a machine learning
technique for regression problems, which produces a prediction model in the form of an ensemble
of weak prediction models, typically decision tree
s. It builds the model in a stage-wise fashion like other boosting
methods do, and it generalizes them by allowing optimization of an arbitrary differentiable
loss function
. Gradient boosting method can be also used for classification problems by reducing them to regression with a suitable loss function.
The method was invented by Jerome H. Friedman in 1999 and was published in a series of two papers, the first of which introduced the method, and the second one described an important tweak to the algorithm, which improves its accuracy and performance.
problems one has an output variable y and a vector of input variables x connected together via a joint probability distribution P(x, y). Using a training set of known values of x and corresponding values of y, the goal is to find an approximation
of known values of x and corresponding values of y, the goal is to find an approximation 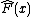 to a function
to a function  that minimizes the expected value of some specified loss function
that minimizes the expected value of some specified loss function
L(y, F(x)):
Gradient boosting method assumes a real-valued y and seeks an approximation in the form of a weighted sum of functions
in the form of a weighted sum of functions  from some class
from some class  , called base (or weak) learners:
, called base (or weak) learners:
In accordance with the empirical risk minimization
principle, the method tries to find an approximation that minimizes the average value of the loss function on the training set. It does so by starting with a model, consisting of a constant function
that minimizes the average value of the loss function on the training set. It does so by starting with a model, consisting of a constant function  , and incrementally expanding it in a greedy
, and incrementally expanding it in a greedy
fashion:
where f is restricted to be a function from the class of base learner functions.
of base learner functions.
However, the problem of choosing at each step the best f for an arbitrary loss function L is a hard optimization problem in general, and so we'll "cheat" by solving a much easier problem instead.
The idea is to apply a steepest descent step to this minimization problem. If we only cared about predictions at the points of the training set, and f were unrestricted, we'd update the model per the following equation, where we view L(y, f) not as a functional of f, but as a function of a vector of values :
:
Machine learning
Machine learning, a branch of artificial intelligence, is a scientific discipline concerned with the design and development of algorithms that allow computers to evolve behaviors based on empirical data, such as from sensor data or databases...
technique for regression problems, which produces a prediction model in the form of an ensemble
Ensemble learning
In statistics and machine learning, ensemble methods use multiple models to obtain better predictive performance than could be obtained from any of the constituent models....
of weak prediction models, typically decision tree
Decision tree
A decision tree is a decision support tool that uses a tree-like graph or model of decisions and their possible consequences, including chance event outcomes, resource costs, and utility. It is one way to display an algorithm. Decision trees are commonly used in operations research, specifically...
s. It builds the model in a stage-wise fashion like other boosting
Boosting
Boosting is a machine learning meta-algorithm for performing supervised learning. Boosting is based on the question posed by Kearns: can a set of weak learners create a single strong learner? A weak learner is defined to be a classifier which is only slightly correlated with the true classification...
methods do, and it generalizes them by allowing optimization of an arbitrary differentiable
Differentiable function
In calculus , a differentiable function is a function whose derivative exists at each point in its domain. The graph of a differentiable function must have a non-vertical tangent line at each point in its domain...
loss function
Loss function
In statistics and decision theory a loss function is a function that maps an event onto a real number intuitively representing some "cost" associated with the event. Typically it is used for parameter estimation, and the event in question is some function of the difference between estimated and...
. Gradient boosting method can be also used for classification problems by reducing them to regression with a suitable loss function.
The method was invented by Jerome H. Friedman in 1999 and was published in a series of two papers, the first of which introduced the method, and the second one described an important tweak to the algorithm, which improves its accuracy and performance.
Gradient boosting
In many supervised learningSupervised learning
Supervised learning is the machine learning task of inferring a function from supervised training data. The training data consist of a set of training examples. In supervised learning, each example is a pair consisting of an input object and a desired output value...
problems one has an output variable y and a vector of input variables x connected together via a joint probability distribution P(x, y). Using a training set
of known values of x and corresponding values of y, the goal is to find an approximation to a function that minimizes the expected value of some specified loss functionLoss function
In statistics and decision theory a loss function is a function that maps an event onto a real number intuitively representing some "cost" associated with the event. Typically it is used for parameter estimation, and the event in question is some function of the difference between estimated and...
