
Cache
Encyclopedia
In computer engineering
, a cache (icon ) is a component that transparently stores data so that future requests for that data can be served faster. The data that is stored within a cache might be values that have been computed earlier or duplicates of original values that are stored elsewhere. If requested data is contained in the cache (cache hit), this request can be served by simply reading the cache, which is comparatively faster. Otherwise (cache miss), the data has to be recomputed or fetched from its original storage location, which is comparatively slower. Hence, the greater the number of requests that can be served from the cache, the faster the overall system performance becomes.
To be cost efficient and to enable an efficient use of data, caches are relatively small. Nevertheless, caches have proven themselves in many areas of computing because access patterns in typical computer applications
have locality of reference
. References exhibit temporal locality if data is requested again that has been recently requested already. References exhibit spatial locality if data is requested that is physically stored close to data that has been requested already.
of memory for temporary storage of data likely to be used again. CPUs and hard drives frequently use a cache, as do web browsers and web servers.
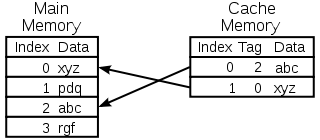
A cache is made up of a pool of entries. Each entry has a datum
(a nugget (piece) of data) - a copy of the same datum in some backing store. Each entry also has a tag, which specifies the identity of the datum in the backing store of which the entry is a copy.
When the cache client (a CPU, web browser, operating system
) needs to access a datum presumed to exist in the backing store, it first checks the cache. If an entry can be found with a tag matching that of the desired datum, the datum in the entry is used instead. This situation is known as a cache hit. So, for example, a web browser program might check its local cache on disk to see if it has a local copy of the contents of a web page at a particular URL. In this example, the URL is the tag, and the contents of the web page is the datum. The percentage of accesses that result in cache hits is known as the hit rate or hit ratio of the cache.
The alternative situation, when the cache is consulted and found not to contain a datum with the desired tag, has become known as a cache miss. The previously uncached datum fetched from the backing store during miss handling is usually copied into the cache, ready for the next access.
During a cache miss, the CPU usually ejects some other entry in order to make room for the previously uncached datum. The heuristic used to select the entry to eject is known as the replacement policy. One popular replacement policy, "least recently used" (LRU), replaces the least recently used entry (see cache algorithm). More efficient caches compute use frequency against the size of the stored contents, as well as the latencies
and throughputs for both the cache and the backing store. This works well for larger amounts of data, longer latencies and slower throughputs, such as experienced with a hard drive and the Internet, but is not efficient for use with a CPU cache.
When a system writes a datum to cache, it must at some point write that datum to backing store as well. The timing of this write is controlled by what is known as the write policy.
There are two basic writing approaches:
Write-back cache is more complex to implement, since it needs to track which of its locations have been written over, and mark them as dirty for later writing to the backing store. The data in these locations are written back to the backing store only when they are evicted from the cache, an effect referred to as a lazy write. For this reason, a read miss in a write-back cache (which requires a block to be replaced by another) will often require two memory accesses to service: one to write the replaced data from the cache back to the store, and then one to retrieve the needed datum.
Other policies may also trigger data write-back. The client may make many changes to a datum in the cache, and then explicitly notify the cache to write back the datum.
Since that on write operations, no actual data are needed back, there are two approaches for situations of write-misses:
Both write-through and write-back policies can use either of these write-miss policies, but usually they are paired in this way:
Entities other than the cache may change the data in the backing store, in which case the copy in the cache may become out-of-date or stale. Alternatively, when the client updates the data in the cache, copies of those data in other caches will become stale. Communication protocols between the cache managers which keep the data consistent are known as coherency protocols
.
in main memory, which is an example of disk cache, is managed by the operating system kernel.
While the hard drive's hardware disk buffer
is sometimes misleadingly referred to as "disk cache", its main functions are write sequencing and read prefetching. Repeated cache hits are relatively rare, due to the small size of the buffer in comparison to the drive's capacity. However, high-end disk controller
s often have their own on-board cache of hard disk data blocks
.
Finally, fast local hard disk can also cache information held on even slower data storage devices, such as remote servers (web cache
) or local tape drive
s or optical jukebox
es. Such a scheme is the main concept of hierarchical storage management
.
s and web proxy servers
employ web caches to store previous responses from web server
s, such as web page
s. Web caches reduce the amount of information that needs to be transmitted across the network, as information previously stored in the cache can often be re-used. This reduces bandwidth and processing requirements of the web server, and helps to improve responsiveness
for users of the web.
Web browsers employ a built-in web cache, but some internet service providers
or organizations also use a caching proxy server, which is a web cache that is shared among all users of that network.
Another form of cache is P2P caching
, where the files most sought for by peer-to-peer
applications are stored in an ISP cache to accelerate P2P transfers. Similarly, decentralised equivalents exist, which allow communities to perform the same task for P2P traffic, for example, Corelli.
daemon caches a mapping of domain names to IP address
es, as does a resolver library.
Write-through operation is common when operating over unreliable networks (like an Ethernet LAN), because of the enormous complexity of the coherency protocol
required between multiple write-back caches when communication is unreliable. For instance, web page caches and client-side
network file system
caches (like those in NFS or SMB
) are typically read-only or write-through specifically to keep the network protocol simple and reliable.
Search engine
s also frequently make web page
s they have indexed available from their cache. For example, Google
provides a "Cached" link next to each search result. This can prove useful when web pages from a web server
are temporarily or permanently inaccessible.
Another type of caching is storing computed results that will likely be needed again, or memoization
. ccache
, a program that caches the output of the compilation to speed up the second-time compilation, exemplifies this type.
Database caching
can substantially improve the throughput of database
applications, for example in the processing of indexes
, data dictionaries
, and frequently used subsets of data.
Distributed caching
uses caches spread across different networked hosts, for example, Corelli
A buffer is a temporary memory location that is traditionally used because CPU instructions cannot directly address data stored in peripheral devices. Thus, addressable memory is used as an intermediate stage. Additionally, such a buffer may be feasible when a large block of data is assembled or disassembled (as required by a storage device), or when data may be delivered in a different order than that in which it is produced. Also, a whole buffer of data is usually transferred sequentially (for example to hard disk), so buffering itself sometimes increases transfer performance or reduces the variation or jitter of the transfer's latency as opposed to caching where the intent is to reduce the latency. These benefits are present even if the buffered data are written to the buffer once and read from the buffer once.
A cache also increases transfer performance. A part of the increase similarly comes from the possibility that multiple small transfers will combine into one large block. But the main performance-gain occurs because there is a good chance that the same datum will be read from cache multiple times, or that written data will soon be read. A cache's sole purpose is to reduce accesses to the underlying slower storage. Cache is also usually an abstraction layer
that is designed to be invisible from the perspective of neighboring layers.
Computer engineering
Computer engineering, also called computer systems engineering, is a discipline that integrates several fields of electrical engineering and computer science required to develop computer systems. Computer engineers usually have training in electronic engineering, software design, and...
, a cache (icon ) is a component that transparently stores data so that future requests for that data can be served faster. The data that is stored within a cache might be values that have been computed earlier or duplicates of original values that are stored elsewhere. If requested data is contained in the cache (cache hit), this request can be served by simply reading the cache, which is comparatively faster. Otherwise (cache miss), the data has to be recomputed or fetched from its original storage location, which is comparatively slower. Hence, the greater the number of requests that can be served from the cache, the faster the overall system performance becomes.
To be cost efficient and to enable an efficient use of data, caches are relatively small. Nevertheless, caches have proven themselves in many areas of computing because access patterns in typical computer applications
Application software
Application software, also known as an application or an "app", is computer software designed to help the user to perform specific tasks. Examples include enterprise software, accounting software, office suites, graphics software and media players. Many application programs deal principally with...
have locality of reference
Locality of reference
In computer science, locality of reference, also known as the principle of locality, is the phenomenon of the same value or related storage locations being frequently accessed. There are two basic types of reference locality. Temporal locality refers to the reuse of specific data and/or resources...
. References exhibit temporal locality if data is requested again that has been recently requested already. References exhibit spatial locality if data is requested that is physically stored close to data that has been requested already.
Operation
Hardware implements cache as a blockBlock (data storage)
In computing , a block is a sequence of bytes or bits, having a nominal length . Data thus structured are said to be blocked. The process of putting data into blocks is called blocking. Blocking is used to facilitate the handling of the data-stream by the computer program receiving the data...
of memory for temporary storage of data likely to be used again. CPUs and hard drives frequently use a cache, as do web browsers and web servers.
A cache is made up of a pool of entries. Each entry has a datum
Datum
A geodetic datum is a reference from which measurements are made. In surveying and geodesy, a datum is a set of reference points on the Earth's surface against which position measurements are made, and an associated model of the shape of the earth to define a geographic coordinate system...
(a nugget (piece) of data) - a copy of the same datum in some backing store. Each entry also has a tag, which specifies the identity of the datum in the backing store of which the entry is a copy.
When the cache client (a CPU, web browser, operating system
Operating system
An operating system is a set of programs that manage computer hardware resources and provide common services for application software. The operating system is the most important type of system software in a computer system...
) needs to access a datum presumed to exist in the backing store, it first checks the cache. If an entry can be found with a tag matching that of the desired datum, the datum in the entry is used instead. This situation is known as a cache hit. So, for example, a web browser program might check its local cache on disk to see if it has a local copy of the contents of a web page at a particular URL. In this example, the URL is the tag, and the contents of the web page is the datum. The percentage of accesses that result in cache hits is known as the hit rate or hit ratio of the cache.
The alternative situation, when the cache is consulted and found not to contain a datum with the desired tag, has become known as a cache miss. The previously uncached datum fetched from the backing store during miss handling is usually copied into the cache, ready for the next access.
During a cache miss, the CPU usually ejects some other entry in order to make room for the previously uncached datum. The heuristic used to select the entry to eject is known as the replacement policy. One popular replacement policy, "least recently used" (LRU), replaces the least recently used entry (see cache algorithm). More efficient caches compute use frequency against the size of the stored contents, as well as the latencies
Access time
Access time is the time delay or latency between a request to an electronic system, and the access being completed or the requested data returned....
and throughputs for both the cache and the backing store. This works well for larger amounts of data, longer latencies and slower throughputs, such as experienced with a hard drive and the Internet, but is not efficient for use with a CPU cache.
Writing policies
When a system writes a datum to cache, it must at some point write that datum to backing store as well. The timing of this write is controlled by what is known as the write policy.
There are two basic writing approaches:
- Write-through - Write is done synchronously both to the cache and to the backing store.
- Write-back (or Write-behind) - Writing is done only to the cache. A modified cache block is written back to the store, just before it is replaced.
Write-back cache is more complex to implement, since it needs to track which of its locations have been written over, and mark them as dirty for later writing to the backing store. The data in these locations are written back to the backing store only when they are evicted from the cache, an effect referred to as a lazy write. For this reason, a read miss in a write-back cache (which requires a block to be replaced by another) will often require two memory accesses to service: one to write the replaced data from the cache back to the store, and then one to retrieve the needed datum.
Other policies may also trigger data write-back. The client may make many changes to a datum in the cache, and then explicitly notify the cache to write back the datum.
Since that on write operations, no actual data are needed back, there are two approaches for situations of write-misses:
- Write allocate (aka Fetch on write) - Datum at the missed-write location is loaded to cache, followed by a write-hit operation. In this approach, write misses are similar to read-misses.
- No-write allocate (aka Write-no-allocate, Write around) - Datum at the missed-write location is not loaded to cache, and is written directly to the backing store. In this approach, actually only system reads are being cached.
Both write-through and write-back policies can use either of these write-miss policies, but usually they are paired in this way:
- A write-back cache uses write allocate, hoping for a subsequent writes (or even reads) to the same location, which is now cached.
- A write-through cache uses no-write allocate. Here, subsequent writes have no advantage, since they still need to be written directly to the backing store.
Entities other than the cache may change the data in the backing store, in which case the copy in the cache may become out-of-date or stale. Alternatively, when the client updates the data in the cache, copies of those data in other caches will become stale. Communication protocols between the cache managers which keep the data consistent are known as coherency protocols
Cache coherency
In computing, cache coherence refers to the consistency of data stored in local caches of a shared resource.When clients in a system maintain caches of a common memory resource, problems may arise with inconsistent data. This is particularly true of CPUs in a multiprocessing system...
.
CPU cache
Small memories on or close to the CPU can operate faster than the much larger main memory. Most CPUs since the 1980s have used one or more caches, and modern high-end embedded, desktop and server microprocessors may have as many as half a dozen, each specialized for a specific function. Examples of caches with a specific function are the D-cache and I-cache (data cache and instruction cache).Disk cache
While CPU caches are generally managed entirely by hardware, a variety of software manages other caches. The page cachePage cache
In computing, page cache, sometimes ambiguously called disk cache, is a "transparent" buffer of disk-backed pages kept in main memory by the operating system for quicker access. Page cache is typically implemented in kernels with the paging memory management, and is completely transparent to...
in main memory, which is an example of disk cache, is managed by the operating system kernel.
While the hard drive's hardware disk buffer
Disk buffer
In computer storage, disk buffer is the embedded memory in a hard drive acting as a buffer between the rest of the computer and the physical hard disk platter that is used for storage...
is sometimes misleadingly referred to as "disk cache", its main functions are write sequencing and read prefetching. Repeated cache hits are relatively rare, due to the small size of the buffer in comparison to the drive's capacity. However, high-end disk controller
Disk controller
The disk controller is the circuit which enables the CPU to communicate with a hard disk, floppy disk or other kind of disk drive.Early disk controllers were identified by their storage methods and data encoding. They were typically implemented on a separate controller card...
s often have their own on-board cache of hard disk data blocks
Block (data storage)
In computing , a block is a sequence of bytes or bits, having a nominal length . Data thus structured are said to be blocked. The process of putting data into blocks is called blocking. Blocking is used to facilitate the handling of the data-stream by the computer program receiving the data...
.
Finally, fast local hard disk can also cache information held on even slower data storage devices, such as remote servers (web cache
Web cache
A web cache is a mechanism for the temporary storage of web documents, such as HTML pages and images, to reduce bandwidth usage, server load, and perceived lag...
) or local tape drive
Tape drive
A tape drive is a data storage device that reads and performs digital recording, writes data on a magnetic tape. Magnetic tape data storage is typically used for offline, archival data storage. Tape media generally has a favorable unit cost and long archival stability.A tape drive provides...
s or optical jukebox
Optical jukebox
An optical jukebox is a robotic data storage device that can automatically load and unload optical discs, such as Compact Disc, DVD, Ultra Density Optical or Blu-ray disc and can provide terabytes and petabytes of tertiary storage. The devices are often called optical disk libraries, robotic...
es. Such a scheme is the main concept of hierarchical storage management
Hierarchical storage management
Hierarchical storage management is a data storage technique which automatically moves data between high-cost and low-cost storage media. HSM systems exist because high-speed storage devices, such as hard disk drive arrays, are more expensive than slower devices, such as optical discs and magnetic...
.
Web cache
Web browserWeb browser
A web browser is a software application for retrieving, presenting, and traversing information resources on the World Wide Web. An information resource is identified by a Uniform Resource Identifier and may be a web page, image, video, or other piece of content...
s and web proxy servers
Proxy server
In computer networks, a proxy server is a server that acts as an intermediary for requests from clients seeking resources from other servers. A client connects to the proxy server, requesting some service, such as a file, connection, web page, or other resource available from a different server...
employ web caches to store previous responses from web server
Web server
Web server can refer to either the hardware or the software that helps to deliver content that can be accessed through the Internet....
s, such as web page
Web page
A web page or webpage is a document or information resource that is suitable for the World Wide Web and can be accessed through a web browser and displayed on a monitor or mobile device. This information is usually in HTML or XHTML format, and may provide navigation to other web pages via hypertext...
s. Web caches reduce the amount of information that needs to be transmitted across the network, as information previously stored in the cache can often be re-used. This reduces bandwidth and processing requirements of the web server, and helps to improve responsiveness
Responsiveness
Responsiveness as a concept of computer science refers to the specific ability of a functional unit to complete assigned tasks within a given time, but also may incorporate the ability of an artificial intelligence system to understand and carry out its tasks in a timely fashion. It is one of the...
for users of the web.
Web browsers employ a built-in web cache, but some internet service providers
Internet service provider
An Internet service provider is a company that provides access to the Internet. Access ISPs directly connect customers to the Internet using copper wires, wireless or fiber-optic connections. Hosting ISPs lease server space for smaller businesses and host other people servers...
or organizations also use a caching proxy server, which is a web cache that is shared among all users of that network.
Another form of cache is P2P caching
P2P caching
Peer-to-peer caching is a computer network traffic management technology used by Internet Service Providers to accelerate content delivered over peer-to-peer networks while reducing related bandwidth costs....
, where the files most sought for by peer-to-peer
Peer-to-peer
Peer-to-peer computing or networking is a distributed application architecture that partitions tasks or workloads among peers. Peers are equally privileged, equipotent participants in the application...
applications are stored in an ISP cache to accelerate P2P transfers. Similarly, decentralised equivalents exist, which allow communities to perform the same task for P2P traffic, for example, Corelli.
Other caches
The BIND DNSDomain name system
The Domain Name System is a hierarchical distributed naming system for computers, services, or any resource connected to the Internet or a private network. It associates various information with domain names assigned to each of the participating entities...
daemon caches a mapping of domain names to IP address
IP address
An Internet Protocol address is a numerical label assigned to each device participating in a computer network that uses the Internet Protocol for communication. An IP address serves two principal functions: host or network interface identification and location addressing...
es, as does a resolver library.
Write-through operation is common when operating over unreliable networks (like an Ethernet LAN), because of the enormous complexity of the coherency protocol
Cache coherency
In computing, cache coherence refers to the consistency of data stored in local caches of a shared resource.When clients in a system maintain caches of a common memory resource, problems may arise with inconsistent data. This is particularly true of CPUs in a multiprocessing system...
required between multiple write-back caches when communication is unreliable. For instance, web page caches and client-side
Client-side
Client-side refers to operations that are performed by the client in a client–server relationship in a computer network.Typically, a client is a computer application, such as a web browser, that runs on a user's local computer or workstation and connects to a server as necessary...
network file system
Network File System
Network File System is a network file system protocol originally developed by Sun Microsystems in 1984, allowing a user on a client computer to access files over a network in a manner similar to how local storage is accessed. NFS, like many other protocols, builds on the Open Network Computing...
caches (like those in NFS or SMB
Server Message Block
In computer networking, Server Message Block , also known as Common Internet File System operates as an application-layer network protocol mainly used to provide shared access to files, printers, serial ports, and miscellaneous communications between nodes on a network. It also provides an...
) are typically read-only or write-through specifically to keep the network protocol simple and reliable.
Search engine
Web search engine
A web search engine is designed to search for information on the World Wide Web and FTP servers. The search results are generally presented in a list of results often referred to as SERPS, or "search engine results pages". The information may consist of web pages, images, information and other...
s also frequently make web page
Web page
A web page or webpage is a document or information resource that is suitable for the World Wide Web and can be accessed through a web browser and displayed on a monitor or mobile device. This information is usually in HTML or XHTML format, and may provide navigation to other web pages via hypertext...
s they have indexed available from their cache. For example, Google
Google
Google Inc. is an American multinational public corporation invested in Internet search, cloud computing, and advertising technologies. Google hosts and develops a number of Internet-based services and products, and generates profit primarily from advertising through its AdWords program...
provides a "Cached" link next to each search result. This can prove useful when web pages from a web server
Web server
Web server can refer to either the hardware or the software that helps to deliver content that can be accessed through the Internet....
are temporarily or permanently inaccessible.
