

Stochastic approximation
Encyclopedia
Stochastic approximation methods are a family of iterative stochastic optimization
algorithm
s that attempt to find zeroes or extrema of functions which cannot be computed directly, but only estimated via noisy observations.
Mathematically, this refers to solving:
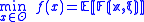
where the objective is to find the parameter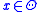 , which minimizes
, which minimizes 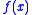 for some unknown random variable,
for some unknown random variable,  . Denoting
. Denoting  as the dimension of the parameter
as the dimension of the parameter  , we can assume that while the domain
, we can assume that while the domain 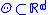 is known, the objective function,
is known, the objective function, 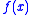 , cannot be computed exactly, but instead approximated via simulation. This can be intuitively explained as follows.
, cannot be computed exactly, but instead approximated via simulation. This can be intuitively explained as follows. 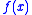 is the original function we want to minimize. However, due to noise,
is the original function we want to minimize. However, due to noise, 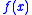 can not be evaluated exactly. This situation is modeled by the function
can not be evaluated exactly. This situation is modeled by the function 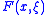 , where
, where  represents the noise and is a random variable. Since
represents the noise and is a random variable. Since  is a random variable, so is the value of
is a random variable, so is the value of 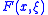 . The objective is then to minimize
. The objective is then to minimize 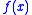 , but through evaluating
, but through evaluating 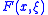 . A reasonable way to do this is to minimize the expectancy of
. A reasonable way to do this is to minimize the expectancy of 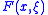 , i.e.,
, i.e., 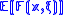 .
.
The first, and prototypical, algorithms of this kind are the Robbins-Monro and Kiefer-Wolfowitz algorithms.
and Sutton Monro, presented a methodology for solving a root finding problem, where the function is represented as an expected value. Assume that we have a function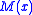 , and a constant
, and a constant  , such that the equation
, such that the equation 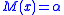 has a unique root at
has a unique root at  . It is assumed that while we cannot directly observe the function
. It is assumed that while we cannot directly observe the function 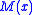 , we can instead obtain measurements of the random variable
, we can instead obtain measurements of the random variable 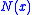 where
where 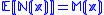 . The structure of the algorithm is to then generate iterates of the form:
. The structure of the algorithm is to then generate iterates of the form:
Here,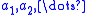 is a sequence of positive step sizes. Robbins
is a sequence of positive step sizes. Robbins
and Monro proved , Theorem 2 that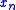 converges
converges
in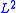 (and hence also in probability) to
(and hence also in probability) to 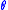 provided that:
provided that:
A particular sequence of steps which satisfy these conditions, and was suggested by Robbins–Munro, have the form: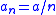 , for
, for  . Other series are possible but in order to average out the noise in
. Other series are possible but in order to average out the noise in 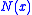 , the above condition must be met.
, the above condition must be met.
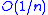 under the assumption of twice continuous differentiability and strong convexity, it can perform quite poorly upon implementation. This is primarily due to the fact that the algorithm is very sensitive to the choice of the step size sequence, and the supposed asymptotically optimal step size policy can be quite harmful in the beginning.
under the assumption of twice continuous differentiability and strong convexity, it can perform quite poorly upon implementation. This is primarily due to the fact that the algorithm is very sensitive to the choice of the step size sequence, and the supposed asymptotically optimal step size policy can be quite harmful in the beginning.
To overcome this shortfall, Polyak and Juditsky, presented a method of accelerating Robbins-Monro through the use of longer steps, and averaging of the iterates. The algorithm would have the following structure:
The convergence of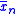 to the unique root
to the unique root 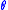 relies on the condition that the step sequence
relies on the condition that the step sequence 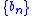 decreases sufficiently slowly. That is
decreases sufficiently slowly. That is
Therefore, the sequence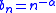 with
with 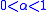 satisfies this restriction, but
satisfies this restriction, but  does not, hence the longer steps. Under the assumptions outlined in the Robbins-Monro algorithm, the resulting modification will result in the same asymptotically optimal convergence rate
does not, hence the longer steps. Under the assumptions outlined in the Robbins-Monro algorithm, the resulting modification will result in the same asymptotically optimal convergence rate 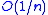 yet with a more robust step size policy.
yet with a more robust step size policy.
Prior to this, the idea of using longer steps and averaging the iterates had already been proposed by Nemirovski and Yudin for the cases of solving the stochastic optimization problem with continuous convex objectives and for convex-concave saddle point problems. These algorithms were observed to attain the nonasymptotic rate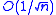 .
.
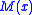 be a function which has a maximum at the point
be a function which has a maximum at the point 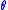 . It is assumed that
. It is assumed that 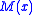 is unknown, however, certain observations
is unknown, however, certain observations 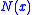 , where
, where 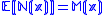 , can be made at any point
, can be made at any point  . The structure of the algorithm follows a gradient-like method, with the iterates being generated as follows:
. The structure of the algorithm follows a gradient-like method, with the iterates being generated as follows:
where the gradient of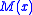 is approximated using finite differences. The sequence
is approximated using finite differences. The sequence 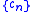 specifies the sequence of finite difference widths used for the gradient approximation, while the sequence
specifies the sequence of finite difference widths used for the gradient approximation, while the sequence 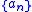 specifies a sequence of positive step sizes taken along that direction. Kiefer and Wolfowitz proved that, if
specifies a sequence of positive step sizes taken along that direction. Kiefer and Wolfowitz proved that, if 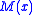 satisfied certain regularity conditions, then
satisfied certain regularity conditions, then 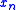 will converge to
will converge to 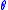 provided that:
provided that:
A suitable choice of sequences, as recommended by Kiefer and Wolfowitz, would be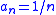 and
and 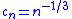 .
.
, in which case the unknown function which we wish to optimize or find the zero of may vary in time. In this case, the step size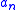 should not converge to zero but should be chosen so as to track the function., 2nd ed., chapter 3
should not converge to zero but should be chosen so as to track the function., 2nd ed., chapter 3
C. Johan Masreliez and R. Douglas Martin were the first to use
stochastic approximation in 1975 when dealing with robust
estimation
.
Stochastic optimization
Stochastic optimization methods are optimization methods that generate and use random variables. For stochastic problems, the random variables appear in the formulation of the optimization problem itself, which involve random objective functions or random constraints, for example. Stochastic...
algorithm
Algorithm
In mathematics and computer science, an algorithm is an effective method expressed as a finite list of well-defined instructions for calculating a function. Algorithms are used for calculation, data processing, and automated reasoning...
s that attempt to find zeroes or extrema of functions which cannot be computed directly, but only estimated via noisy observations.
Mathematically, this refers to solving:
where the objective is to find the parameter
, which minimizes for some unknown random variable, . Denoting as the dimension of the parameter , we can assume that while the domain is known, the objective function, , cannot be computed exactly, but instead approximated via simulation. This can be intuitively explained as follows. is the original function we want to minimize. However, due to noise, can not be evaluated exactly. This situation is modeled by the function , where represents the noise and is a random variable. Since is a random variable, so is the value of . The objective is then to minimize , but through evaluating . A reasonable way to do this is to minimize the expectancy of , i.e., .The first, and prototypical, algorithms of this kind are the Robbins-Monro and Kiefer-Wolfowitz algorithms.
Robbins–Monro algorithm
The Robbins–Monro algorithm, introduced in 1951 by Herbert RobbinsHerbert Robbins
Herbert Ellis Robbins was an American mathematician and statistician who did research in topology, measure theory, statistics, and a variety of other fields. He was the co-author, with Richard Courant, of What is Mathematics?, a popularization that is still in print. The Robbins lemma, used in...
and Sutton Monro, presented a methodology for solving a root finding problem, where the function is represented as an expected value. Assume that we have a function
, and a constant , such that the equation has a unique root at . It is assumed that while we cannot directly observe the function , we can instead obtain measurements of the random variable where . The structure of the algorithm is to then generate iterates of the form: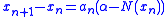
Here,
is a sequence of positive step sizes. RobbinsHerbert Robbins
Herbert Ellis Robbins was an American mathematician and statistician who did research in topology, measure theory, statistics, and a variety of other fields. He was the co-author, with Richard Courant, of What is Mathematics?, a popularization that is still in print. The Robbins lemma, used in...