L(y, F(x)):
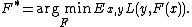
Gradient boosting method assumes a real-valued y and seeks an approximation
in the form of a weighted sum of functions from some class , called base (or weak) learners:
In accordance with the empirical risk minimization
Empirical risk minimization
Empirical risk minimization is a principle in statistical learning theory which defines a family of learning algorithms and is used to give theoretical bounds on the performance of learning algorithms.- Background :...
principle, the method tries to find an approximation
that minimizes the average value of the loss function on the training set. It does so by starting with a model, consisting of a constant function , and incrementally expanding it in a greedyGreedy algorithm
A greedy algorithm is any algorithm that follows the problem solving heuristic of making the locally optimal choice at each stagewith the hope of finding the global optimum....
fashion:
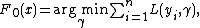

where f is restricted to be a function from the class
of base learner functions.However, the problem of choosing at each step the best f for an arbitrary loss function L is a hard optimization problem in general, and so we'll "cheat" by solving a much easier problem instead.
The idea is to apply a steepest descent step to this minimization problem. If we only cared about predictions at the points of the training set, and f were unrestricted, we'd update the model per the following equation, where we view L(y, f) not as a functional of f, but as a function of a vector of values
: 
-

But as f must come from a restricted class of functions (that's what allows us to generalize), we'll just choose the one that most closely approximates the gradient of L. Having chosen f, the multiplier γ is then selected using line search just as shown in the second equation above.
In pseudocode, the generic gradient boosting method is:
Input: training set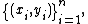 a differentiable loss function
a differentiable loss function 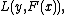 number of iterations
number of iterations 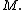
Algorithm:- Initialize model with a constant value:
-
- For m = 1 to M:
- Compute so-called pseudo-residuals:
-
- Fit a base learner
 to pseudo-residuals, i.e. train it using the training set
to pseudo-residuals, i.e. train it using the training set  .
. - Compute multiplier
 by solving the following one-dimensional optimization problem:
by solving the following one-dimensional optimization problem:
-
- Update the model:
-
- Compute so-called pseudo-residuals:
- Output

Gradient tree boosting
Gradient boosting is typically used with decision treeDecision treeA decision tree is a decision support tool that uses a tree-like graph or model of decisions and their possible consequences, including chance event outcomes, resource costs, and utility. It is one way to display an algorithm. Decision trees are commonly used in operations research, specifically...
s (especially CART trees) of a fixed size as base learners. For this special case Friedman proposes a modification to gradient boosting method which improves the quality of fit of each base learner.
Generic gradient boosting at the m-th step would fit a decision tree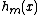 to pseudo-residuals. Let
to pseudo-residuals. Let 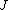 be the number of its leaves. The tree partitions the input space into
be the number of its leaves. The tree partitions the input space into  disjoint regions
disjoint regions  and predicts a constant value in each region. Using the indicator notation, the output of
and predicts a constant value in each region. Using the indicator notation, the output of  for input x can be written as the sum:
for input x can be written as the sum:
where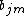 is the value predicted in the region
is the value predicted in the region  .
.
Then the coefficients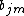 are multiplied by some value
are multiplied by some value  , chosen using line search so as to minimize the loss function, and the model is updated as follows:
, chosen using line search so as to minimize the loss function, and the model is updated as follows:
-

Friedman proposes to modify this algorithm so that it chooses a separate optimal value for each of the tree's regions, instead of a single
for each of the tree's regions, instead of a single  for the whole tree. He calls the modified algorithm "TreeBoost". The coefficients
for the whole tree. He calls the modified algorithm "TreeBoost". The coefficients  from the tree-fitting procedure can be then simply discarded and the model update rule becomes:
from the tree-fitting procedure can be then simply discarded and the model update rule becomes:
-

Size of trees
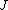 , the number of terminal nodes in trees, is the method's parameter which can be adjusted for a data set at hand. It controls the maximum allowed level of interactionInteraction (statistics)In statistics, an interaction may arise when considering the relationship among three or more variables, and describes a situation in which the simultaneous influence of two variables on a third is not additive...
