In
probability theoryProbability theory is the branch of mathematics concerned with analysis of random phenomena. The central objects of probability theory are random variables, stochastic processes, and events: mathematical abstractions of non-deterministic events or measured quantities that may either be single...
and
statisticsStatistics is the study of the collection, organization, analysis, and interpretation of data. It deals with all aspects of this, including the planning of data collection in terms of the design of surveys and experiments....
, a
covariance matrix (also known as
dispersion matrix) is a
matrixIn mathematics, a matrix is a rectangular array of numbers, symbols, or expressions. The individual items in a matrix are called its elements or entries. An example of a matrix with six elements isMatrices of the same size can be added or subtracted element by element...
whose element in the
i,
j position is the
covarianceIn probability theory and statistics, covariance is a measure of how much two variables change together. Variance is a special case of the covariance when the two variables are identical.- Definition :...
between the
i th and
j th elements of a random vector (that is, of a vector of
random variableIn probability and statistics, a random variable or stochastic variable is, roughly speaking, a variable whose value results from a measurement on some type of random process. Formally, it is a function from a probability space, typically to the real numbers, which is measurable functionmeasurable...
s). Each element of the vector is a
scalarIn linear algebra, real numbers are called scalars and relate to vectors in a vector space through the operation of scalar multiplication, in which a vector can be multiplied by a number to produce another vector....
random variable, either with a finite number of observed empirical values or with a finite or infinite number of potential values specified by a theoretical joint probability distribution of all the random variables.
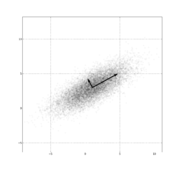
Intuitively, the covariance matrix generalizes the notion of
varianceIn probability theory and statistics, the variance is a measure of how far a set of numbers is spread out. It is one of several descriptors of a probability distribution, describing how far the numbers lie from the mean . In particular, the variance is one of the moments of a distribution...
to multiple dimensions. As an example, the variation in a collection of random points in two-dimensional space cannot be characterized fully by a single number, nor would the variances in the
x and
y directions contain all of the necessary information; a 2×2 matrix would be necessary to fully characterize the two-dimensional variation.
Analogous to the fact that it is necessary to build a
Hessian matrixIn mathematics, the Hessian matrix is the square matrix of second-order partial derivatives of a function; that is, it describes the local curvature of a function of many variables. The Hessian matrix was developed in the 19th century by the German mathematician Ludwig Otto Hesse and later named...
to fully describe the concavity of a multivariate function, a covariance matrix is necessary to fully describe the variation in a distribution.
Definition
Throughout this article, boldfaced unsubscripted
X and
Y are used to refer to random vectors, and unboldfaced subscripted X
i and Y
i are used to refer to random scalars. If the entries in the
column vector
are
random variableIn probability and statistics, a random variable or stochastic variable is, roughly speaking, a variable whose value results from a measurement on some type of random process. Formally, it is a function from a probability space, typically to the real numbers, which is measurable functionmeasurable...
s, each with finite
varianceIn probability theory and statistics, the variance is a measure of how far a set of numbers is spread out. It is one of several descriptors of a probability distribution, describing how far the numbers lie from the mean . In particular, the variance is one of the moments of a distribution...
, then the covariance matrix Σ is the matrix whose (
i,
j) entry is the
covarianceIn probability theory and statistics, covariance is a measure of how much two variables change together. Variance is a special case of the covariance when the two variables are identical.- Definition :...
where
NEWLINE
NEWLINE-
NEWLINE
\mu_i = \mathrm{E}(X_i)\,
is the
expected valueIn probability theory, the expected value of a random variable is the weighted average of all possible values that this random variable can take on...
of the
ith entry in the vector
X. In other words, we have
NEWLINE
NEWLINE-
NEWLINE
\Sigma \begin{bmatrix}
\mathrm{E}[(X_1 - \mu_1)(X_1 - \mu_1)] & \mathrm{E}[(X_1 - \mu_1)(X_2 - \mu_2)] & \cdots & \mathrm{E}[(X_1 - \mu_1)(X_n - \mu_n)] \\ \\
\mathrm{E}[(X_2 - \mu_2)(X_1 - \mu_1)] & \mathrm{E}[(X_2 - \mu_2)(X_2 - \mu_2)] & \cdots & \mathrm{E}[(X_2 - \mu_2)(X_n - \mu_n)] \\ \\
\vdots & \vdots & \ddots & \vdots \\ \\
\mathrm{E}[(X_n - \mu_n)(X_1 - \mu_1)] & \mathrm{E}[(X_n - \mu_n)(X_2 - \mu_2)] & \cdots & \mathrm{E}[(X_n - \mu_n)(X_n - \mu_n)]
\end{bmatrix}.
The inverse of this matrix,
, is the
inverse covariance matrix, also known as the
concentration matrix or
precision matrix. The elements of the precision matrix have an interpretation in terms of
partial correlationIn probability theory and statistics, partial correlation measures the degree of association between two random variables, with the effect of a set of controlling random variables removed.-Formal definition:...
s and partial variances.
Generalization of the variance
The definition above is equivalent to the matrix equality
This form can be seen as a generalization of the scalar-valued
varianceIn probability theory and statistics, the variance is a measure of how far a set of numbers is spread out. It is one of several descriptors of a probability distribution, describing how far the numbers lie from the mean . In particular, the variance is one of the moments of a distribution...
to higher dimensions. Recall that for a scalar-valued random variable
X