and Monro proved , Theorem 2 that
convergesConvergence of random variables
In probability theory, there exist several different notions of convergence of random variables. The convergence of sequences of random variables to some limit random variable is an important concept in probability theory, and its applications to statistics and stochastic processes...
in
(and hence also in probability) to provided that:
-
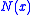 is uniformly bounded,
is uniformly bounded, -
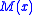 is nondecreasing,
is nondecreasing, -
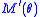 exists and is positive, and
exists and is positive, and - The sequence
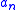 satisfies the following requirements:
satisfies the following requirements:
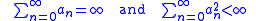
A particular sequence of steps which satisfy these conditions, and was suggested by Robbins–Munro, have the form:
, for . Other series are possible but in order to average out the noise in , the above condition must be met.Complexity Results
- If
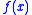 is twice continuously differentiable, and strongly convex, and the minimizer of
is twice continuously differentiable, and strongly convex, and the minimizer of 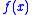 belongs to the interior of
belongs to the interior of  , then the Robbins-Monro algorithm will achieve the asymptotically optimal convergence rate, with respect to the objective function, being
, then the Robbins-Monro algorithm will achieve the asymptotically optimal convergence rate, with respect to the objective function, being 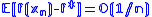 , where
, where 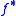 is the minimal value of
is the minimal value of 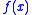 over
over 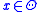 .
. - Conversely, in the general convex case, where we lack both the assumption of smoothness and strong convexity, Nemirovski and Yudin have shown that the asymptotically optimal convergence rate, with respect to the objective function values, is
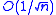 . They have also proven that this rate cannot be improved.
. They have also proven that this rate cannot be improved.
Subsequent Developments
While the Robbins-Monro algorithm is theoretically able to achieve under the assumption of twice continuous differentiability and strong convexity, it can perform quite poorly upon implementation. This is primarily due to the fact that the algorithm is very sensitive to the choice of the step size sequence, and the supposed asymptotically optimal step size policy can be quite harmful in the beginning.To overcome this shortfall, Polyak and Juditsky, presented a method of accelerating Robbins-Monro through the use of longer steps, and averaging of the iterates. The algorithm would have the following structure:
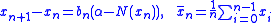
The convergence of
to the unique root relies on the condition that the step sequence decreases sufficiently slowly. That is
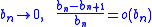
Therefore, the sequence
with satisfies this restriction, but does not, hence the longer steps. Under the assumptions outlined in the Robbins-Monro algorithm, the resulting modification will result in the same asymptotically optimal convergence rate yet with a more robust step size policy.Prior to this, the idea of using longer steps and averaging the iterates had already been proposed by Nemirovski and Yudin for the cases of solving the stochastic optimization problem with continuous convex objectives and for convex-concave saddle point problems. These algorithms were observed to attain the nonasymptotic rate
.Kiefer-Wolfowitz algorithm
The Kiefer-Wolfowitz algorithm, was introduced in 1952, and was motivated by the publication of the Robbins-Monro algorithm. However, the algorithm was presented as a method which would stochastically estimate the maximum of a function. Let be a function which has a maximum at the point . It is assumed that is unknown, however, certain observations , where , can be made at any point . The structure of the algorithm follows a gradient-like method, with the iterates being generated as follows:
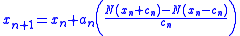
where the gradient of
is approximated using finite differences. The sequence specifies the sequence of finite difference widths used for the gradient approximation, while the sequence specifies a sequence of positive step sizes taken along that direction. Kiefer and Wolfowitz proved that, if satisfied certain regularity conditions, then will converge to provided that:
- The function
 has a unique point of maximum (minimum) and is strong concave (convex)
has a unique point of maximum (minimum) and is strong concave (convex)
- The algorithm was first presented with the requirement that the function
 maintains strong global convexity (concavity) over the entire feasible space. Given this condition is too restrictive to impose over the entire domain, Kiefer and Wolfowitz proposed that it is sufficient to impose the condition over a compact set
maintains strong global convexity (concavity) over the entire feasible space. Given this condition is too restrictive to impose over the entire domain, Kiefer and Wolfowitz proposed that it is sufficient to impose the condition over a compact set 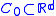 which is known to include the optimal solution.
which is known to include the optimal solution.