, the number of terminal nodes in trees, is the method's parameter which can be adjusted for a data set at hand. It controls the maximum allowed level of interactionInteraction (statistics)In statistics, an interaction may arise when considering the relationship among three or more variables, and describes a situation in which the simultaneous influence of two variables on a third is not additive...
between variables in the model. With (decision stumpDecision stumpA decision stump is a machine learning model consisting of a one-level decision tree. That is, it is a decision tree with one internal node which is immediately connected to the terminal nodes. A decision stump makes a prediction based on the value of just a single input feature...
(decision stumpDecision stumpA decision stump is a machine learning model consisting of a one-level decision tree. That is, it is a decision tree with one internal node which is immediately connected to the terminal nodes. A decision stump makes a prediction based on the value of just a single input feature...
s), no interaction between variables is allowed. With the model may include effects of the interaction between up to two variables, and so on.
the model may include effects of the interaction between up to two variables, and so on.
Hastie et al. comment that typically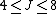 work well for boosting and results are fairly insensitive to the choice of
work well for boosting and results are fairly insensitive to the choice of  in this range,
in this range,  is insufficient for many applications, and
is insufficient for many applications, and  is unlikely to be required.
is unlikely to be required.
Regularization
Fitting the training set too closely can lead to degradation of the model's generalization ability. Several so-called regularizationRegularization (mathematics)In mathematics and statistics, particularly in the fields of machine learning and inverse problems, regularization involves introducing additional information in order to solve an ill-posed problem or to prevent overfitting...
techniques reduce this overfittingOverfittingIn statistics, overfitting occurs when a statistical model describes random error or noise instead of the underlying relationship. Overfitting generally occurs when a model is excessively complex, such as having too many parameters relative to the number of observations...
effect by constraining the fitting procedure.
One natural regularization parameter is the number of gradient boosting iterations M (i.e. the number of trees in the model when the base learner is a decision tree). Increasing M reduces the error on training set, but setting it too high may lead to overfitting. An optimal value of M is often selected by monitoring prediction error on a separate validation data set. Besides controlling M, several other regularization techniques are used.
Shrinkage
An important part of gradient boosting method is regularization by shrinkage which consists in modifying the update rule as follows:
where parameter is called the "learning rate".
is called the "learning rate".
Empirically it has been found that using small learning rates (such as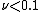 ) yields dramatic improvements in model's generalization ability over gradient boosting without shrinking (
) yields dramatic improvements in model's generalization ability over gradient boosting without shrinking (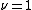 ).
).
However, it comes at the price of increasing computational time both during training and querying: lower learning rate requires more iterations.
Stochastic gradient boosting
Soon after the introduction of gradient boosting Friedman proposed a minor modification to the algorithm, motivated by BreimanLeo BreimanLeo Breiman was a distinguished statistician at the University of California, Berkeley. He was the recipient of numerous honors and awards, and was a member of the United States National Academy of Science....
's bagging method. Specifically, he proposed that at each iteration of the algorithm, a base learner should be fit on a subsample of the training set drawn at random without replacement. Friedman observed a substantional improvement in gradient boosting's accuracy with this modification.
Subsample size is some constant fraction f of the size of the training set. When f = 1, the algorithm is deterministic and identical to the one described above. Smaller values of f introduce randomness into the algorithm and help prevent overfittingOverfittingIn statistics, overfitting occurs when a statistical model describes random error or noise instead of the underlying relationship. Overfitting generally occurs when a model is excessively complex, such as having too many parameters relative to the number of observations...
, acting as a kind of regularizationRegularization (mathematics)In mathematics and statistics, particularly in the fields of machine learning and inverse problems, regularization involves introducing additional information in order to solve an ill-posed problem or to prevent overfitting...
. The algorithm also becomes faster, because regression trees have to be fit to smaller datasets at each iteration. Typically, f is set to 0.5, meaning that one half of the training set is used to build each base learner.
