

Overfitting
Encyclopedia
Statistics
Statistics is the study of the collection, organization, analysis, and interpretation of data. It deals with all aspects of this, including the planning of data collection in terms of the design of surveys and experiments....
, overfitting occurs when a statistical model
Statistical model
A statistical model is a formalization of relationships between variables in the form of mathematical equations. A statistical model describes how one or more random variables are related to one or more random variables. The model is statistical as the variables are not deterministically but...
describes random error
Random error
Random errors are errors in measurement that lead to measurable values being inconsistent when repeated measures of a constant attribute or quantity are taken...
or noise instead of the underlying relationship. Overfitting generally occurs when a model is excessively complex, such as having too many parameters relative to the number of observations. A model which has been overfit will generally have poor predictive
Predictive inference
Predictive inference is an approach to statistical inference that emphasizes the prediction of future observations based on past observations.Initially, predictive inference was based on observable parameters and it was the main purpose of studying probability, but it fell out of favor in the 20th...
performance, as it can exaggerate minor fluctuations in the data.
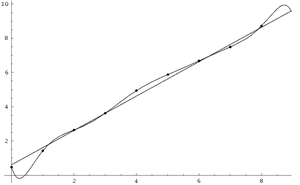
The possibility of overfitting exists because the criterion used for training the model is not the same as the criterion used to judge the efficacy of a model. In particular, a model is typically trained by maximizing its performance on some set of training data. However, its efficacy is determined not by its performance on the training data but by its ability to perform well on unseen data. Overfitting occurs when a model begins to memorize training data rather than learning to generalize from trend. As an extreme example, if the number of parameters is the same as or greater than the number of observations, a simple model can learn to perfectly predict the training data simply by memorizing the training data in its entirety. Such a model will typically fail drastically on unseen data, as it has not learned to generalize at all.
The potential for overfitting depends not only on the number of parameters and data but also the conformability of the model structure with the data shape, and the magnitude of model error compared to the expected level of noise or error in the data.
Even when the fitted model does not have an excessive number of parameters, it is to be expected that the fitted relationship will appear to perform less well on a new data set than on the data set used for fitting. In particular, the value of the coefficient of determination
Coefficient of determination
In statistics, the coefficient of determination R2 is used in the context of statistical models whose main purpose is the prediction of future outcomes on the basis of other related information. It is the proportion of variability in a data set that is accounted for by the statistical model...
will shrink
Shrinkage (statistics)
In statistics, shrinkage has two meanings:*In relation to the general observation that, in regression analysis, a fitted relationship appears to perform less well on a new data set than on the data set used for fitting. In particular the value of the coefficient of determination 'shrinks'...
relative to the original training data.
In order to avoid overfitting, it is necessary to use additional techniques (e.g. cross-validation, regularization
Regularization (mathematics)
In mathematics and statistics, particularly in the fields of machine learning and inverse problems, regularization involves introducing additional information in order to solve an ill-posed problem or to prevent overfitting...
, early stopping
Early stopping
In machine learning, early stopping is a form of regularization used when a machine learning model is trained by on-line gradient descent. In early stopping, the training set is split into a new training set and a validation set. Gradient descent is applied to the new training set...
, pruning
Pruning (algorithm)
Pruning is a technique in machine learning that reduces the size of decision trees by removing sections of the tree that provide little power to classify instances...
, Bayesian priors on parameters or model comparison), that can indicate when further training is not resulting in better generalization. The basis of some techniques is either (1) to explicitly penalize overly complex models, or (2) to test the model's ability to generalize by evaluating its performance on a set of data not used for training, which is assumed to approximate the typical unseen data that a model will encounter.
Machine learning
Machine learning
Machine learning, a branch of artificial intelligence, is a scientific discipline concerned with the design and development of algorithms that allow computers to evolve behaviors based on empirical data, such as from sensor data or databases...
. Usually a learning algorithm
Algorithm
In mathematics and computer science, an algorithm is an effective method expressed as a finite list of well-defined instructions for calculating a function. Algorithms are used for calculation, data processing, and automated reasoning...
is trained using some set of training examples, i.e. exemplary situations for which the desired output is known. The learner is assumed to reach a state where it will also be able to predict the correct output for other examples, thus generalizing to situations not presented during training (based on its inductive bias
Inductive bias
The inductive bias of a learning algorithm is the set of assumptions that the learner uses to predict outputs given inputs that it has not encountered ....
). However, especially in cases where learning was performed too long or where training examples are rare, the learner may adjust to very specific random features of the training data, that have no causal relation to the target function
Function approximation
The need for function approximations arises in many branches of applied mathematics, and computer science in particular. In general, a function approximation problem asks us to select a function among a well-defined class that closely matches a target function in a task-specific way.One can...
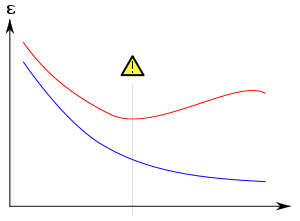
. In this process of overfitting, the performance on the training examples still increases while the performance on unseen data becomes worse.
As a simple example, consider a database of retail purchases that includes the item bought, the purchaser, and the date and time of purchase. It's easy to construct a model that will fit the training set perfectly by using the date and time of purchase to predict the other attributes; but this model will not generalize at all to new data, because those past times will never occur again.
Generally, a learning algorithm is said to overfit relative to a simpler one if it is more accurate in fitting known data (hindsight) but less accurate in predicting new data (foresight). One can intuitively understand overfitting from the fact that information from all past experience can be divided into two groups: information that is relevant for the future and irrelevant information (“noise”). Everything else being equal, the more difficult a criterion is to predict (i.e., the higher its uncertainty), the more noise exists in past information that need to be ignored. The problem is determining which part to ignore. A learning algorithm that can reduce the chance of fitting noise is called robust.
External links
- Overfitting: when accuracy measure goes wrong - an introductory video tutorial
- http://www.cs.sunysb.edu/~skiena/jaialai/excerpts/node16.html
- Overtraining
- Tetko, I.V.; Livingstone, D.J.; Luik, A.I. Neural network studies. 1. Comparison of Overfitting and Overtraining, J. Chem. Inf. Comput. Sci., 1995, 35, 826-833