- The algorithm was first presented with the requirement that the function
- The selected sequences
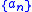 and
and 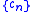 must be infinite sequences of positive numbers such that:
must be infinite sequences of positive numbers such that:

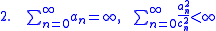
A suitable choice of sequences, as recommended by Kiefer and Wolfowitz, would be
and .Subsequent Developments and Important Issues
- The Kiefer Wolfowitz algorithm requires that for each gradient computation, at least
 different parameter values must simulated for every iteration of the algorithm, where
different parameter values must simulated for every iteration of the algorithm, where  is the dimension of the search space. This means that when
is the dimension of the search space. This means that when  is large, the Kiefer-Wolfowitz algorithm will require substantial computational effort per iteration, leading to slow convergence.
is large, the Kiefer-Wolfowitz algorithm will require substantial computational effort per iteration, leading to slow convergence.
- To address this problem, Spall, proposed the use of simultaneous perturbationsSimultaneous perturbation stochastic approximationSimultaneous perturbation stochastic approximation is an algorithmic method for optimizing systems with multiple unknown parameters. It is a type of stochastic approximation algorithm. As an optimization method, it is appropriately suited to large-scale population models, adaptive modeling,...
to estimate the gradient. This method would require only two simulations per iteration, regardless of the dimension .
.
- To address this problem, Spall, proposed the use of simultaneous perturbations
- In the conditions required for convergence, the ability to specify a predetermined compact set that fulfills strong convexity (or concavity) and contains the unique solution can be difficult to find. With respect to real world applications, if the domain is quite large, these assumptions can be fairly restrictive and highly unrealistic.
Further Developments in Stochastic Approximation
An extensive theoretical literature has grown up around these algorithms, concerning conditions for convergence, rates of convergence, multivariate and other generalizations, proper choice of step size, possible noise models, and so on. These methods are also applied in control theoryControl theory
Control theory is an interdisciplinary branch of engineering and mathematics that deals with the behavior of dynamical systems. The desired output of a system is called the reference...
, in which case the unknown function which we wish to optimize or find the zero of may vary in time. In this case, the step size
should not converge to zero but should be chosen so as to track the function., 2nd ed., chapter 3C. Johan Masreliez and R. Douglas Martin were the first to use
stochastic approximation in 1975 when dealing with robust
Robust statistics
Robust statistics provides an alternative approach to classical statistical methods. The motivation is to produce estimators that are not unduly affected by small departures from model assumptions.- Introduction :...
estimation
Estimation
Estimation is the calculated approximation of a result which is usable even if input data may be incomplete or uncertain.In statistics,*estimation theory and estimator, for topics involving inferences about probability distributions...
.
See also
- Stochastic gradient descentStochastic gradient descentStochastic gradient descent is an optimization method for minimizing an objective function that is written as a sum of differentiable functions.- Background :...
- Stochastic optimizationStochastic optimizationStochastic optimization methods are optimization methods that generate and use random variables. For stochastic problems, the random variables appear in the formulation of the optimization problem itself, which involve random objective functions or random constraints, for example. Stochastic...
- Simultaneous perturbation stochastic approximationSimultaneous perturbation stochastic approximationSimultaneous perturbation stochastic approximation is an algorithmic method for optimizing systems with multiple unknown parameters. It is a type of stochastic approximation algorithm. As an optimization method, it is appropriately suited to large-scale population models, adaptive modeling,...