
Treebank
Encyclopedia
A treebank or parsed corpus is a text corpus
in which each sentence
has been parsed
, i.e. annotated with syntactic structure. Syntactic structure is commonly represented as a tree structure
, hence the name Treebank. The term Parsed Corpus is often used interchangeably with Treebank: with the emphasis on the primacy of sentences rather than trees.
Treebanks are often created on top of a corpus that has already been annotated with part-of-speech tag
s. In turn, treebanks are sometimes enhanced with semantic or other linguistic information.
Treebanks can be created completely manually, where linguists annotate each sentence with syntactic structure, or semi-automatically, where a parser assigns some syntactic structure which linguists then check and, if necessary, correct. In practice, fully checking and completing the parsing of natural language corpora is a labour intensive project that can take teams of graduate linguists several years. The level of annotation detail and the breadth of the linguistic sample determine the difficulty of the task and the length of time required to build a treebank.
Some treebanks follow a specific linguistic theory in their syntactic annotation (e.g. the BulTreeBank follows HPSG) but most try to be less theory-specific. However, two main groups can be distinguished: treebanks that annotate phrase structure
(for example the Penn Treebank or ICE-GB) and those that annotate dependency structure
(for example the Prague Dependency Treebank or the Quranic Arabic Dependency Treebank).
 It is important to clarify the distinction between the formal representation and the file format used. Treebanks are necessarily constructed according to a particular grammar. The same grammar may be implemented by different file formats.
It is important to clarify the distinction between the formal representation and the file format used. Treebanks are necessarily constructed according to a particular grammar. The same grammar may be implemented by different file formats.
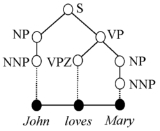
For example, the syntactic analysis for John loves Mary, shown in the figure on the right, may be represented by simple labelled brackets in a text file, like this (following the Penn Treebank notation):
(S (NP (NNP John))
(VP (VPZ loves)
(NP (NNP Mary)))
(. .))
This type of representation is popular because it is 'light' on resources, and the tree structure is relatively easy to 'read' without software tools. However as corpora become increasingly complex, other file formats may be preferred. Alternatives include treebank-specific XML
schemes, numbered indentation and various types of standoff notation. If you want to review schemes, see the Amalgam Multi-Treebank, a pico corpus of 20 sentences annotated by different grammars and notation schemes.
for studying syntactic phenomena or in computational linguistics
for training or testing parsers. Diachronic corpora can be used to study the time course of syntactic change.
The value of parsed corpora is becoming more and more widely understood. The data of introspection has been crucial to syntactic research because introspection provides evidence, not only of what is possible in a given language but also of what is not possible. Such negative evidence is, of course, not available in corpora of actual writing or speech. On the other hand, introspection about grammar
is itself inevitably partial, as linguists have found when attempting to parse actual speech and writing, and it provides relatively poor information about the information structure of sentences; that is, the discourse contexts in which given syntactic constructions are licensed.
Once parsed, a corpus will contain evidence of both frequency (how common different grammatical structures are in use) and coverage (the discovery of new, unanticipated, grammatical phenomena).
An automatically parsed corpus that is not corrected by human linguists is useful. It can provide evidence of rule frequency for a parser. A parser may be improved by applying it to large amounts of text and gathering rule frequencies. However, it should be obvious that only by a process of correcting and completing a corpus by hand is it possible then to identify rules absent from the parser knowledge base. (As a bonus, frequencies are likely to be more accurate.)
Potentially, however, by far the most interesting question for theoretical linguists and psycholinguists is interaction evidence in parsed corpora. A completed treebank can help linguists carry out experiments as to how the decision to use one grammatical construction tends to influence the decision to form others. The idea here is not to improve parsing algorithms but to go to the heart of the question of linguistic choice: to try to understand how speakers and writers make decisions as they form sentences.
Interaction research is particularly fruitful as further layers of annotation, e.g. semantic, pragmatic, are added to a corpus. It is then possible to evaluate the impact of 'non-syntactic' phenomena on grammatical choices.
The parsing and exploitation of parsed corpora has become an important subdiscipline of Corpus Linguistics ever since the first large-scale treebank, The Penn Treebank, was published. Many of the theoretical criticisms of lexical corpora do not apply to parsed corpora. Results from a parsed corpus are more closely commensurate with linguistic theories. However, a new epistemological problem arises: a parsed corpus necessarily requires a particular analysis, and this analysis, and the theory behind it, may be incorrect or deficient.
The question facing a new researcher is not only, "which corpus is relevant to my needs?" but also "how can I find the information I want in this corpus, and how do I know that the results of my experiments mean what I think they do?"
Wallis 2008 discusses the principles of searching treebanks in detail and reviews the state of the art (in 2006).
In addition to strictly Treebank search tools, some tools for searching speech data also exist. These tools are designed to support searches on overlapping hierarchies or graph structures.
Text corpus
In linguistics, a corpus or text corpus is a large and structured set of texts...
in which each sentence
Sentence (linguistics)
In the field of linguistics, a sentence is an expression in natural language, and often defined to indicate a grammatical unit consisting of one or more words that generally bear minimal syntactic relation to the words that precede or follow it...
has been parsed
Parsing
In computer science and linguistics, parsing, or, more formally, syntactic analysis, is the process of analyzing a text, made of a sequence of tokens , to determine its grammatical structure with respect to a given formal grammar...
, i.e. annotated with syntactic structure. Syntactic structure is commonly represented as a tree structure
Tree structure
A tree structure is a way of representing the hierarchical nature of a structure in a graphical form. It is named a "tree structure" because the classic representation resembles a tree, even though the chart is generally upside down compared to an actual tree, with the "root" at the top and the...
, hence the name Treebank. The term Parsed Corpus is often used interchangeably with Treebank: with the emphasis on the primacy of sentences rather than trees.
Treebanks are often created on top of a corpus that has already been annotated with part-of-speech tag
Part-of-speech tagging
In corpus linguistics, part-of-speech tagging , also called grammatical tagging or word-category disambiguation, is the process of marking up a word in a text as corresponding to a particular part of speech, based on both its definition, as well as its context—i.e...
s. In turn, treebanks are sometimes enhanced with semantic or other linguistic information.
Treebanks can be created completely manually, where linguists annotate each sentence with syntactic structure, or semi-automatically, where a parser assigns some syntactic structure which linguists then check and, if necessary, correct. In practice, fully checking and completing the parsing of natural language corpora is a labour intensive project that can take teams of graduate linguists several years. The level of annotation detail and the breadth of the linguistic sample determine the difficulty of the task and the length of time required to build a treebank.
Some treebanks follow a specific linguistic theory in their syntactic annotation (e.g. the BulTreeBank follows HPSG) but most try to be less theory-specific. However, two main groups can be distinguished: treebanks that annotate phrase structure
Phrase structure rules
Phrase-structure rules are a way to describe a given language's syntax. They are used to break down a natural language sentence into its constituent parts namely phrasal categories and lexical categories...
(for example the Penn Treebank or ICE-GB) and those that annotate dependency structure
Dependency grammar
Dependency grammar is a class of modern syntactic theories that are all based on the dependency relation and that can be traced back primarily to the work of Lucien Tesnière. Dependency grammars are distinct from phrase structure grammars , since they lack phrasal nodes. Structure is determined by...
(for example the Prague Dependency Treebank or the Quranic Arabic Dependency Treebank).
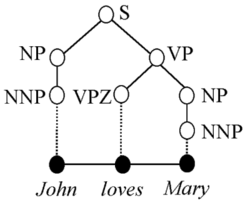
For example, the syntactic analysis for John loves Mary, shown in the figure on the right, may be represented by simple labelled brackets in a text file, like this (following the Penn Treebank notation):
(S (NP (NNP John))
(VP (VPZ loves)
(NP (NNP Mary)))
(. .))
This type of representation is popular because it is 'light' on resources, and the tree structure is relatively easy to 'read' without software tools. However as corpora become increasingly complex, other file formats may be preferred. Alternatives include treebank-specific XML
XML
Extensible Markup Language is a set of rules for encoding documents in machine-readable form. It is defined in the XML 1.0 Specification produced by the W3C, and several other related specifications, all gratis open standards....
schemes, numbered indentation and various types of standoff notation. If you want to review schemes, see the Amalgam Multi-Treebank, a pico corpus of 20 sentences annotated by different grammars and notation schemes.
What is the purpose of a treebank?
Treebanks can be used in corpus linguisticsCorpus linguistics
Corpus linguistics is the study of language as expressed in samples or "real world" text. This method represents a digestive approach to deriving a set of abstract rules by which a natural language is governed or else relates to another language. Originally done by hand, corpora are now largely...
for studying syntactic phenomena or in computational linguistics
Computational linguistics
Computational linguistics is an interdisciplinary field dealing with the statistical or rule-based modeling of natural language from a computational perspective....
for training or testing parsers. Diachronic corpora can be used to study the time course of syntactic change.
The value of parsed corpora is becoming more and more widely understood. The data of introspection has been crucial to syntactic research because introspection provides evidence, not only of what is possible in a given language but also of what is not possible. Such negative evidence is, of course, not available in corpora of actual writing or speech. On the other hand, introspection about grammar
Grammar
In linguistics, grammar is the set of structural rules that govern the composition of clauses, phrases, and words in any given natural language. The term refers also to the study of such rules, and this field includes morphology, syntax, and phonology, often complemented by phonetics, semantics,...
is itself inevitably partial, as linguists have found when attempting to parse actual speech and writing, and it provides relatively poor information about the information structure of sentences; that is, the discourse contexts in which given syntactic constructions are licensed.
Once parsed, a corpus will contain evidence of both frequency (how common different grammatical structures are in use) and coverage (the discovery of new, unanticipated, grammatical phenomena).
An automatically parsed corpus that is not corrected by human linguists is useful. It can provide evidence of rule frequency for a parser. A parser may be improved by applying it to large amounts of text and gathering rule frequencies. However, it should be obvious that only by a process of correcting and completing a corpus by hand is it possible then to identify rules absent from the parser knowledge base. (As a bonus, frequencies are likely to be more accurate.)
