

Stein's method
Encyclopedia
Stein's method is a general method in probability theory
to obtain bounds on the distance between two probability distributions with respect to a probability metric. It was introduced by Charles Stein, who first published it 1972, to obtain a bound between the distribution of a sum of -dependent sequence of random variables and a standard normal distribution in the Kolmogorov (uniform) metric and hence to prove not only a central limit theorem
-dependent sequence of random variables and a standard normal distribution in the Kolmogorov (uniform) metric and hence to prove not only a central limit theorem
, but also bounds on the rates of convergence
for the given metric.
, Charles Stein developed a new way of proving the theorem for his statistics
lecture.
The seminal paper was presented in 1970 at the sixth Berkeley Symposium and published in the corresponding proceedings.
Later, his Ph.D.
student Louis Chen Hsiao Yun
modified the method so as to obtain approximation results for the Poisson distribution
, therefore the method is often referred to as Stein-Chen method. Whereas moderate attention was given to the new method in the 70s, it has undergone major development in the 80s, where many important contributions were made and on which today's view of the method are largely based. Probably the most important contributions are the monograph by Stein (1986), where he presents his view of the method and the concept of auxiliary randomisation, in particular using exchangeable pairs, and the articles by Barbour (1988) and Götze (1991), who introduced the so-called generator interpretation, which made it possible to easily adapt the method to many other probability distributions. An important contribution was also an article by Bolthausen (1984) on a long-standing open problem around the so-called combinatorial central limit theorem, which surely helped the method to become widely known.
In the 1990s the method was adapted to a variety of distributions, such as Gaussian process
es by Barbour (1990), the binomial distribution by Ehm (1991), Poisson process
es by Barbour and Brown (1992), the Gamma distribution by Luk (1994), and many others.

Here,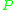 and
and 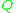 are probability measures on a measurable space
are probability measures on a measurable space 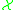 ,
, 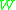 and
and 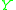 are random variables with distribution
are random variables with distribution 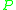 and
and 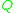 respectively,
respectively, 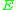 is the usual expectation operator and
is the usual expectation operator and  is a set of functions from
is a set of functions from  to the real numbers. This set has to be large enough, so that the above definition indeed yields a metric
to the real numbers. This set has to be large enough, so that the above definition indeed yields a metric
. Important examples are the total variation metric, where we let consist of all the indicator functions of measurable sets, the Kolmogorov (uniform) metric for probability measures on the real numbers, where we consider all the half-line indicator functions, and the Lipschitz (first order Wasserstein; Kantorovich) metric
consist of all the indicator functions of measurable sets, the Kolmogorov (uniform) metric for probability measures on the real numbers, where we consider all the half-line indicator functions, and the Lipschitz (first order Wasserstein; Kantorovich) metric
, where the underlying space is itself a metric space and we take the set to be all Lipschitz-continuous
to be all Lipschitz-continuous
functions with Lipschitz-constant 1. However, note that not every metric can be represented in the form (1.1).
In what follows we think of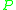 as a complicated distribution (e.g. a sum of dependent random variables), which we want to approximate by a much simpler and tractable distribution
as a complicated distribution (e.g. a sum of dependent random variables), which we want to approximate by a much simpler and tractable distribution  (e.g. the standard normal distribution to obtain a central limit theorem).
(e.g. the standard normal distribution to obtain a central limit theorem).
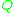 is a fixed distribution; in what follows we shall in particular consider the case where
is a fixed distribution; in what follows we shall in particular consider the case where 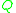 is the standard normal distribution, which serves as a classical example of the application of Stein's method.
is the standard normal distribution, which serves as a classical example of the application of Stein's method.
First of all, we need an operator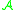 which acts on functions
which acts on functions 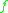 from
from 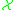 to the real numbers, and which 'characterizes' the distribution
to the real numbers, and which 'characterizes' the distribution 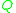 in the sense that the following equivalence holds:
in the sense that the following equivalence holds:
We call such an operator the Stein operator. For the standard normal distribution, Stein's lemma
exactly yields such an operator: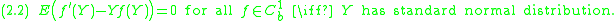
thus we can take
We note that there are in general infinitely many such operators and it still remains an open question, which one to choose. However, it seems that for many distributions there is a particular good one, like (2.3) for the normal distribution.