Also, like in bagging, subsampling allows one to define an out-of-bag estimate of the prediction performance improvement by evaluating predictions on those observations which were not used in the building of the next base learner. Out-of-bag estimates help avoid the need for an independent validation dataset, but often underestimate actual performance improvement and the optimal number of iterations.
Number of observations in leaves
Gradient tree boosting implementations often also use regularization by limiting the minimum number of observations in trees' terminal nodes (this parameter is calledn.minobsinnodeingbmpackage). It's used in the tree building process by ignoring any splits that lead to nodes containing fewer than this number of training set instances.
Imposing this limit helps to reduce variance in predictions at leaves.
Usage
Recently, gradient boosting method has gained some popularity in learning to rankLearning to rankLearning to rank or machine-learned ranking is a type of supervised or semi-supervised machine learning problem in which the goal is to automatically construct a ranking model from training data. Training data consists of lists of items with some partial order specified between items in each list...
field. Commercial web search engines Yahoo and YandexYandexYandex is a Russian IT company which operates the largest search engine in Russia and develops a number of Internet-based services and products. Yandex is ranked as 5-th world largest search engine...
use variants of gradient boosting method in their machine-learned ranking engines.
Names
The method goes by a wild variety of names. Title of the original publication refers to it as a "Gradient Boosting Machine" (GBM). That same publication and a later one by J. Friedman also use the names "Gradient Boost", "Stochastic Gradient Boosting" (emphasizing the random subsampling technique), "Gradient Tree Boosting" and "TreeBoost" (for specialization of the method to the case of decision trees as base learners.)
A popular open-source implementation calls it "Generalized Boosting Model". Sometimes the method is referred to as "functional gradient boosting", "Gradient Boosted Models" and its tree version is also called "Gradient Boosted Decision Trees" (GBDT) or "Gradient Boosted Regression Trees" (GBRT). Commercial implementations from Salford Systems use the names "Multiple Additive Regression Trees" (MART) and TreeNet, both trademarked.
Software
Open-source- Several open-source RR (programming language)R is a programming language and software environment for statistical computing and graphics. The R language is widely used among statisticians for developing statistical software, and R is widely used for statistical software development and data analysis....
packages are available:gbm,mboost,gbev. - WekaWeka (machine learning)Weka is a popular suite of machine learning software written in Java, developed at the University of Waikato, New Zealand...
has an incomplete implementation inweka.classifiers.meta.AdditiveRegression. - elf-project
- TMVA: Toolkit for Multivariate Data Analysis
- RT-Rank: Large Scale Multi-Threaded C++ Implementation of Gradient Boosting
- OpenCVOpenCVOpenCV is a library of programming functions mainly aimed at real time computer vision, developed by Intel and now supported by Willow Garage. It is free for use under the open source BSD license. The library is cross-platform. It focuses mainly on real-time image processing...
contains the implementation since the version 2.2 - pGBRT: C++/MPI-based parallel/distributed implementation, released September 2011
Proprietary- TreeNet is a commercial implementation from Salford Systems, possibly "equipped with patent-pending extensions."
- DTREG TreeBoost
- An implementation of stochastic gradient boosting is available in STATISTICASTATISTICASTATISTICA is a statistics and analytics software package developed by StatSoft. STATISTICA provides data analysis, data management, data mining, and data visualization procedures...
. - Yahoo and GoogleGoogleGoogle Inc. is an American multinational public corporation invested in Internet search, cloud computing, and advertising technologies. Google hosts and develops a number of Internet-based services and products, and generates profit primarily from advertising through its AdWords program...
have published papers describing an MPIMessage Passing InterfaceMessage Passing Interface is a standardized and portable message-passing system designed by a group of researchers from academia and industry to function on a wide variety of parallel computers...
- and a MapReduceMapReduceMapReduce is a software framework introduced by Google in 2004 to support distributed computing on large data sets on clusters of computers. Parts of the framework are patented in some countries....
-based parallel implementations of gradient boosting. However, they have not made the code publicly available.
-
-
- Initialize model with a constant value: