
3D single object recognition
Encyclopedia
In computer vision
, 3D single object recognition
involves recognizing and determining the pose of user-chosen 3D
object in a photograph
or range scan. Typically, an example of the object to be recognized is presented to a vision system in a controlled environment, and then for an arbitrary input such as a video stream, the system locates the previously presented object. This can be done either off-line
, or in real-time
. The algorithms for solving this problem are specialized for locating a single pre-identified object, and can be contrasted with algorithms which operate on general classes
of objects, such as face recognition systems
or 3D generic object recognition. Due to the low cost and ease of acquiring photographs, a significant amount of research has been devoted to 3D object recognition in photographs.
objects consisting of a single part, that is, objects whose spatial transformation is a Euclidean motion. Two general approaches have been taken to the problem: pattern recognition
approaches use low-level image appearance information to locate an object, while feature-based geometric approaches construct a model for the object to be recognized, and match the model against the photograph.
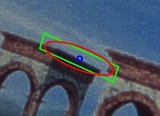
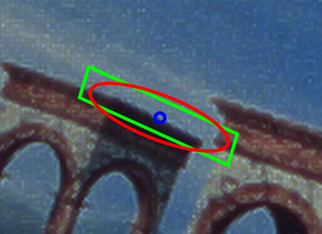 Feature-based approaches work well for objects which have distinctive features
Feature-based approaches work well for objects which have distinctive features
. Thus far, objects which have good edge features or blob
features have been successfully recognized; for example detection algorithms, see Harris affine region detector
and SIFT
, respectively. Due to lack of the appropriate feature detectors, objects without textured, smooth surfaces cannot currently be handled by this approach.
Feature-based object recognizers generally work by pre-capturing a number of fixed views of the object to be recognized, extracting features from these views, and then in the recognition process, matching these features to the scene and enforcing geometric constraints.
As an example of a prototypical system taking this approach, we will present an outline of the method used by [Rothganger et al. 2004], with some detail elided. The method starts by assuming that objects undergo globally rigid transformations. Because smooth surfaces are locally planar, affine invariant features are appropriate for matching: the paper detects ellipse-shaped regions of interest using both edge-like and blob-like features, and as per [Lowe 2004], finds the dominant gradient direction of the ellipse, converts the ellipse into a parallelogram, and takes a SIFT
descriptor on the resulting parallelogram. Color information is used also to improve discrimination over SIFT features alone.
 Next, given a number of camera views of the object (24 in the paper), the method constructs a 3D model for the object, containing the 3D spatial position and orientation of each feature. Because the number of views of the object is large, typically each feature is present in several adjacent views. The center points of such matching features correspond, and detected features are aligned along the dominant gradient direction, so the points at (1, 0) in the local coordinate system of the feature parallelogram also correspond, as do the points (0, 1) in the parallelogram's local coordinates. Thus for every pair of matching features in nearby views, three point pair correspondences are known. Given at least two matching features, a multi-view affine structure from motion
Next, given a number of camera views of the object (24 in the paper), the method constructs a 3D model for the object, containing the 3D spatial position and orientation of each feature. Because the number of views of the object is large, typically each feature is present in several adjacent views. The center points of such matching features correspond, and detected features are aligned along the dominant gradient direction, so the points at (1, 0) in the local coordinate system of the feature parallelogram also correspond, as do the points (0, 1) in the parallelogram's local coordinates. Thus for every pair of matching features in nearby views, three point pair correspondences are known. Given at least two matching features, a multi-view affine structure from motion
algorithm (see [Tomasi and Kanade 1992]) can be used to construct an estimate of points positions (up to an arbitrary affine transformation). The paper of Rothganger et al. therefore selects two adjacent views, uses a RANSAC
-like method to select two corresponding pairs of features, and adds new features to the partial model built by RANSAC so long as they are under an error term. Thus for any given pair of adjacent views, the algorithm creates a partial model of all features visible in both views.
 To produce a unified model, the paper takes the largest partial model, and incrementally aligns all smaller partial models to it. Global minimization is used to reduce the error, then a Euclidean upgrade is used to change the model's feature positions from 3D coordinates unique up to affine transformation to 3D coordinates that are unique up to Euclidean motion. At the end of this step, one has a model of the target object, consisting of features projected into a common 3D space.
To produce a unified model, the paper takes the largest partial model, and incrementally aligns all smaller partial models to it. Global minimization is used to reduce the error, then a Euclidean upgrade is used to change the model's feature positions from 3D coordinates unique up to affine transformation to 3D coordinates that are unique up to Euclidean motion. At the end of this step, one has a model of the target object, consisting of features projected into a common 3D space.
To recognize an object in an arbitrary input image, the paper detects features, and then uses RANSAC
to find the affine projection matrix which best fits the unified object model to the 2D scene. If this RANSAC approach has sufficiently low error, then on success, the algorithm both recognizes the object and gives the object's pose in terms of an affine projection. Under the assumed conditions, the method typically achieves recognition rates of around 95%.
Computer vision
Computer vision is a field that includes methods for acquiring, processing, analysing, and understanding images and, in general, high-dimensional data from the real world in order to produce numerical or symbolic information, e.g., in the forms of decisions...
, 3D single object recognition
Object recognition
Object recognition in computer vision is the task of finding a given object in an image or video sequence. Humans recognize a multitude of objects in images with little effort, despite the fact that the image of the objects may vary somewhat in different view points, in many different sizes / scale...
involves recognizing and determining the pose of user-chosen 3D
Three-dimensional space
Three-dimensional space is a geometric 3-parameters model of the physical universe in which we live. These three dimensions are commonly called length, width, and depth , although any three directions can be chosen, provided that they do not lie in the same plane.In physics and mathematics, a...
object in a photograph
Photograph
A photograph is an image created by light falling on a light-sensitive surface, usually photographic film or an electronic imager such as a CCD or a CMOS chip. Most photographs are created using a camera, which uses a lens to focus the scene's visible wavelengths of light into a reproduction of...
or range scan. Typically, an example of the object to be recognized is presented to a vision system in a controlled environment, and then for an arbitrary input such as a video stream, the system locates the previously presented object. This can be done either off-line
Off-line
The terms "online" and "offline" have specific meanings in regard to computer technology and telecommunications. In general, "online" indicates a state of connectivity, while "offline" indicates a disconnected state...
, or in real-time
Real-time computer graphics
Real-time computer graphics is the subfield of computer graphics focused on producing and analyzing images in real time. The term is most often used in reference to interactive 3D computer graphics, typically using a GPU, with video games the most noticeable users...
. The algorithms for solving this problem are specialized for locating a single pre-identified object, and can be contrasted with algorithms which operate on general classes
Class (computer science)
In object-oriented programming, a class is a construct that is used as a blueprint to create instances of itself – referred to as class instances, class objects, instance objects or simply objects. A class defines constituent members which enable these class instances to have state and behavior...
of objects, such as face recognition systems
Facial recognition system
A facial recognition system is a computer application for automatically identifying or verifying a person from a digital image or a video frame from a video source...
or 3D generic object recognition. Due to the low cost and ease of acquiring photographs, a significant amount of research has been devoted to 3D object recognition in photographs.
3D single object recognition in photographs
The method of recognizing a 3D object depends on the properties of an object. For simplicity, many existing algorithms have focused on recognizing rigidStiffness
Stiffness is the resistance of an elastic body to deformation by an applied force along a given degree of freedom when a set of loading points and boundary conditions are prescribed on the elastic body.-Calculations:...
objects consisting of a single part, that is, objects whose spatial transformation is a Euclidean motion. Two general approaches have been taken to the problem: pattern recognition
Pattern recognition
In machine learning, pattern recognition is the assignment of some sort of output value to a given input value , according to some specific algorithm. An example of pattern recognition is classification, which attempts to assign each input value to one of a given set of classes...
approaches use low-level image appearance information to locate an object, while feature-based geometric approaches construct a model for the object to be recognized, and match the model against the photograph.
Pattern recognition approaches
These methods use appearance information gathered from pre-captured or pre-computed projections of an object to match the object in the potentially cluttered scene. However, they do not take the 3D geometric constraints of the object into consideration during matching, and typically also do not handle occlusion as well as feature-based approaches. See [Murase and Nayar 1995] and [Selinger and Nelson 1999].Feature-based geometric approaches
Feature (Computer vision)
In computer vision and image processing the concept of feature is used to denote a piece of information which is relevant for solving the computational task related to a certain application...
. Thus far, objects which have good edge features or blob
Blob detection
In the area of computer vision, blob detection refers to visual modules that are aimed at detecting points and/or regions in the image that differ in properties like brightness or color compared to the surrounding...
features have been successfully recognized; for example detection algorithms, see Harris affine region detector
Harris affine region detector
In the fields of computer vision and image analysis, the Harris affine region detector belongs to the category of feature detection. Feature detection is a preprocessing step of several algorithms that rely on identifying characteristic points or interest points so to make correspondences between...
and SIFT
Scale-invariant feature transform
Scale-invariant feature transform is an algorithm in computer vision to detect and describe local features in images. The algorithm was published by David Lowe in 1999....
, respectively. Due to lack of the appropriate feature detectors, objects without textured, smooth surfaces cannot currently be handled by this approach.
Feature-based object recognizers generally work by pre-capturing a number of fixed views of the object to be recognized, extracting features from these views, and then in the recognition process, matching these features to the scene and enforcing geometric constraints.
As an example of a prototypical system taking this approach, we will present an outline of the method used by [Rothganger et al. 2004], with some detail elided. The method starts by assuming that objects undergo globally rigid transformations. Because smooth surfaces are locally planar, affine invariant features are appropriate for matching: the paper detects ellipse-shaped regions of interest using both edge-like and blob-like features, and as per [Lowe 2004], finds the dominant gradient direction of the ellipse, converts the ellipse into a parallelogram, and takes a SIFT
Scale-invariant feature transform
Scale-invariant feature transform is an algorithm in computer vision to detect and describe local features in images. The algorithm was published by David Lowe in 1999....
descriptor on the resulting parallelogram. Color information is used also to improve discrimination over SIFT features alone.
Structure from motion
In computer vision structure from motion refers to the process of finding the three-dimensional structure of an object by analyzing local motion signals over time....
algorithm (see [Tomasi and Kanade 1992]) can be used to construct an estimate of points positions (up to an arbitrary affine transformation). The paper of Rothganger et al. therefore selects two adjacent views, uses a RANSAC
RANSAC
RANSAC is an abbreviation for "RANdom SAmple Consensus". It is an iterative method to estimate parameters of a mathematical model from a set of observed data which contains outliers. It is a non-deterministic algorithm in the sense that it produces a reasonable result only with a certain...
-like method to select two corresponding pairs of features, and adds new features to the partial model built by RANSAC so long as they are under an error term. Thus for any given pair of adjacent views, the algorithm creates a partial model of all features visible in both views.
To recognize an object in an arbitrary input image, the paper detects features, and then uses RANSAC
RANSAC
RANSAC is an abbreviation for "RANdom SAmple Consensus". It is an iterative method to estimate parameters of a mathematical model from a set of observed data which contains outliers. It is a non-deterministic algorithm in the sense that it produces a reasonable result only with a certain...
to find the affine projection matrix which best fits the unified object model to the 2D scene. If this RANSAC approach has sufficiently low error, then on success, the algorithm both recognizes the object and gives the object's pose in terms of an affine projection. Under the assumed conditions, the method typically achieves recognition rates of around 95%.
See also
- Blob detectionBlob detectionIn the area of computer vision, blob detection refers to visual modules that are aimed at detecting points and/or regions in the image that differ in properties like brightness or color compared to the surrounding...
- Object recognitionObject recognitionObject recognition in computer vision is the task of finding a given object in an image or video sequence. Humans recognize a multitude of objects in images with little effort, despite the fact that the image of the objects may vary somewhat in different view points, in many different sizes / scale...
- Feature descriptor
- Feature detection (computer vision)
- Harris affine region detectorHarris affine region detectorIn the fields of computer vision and image analysis, the Harris affine region detector belongs to the category of feature detection. Feature detection is a preprocessing step of several algorithms that rely on identifying characteristic points or interest points so to make correspondences between...
- RANSACRANSACRANSAC is an abbreviation for "RANdom SAmple Consensus". It is an iterative method to estimate parameters of a mathematical model from a set of observed data which contains outliers. It is a non-deterministic algorithm in the sense that it produces a reasonable result only with a certain...
- SIFTScale-invariant feature transformScale-invariant feature transform is an algorithm in computer vision to detect and describe local features in images. The algorithm was published by David Lowe in 1999....
- Structure from motionStructure from motionIn computer vision structure from motion refers to the process of finding the three-dimensional structure of an object by analyzing local motion signals over time....