Potentially, however, by far the most interesting question for theoretical linguists and psycholinguists is interaction evidence in parsed corpora. A completed treebank can help linguists carry out experiments as to how the decision to use one grammatical construction tends to influence the decision to form others. The idea here is not to improve parsing algorithms but to go to the heart of the question of linguistic choice: to try to understand how speakers and writers make decisions as they form sentences.
Interaction research is particularly fruitful as further layers of annotation, e.g. semantic, pragmatic, are added to a corpus. It is then possible to evaluate the impact of 'non-syntactic' phenomena on grammatical choices.
The parsing and exploitation of parsed corpora has become an important subdiscipline of Corpus Linguistics ever since the first large-scale treebank, The Penn Treebank, was published. Many of the theoretical criticisms of lexical corpora do not apply to parsed corpora. Results from a parsed corpus are more closely commensurate with linguistic theories. However, a new epistemological problem arises: a parsed corpus necessarily requires a particular analysis, and this analysis, and the theory behind it, may be incorrect or deficient.
Searching treebanks
One of the key ways to extract evidence from a treebank is through search tools. Search tools for parsed corpora typically depend on the annotation scheme that was applied to the corpus. User interfaces range in sophistication from expression-based query systems aimed at computer programmers to full exploration environments aimed at general linguists.The question facing a new researcher is not only, "which corpus is relevant to my needs?" but also "how can I find the information I want in this corpus, and how do I know that the results of my experiments mean what I think they do?"
Tools
- Phrase structure grammar
- tgrep; tgrep2
- CorpusSearch
- Linguistic DataBase (LDB)
- VIQTORYA
- ICECUP III; ICECUP IV
- fsq
- MonaSearch
- Dependency grammar
- Dependency grammar and/or Phrase-structure grammar
- PML-TQ (single-layer)
- TigerSearch (single-layer)
- ANNIS (multi-layer)
- Others
Wallis 2008 discusses the principles of searching treebanks in detail and reviews the state of the art (in 2006).
In addition to strictly Treebank search tools, some tools for searching speech data also exist. These tools are designed to support searches on overlapping hierarchies or graph structures.
List of treebanks sorted by language
- Arabic:
- Bulgarian: BulTreeBank (HPSG-based Syntactic Treebank)
- Catalan: Cat3LB
- Chinese: Penn Chinese Treebank, Sinica Treebank by CKIP, a tentative Chinese Dependency Treebank
- Croatian: Croatian Dependency Treebank
- Czech: Prague Dependency Treebank
- Danish: Danish Dependency Treebank, Arboretum: A syntactic tree corpus of Danish
- Dutch: CGN, Alpino
- English:
- Penn;
- Prague English Dependency Treebank;
- BLLIP WSJ corpus;
- British Component of the International Corpus of English (ICE-GB);
- Diachronic Corpus of Present-Day Spoken English (DCPSE);
- Lancaster Parsed Corpus;
- Susanne Corpus, Christine Corpus, Lucy Corpus;
- Verbmobil treebanks: Tübingen Treebank of English / Spontaneous Speech (TüBa-E/S)
- LinGO Redwoods;
- Multi-Treebank;
- The PARC 700 Dependency Bank;
- CHILDES Brown Eve corpus with dependency annotation, see Sagae, K., MacWhinney, B., and Lavie, A. (2004) Adding syntactic annotations to transcripts of parent-child dialogs. In Proceedings of the Fourth International Conference on Language Resources and Evaluation (LREC 2004). Lisbon, Portugal.
- SMULTRON - Parallel Treebank EN-DE-SV
- English-historical:
- Estonian: Syntactically analyzed and disambiguated text corpus, see also Arborest
- Finnish: Turku Dependency Treebank (TDT)
- French: Paris 7, L'Arboratoire
- French-historical: Corpus MCVF;
- German:
- Greek, Modern: Greek Dependency Treebank
- Greek, Ancient:
- Hebrew: Hebrew Treebank
- Hindi: AnnCorra
- Hungarian: Hungarian treebank
- Icelandic: IcePaHC - Icelandic Parsed Historical Corpus
- Italian:
- Japanese:
- Korean: Korean Treebank
- Latin:
- Norwegian: TREPIL Norwegian treebank (pilot project)
- Polish: A Treebank / Test Suite for Polish (HPSG treebank)
- Portuguese: Projecto Floresta Sintá(c)tica
- Portuguese-historical: Tycho Brahe corpus
- Romanian: Romanian Dependency Treebank
- Russian: SynTagRus Dependency Treebank incorporated in the Russian National CorpusRussian National CorpusThe Russian National Corpus is a corpus of the Russian language that has been available online since April 29, 2004...
- Slovene: Slovene Dependency Treebank
- Spanish: Cast3LB, UAM Treebank of Spanish
- Swedish: Talbanken05, Swedish Treebank, SMULTRON - Parallel Treebank EN-DE-SV
- Thai: NAiST Thai Treebank
- Turkish: METU-Sabanci Treebank
- Urdu NU-FAST Treebank): http://www.ijens.org/1959091.pdf
- Vietnamese: Viet-Treebank