There are different ways to find Stein operators. But by far the most important one is via generators. This approach was, as already mentioned, introduced by Barbour and Götze. Assume that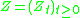 is a (homogeneous) continuous time Markov process taking values in
is a (homogeneous) continuous time Markov process taking values in 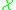 . If
. If 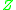 has the stationary distribution
has the stationary distribution
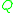 it is easy to see that, if
it is easy to see that, if 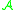 is the generator
is the generator
of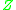 , we have
, we have  for a large set of functions
for a large set of functions 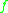 . Thus, generators are natural candidates for Stein operators and this approach will also help us for later computations.
. Thus, generators are natural candidates for Stein operators and this approach will also help us for later computations.
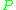 is close to
is close to 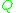 with respect to
with respect to  is equivalent to saying that the difference of expectations in (1.1) is close to 0, and indeed if
is equivalent to saying that the difference of expectations in (1.1) is close to 0, and indeed if  it is equal to 0. We hope now that the operator
it is equal to 0. We hope now that the operator  exhibits the same behavior: clearly if
exhibits the same behavior: clearly if 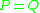 we have
we have 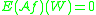 and hopefully if
and hopefully if  we have
we have 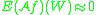 .
.
To make this statement rigorous we could find a function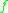 , such that, for a given function
, such that, for a given function 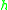 ,
,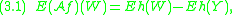
so that the behavior of the right hand side is reproduced by the operator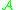 and
and 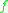 .
.
However, this equation is too general. We solve instead the more specific equation
which is called Stein equation. Replacing by
by 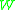 and taking expectation with respect to
and taking expectation with respect to 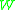 , we are back to (3.1), which is what we effectively want. Now all the effort is worth only if the left hand side of (3.1) is easier to bound than the right hand side. This is, surprisingly, often the case.
, we are back to (3.1), which is what we effectively want. Now all the effort is worth only if the left hand side of (3.1) is easier to bound than the right hand side. This is, surprisingly, often the case.
If is the standard normal distribution and we use (2.3), the corresponding Stein equation is
is the standard normal distribution and we use (2.3), the corresponding Stein equation is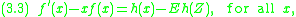
which is just an ordinary differential equation
.
Analytic methods. We see from (3.3) that equation (3.2) can in particular be a differential equation
(if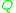 is concentrated on the integers, it will often turn out to be a difference equation). As there are many methods available to treat such equations, we can use them to solve the equation. For example, (3.3) can be easily solved explicitly:
is concentrated on the integers, it will often turn out to be a difference equation). As there are many methods available to treat such equations, we can use them to solve the equation. For example, (3.3) can be easily solved explicitly: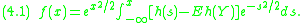
Generator method. If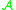 is the generator of a Markov process
is the generator of a Markov process 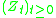 as explained before, we can give a general solution to (3.2):
as explained before, we can give a general solution to (3.2):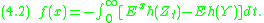
where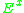 denotes expectation with respect to the process
denotes expectation with respect to the process 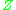 being started in
being started in  . However, one still has to prove that the solution (4.2) exists for all desired functions
. However, one still has to prove that the solution (4.2) exists for all desired functions  .
.
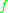 and its derivatives (which has to be carefully defined if
and its derivatives (which has to be carefully defined if 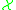 is a more complicated space) or differences in terms of
is a more complicated space) or differences in terms of 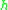 and its derivatives or differences, that is, inequalities of the form
and its derivatives or differences, that is, inequalities of the form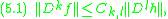
for some specific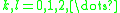 (typically
(typically 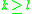 or
or 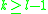 , respectively, depending on the form of the Stein operator) and where often
, respectively, depending on the form of the Stein operator) and where often 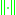 is taken to be the supremum norm. Here,
is taken to be the supremum norm. Here, 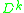 denotes the differential operator
denotes the differential operator
, but in discrete settings it usually refers to a difference operator. The constants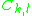 may contain the parameters of the distribution
may contain the parameters of the distribution 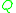 . If there are any, they are often referred to as Stein factors or magic factors.
. If there are any, they are often referred to as Stein factors or magic factors.
In the case of (4.1) we can prove for the supremum norm that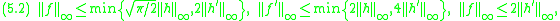
where the last bound is of course only applicable if is differentiable (or at least Lipschitz-continuous, which, for example, is not the case if we regard the total variation metric or the Kolmogorov metric!). As the standard normal distribution has no extra parameters, in this specific case, the constants are free of additional parameters.
is differentiable (or at least Lipschitz-continuous, which, for example, is not the case if we regard the total variation metric or the Kolmogorov metric!). As the standard normal distribution has no extra parameters, in this specific case, the constants are free of additional parameters.