Another type of caching is storing computed results that will likely be needed again, or memoization
Memoization
In computing, memoization is an optimization technique used primarily to speed up computer programs by having function calls avoid repeating the calculation of results for previously processed inputs...
. ccache
Ccache
ccache is a software development tool that caches the output of C/C++ compilation so that the next time, the same compilation can be avoided and the results can be taken from the cache. This can greatly speed up recompiling time...
, a program that caches the output of the compilation to speed up the second-time compilation, exemplifies this type.
Database caching
Database caching
Many applications today are being developed and deployed on multi-tier environments that involve browser-based clients, web application servers and backend databases...
can substantially improve the throughput of database
Database
A database is an organized collection of data for one or more purposes, usually in digital form. The data are typically organized to model relevant aspects of reality , in a way that supports processes requiring this information...
applications, for example in the processing of indexes
Index (database)
A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of slower writes and increased storage space...
, data dictionaries
Data dictionary
A data dictionary, or metadata repository, as defined in the IBM Dictionary of Computing, is a "centralized repository of information about data such as meaning, relationships to other data, origin, usage, and format." The term may have one of several closely related meanings pertaining to...
, and frequently used subsets of data.
Distributed caching
uses caches spread across different networked hosts, for example, Corelli
The difference between buffer and cache
The terms "buffer" and "cache" are not mutually exclusive and the functions are frequently combined; however, there is a difference in intent.A buffer is a temporary memory location that is traditionally used because CPU instructions cannot directly address data stored in peripheral devices. Thus, addressable memory is used as an intermediate stage. Additionally, such a buffer may be feasible when a large block of data is assembled or disassembled (as required by a storage device), or when data may be delivered in a different order than that in which it is produced. Also, a whole buffer of data is usually transferred sequentially (for example to hard disk), so buffering itself sometimes increases transfer performance or reduces the variation or jitter of the transfer's latency as opposed to caching where the intent is to reduce the latency. These benefits are present even if the buffered data are written to the buffer once and read from the buffer once.
A cache also increases transfer performance. A part of the increase similarly comes from the possibility that multiple small transfers will combine into one large block. But the main performance-gain occurs because there is a good chance that the same datum will be read from cache multiple times, or that written data will soon be read. A cache's sole purpose is to reduce accesses to the underlying slower storage. Cache is also usually an abstraction layer
Abstraction layer
An abstraction layer is a way of hiding the implementation details of a particular set of functionality...
that is designed to be invisible from the perspective of neighboring layers.
See also
- Cache algorithmsCache algorithmsIn computing, cache algorithms are optimizing instructions – algorithms – that a computer program or a hardware-maintained structure can follow to manage a cache of information stored on the computer...
- Cache coherenceCache coherenceIn computing, cache coherence refers to the consistency of data stored in local caches of a shared resource.When clients in a system maintain caches of a common memory resource, problems may arise with inconsistent data. This is particularly true of CPUs in a multiprocessing system...
- Cache coloringCache coloringIn computer science, cache coloring is the process of attempting to allocate free pages that are contiguous from the CPU cache's point of view, in order to maximize the total number of pages cached by the processor...
- Cache-oblivious algorithm
- Cache stampedeCache stampedeA cache stampede is a type of cascading failure that can occur when massively parallel computing systems with caching mechanisms come under very high load. This behaviour is sometimes also called dog-piling....
- Cache language modelCache language modelA cache language model is a type of statistical language model. These occur in the natural language processing subfield of computer science and assign probabilities to given sequences of words by means of a probability distribution...
- CPU cacheCPU cacheA CPU cache is a cache used by the central processing unit of a computer to reduce the average time to access memory. The cache is a smaller, faster memory which stores copies of the data from the most frequently used main memory locations...
- Data grid
- Database cache
- Disk bufferDisk bufferIn computer storage, disk buffer is the embedded memory in a hard drive acting as a buffer between the rest of the computer and the physical hard disk platter that is used for storage...
(Hardware-based cache) - Cache manifest in HTML5
- Pipeline burst cache