Note that, up to this point, we did not make use of the random variable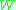 . So, the steps up to here in general have to be calculated only once for a specific combination of distribution
. So, the steps up to here in general have to be calculated only once for a specific combination of distribution  , metric
, metric 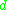 and Stein operator
and Stein operator 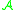 . However, if we have bounds in the general form (5.1), we usually are able to treat many probability metrics together. Furthermore as there is often a particular 'good' Stein operator for a distribution (e.g., no other operator than (2.3) has been used for the standard normal distribution up to now), one can often just start with the next step below, if bounds of the form (5.1) are already available (which is the case for many distributions).
. However, if we have bounds in the general form (5.1), we usually are able to treat many probability metrics together. Furthermore as there is often a particular 'good' Stein operator for a distribution (e.g., no other operator than (2.3) has been used for the standard normal distribution up to now), one can often just start with the next step below, if bounds of the form (5.1) are already available (which is the case for many distributions).
Now, at this point we could directly plug in our random variable which we want to approximate and try to find upper bounds. However, it is often fruitful to formulate a more general theorem using only abstract properties of
which we want to approximate and try to find upper bounds. However, it is often fruitful to formulate a more general theorem using only abstract properties of 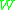 . Let us consider here the case of local dependence.
. Let us consider here the case of local dependence.
To this end, assume that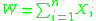 is a sum of random variables such that the
is a sum of random variables such that the 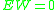 and variance
and variance
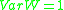 . Assume that, for every
. Assume that, for every 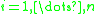 , there is a set
, there is a set 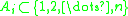 , such that
, such that 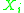 is independent of all the random variables
is independent of all the random variables 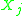 with
with 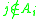 . We call this set the 'neighborhood' of
. We call this set the 'neighborhood' of 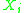 . Likewise let
. Likewise let 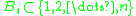 be a set such that all
be a set such that all 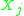 with
with  are independent of all
are independent of all 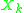 ,
,  . We can think of
. We can think of  as the neighbors in the neighborhood of
as the neighbors in the neighborhood of 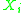 , a second-order neighborhood, so to speak. For a set
, a second-order neighborhood, so to speak. For a set 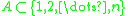 define now the sum
define now the sum 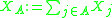 .
.
Using basically only Taylor expansion, it is possible to prove that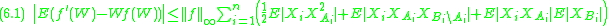
Note that, if we follow this line of argument, we can bound (1.1) only for functions where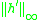 is bounded because of the third inequality of (5.2) (and in fact, if
is bounded because of the third inequality of (5.2) (and in fact, if 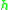 has discontinuities, so will
has discontinuities, so will 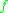 ). To obtain a bound similar to (6.1) which contains only the expressions
). To obtain a bound similar to (6.1) which contains only the expressions  and
and  , the argument is much more involved and the result is not as simple as (6.1); however, it can be done.
, the argument is much more involved and the result is not as simple as (6.1); however, it can be done.
Theorem A. If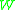 is as described above, we have for the Lipschitz metric
is as described above, we have for the Lipschitz metric 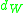 that
that
Proof. Recall that the Lipschitz metric is of the form (1.1) where the functions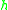 are Lipschitz-continuous with Lipschitz-constant 1, thus
are Lipschitz-continuous with Lipschitz-constant 1, thus 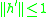 . Combining this with (6.1) and the last bound in (5.2) proves the theorem.
. Combining this with (6.1) and the last bound in (5.2) proves the theorem.
Thus, roughly speaking, we have proved that, to calculate the Lipschitz-distance between a with local dependence structure and a standard normal distribution, we only need to know the third moments of
with local dependence structure and a standard normal distribution, we only need to know the third moments of 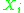 and the size of the neighborhoods
and the size of the neighborhoods 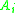 and
and 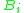 .
.
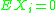 ,
, 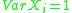 and
and 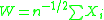 . We can take
. We can take 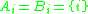 and we obtain from Theorem A that
and we obtain from Theorem A that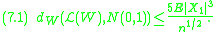
Another advanced book, but having some introductory character, is
A standard reference is the book by Stein,
which contains a lot of interesting material, but may be a little hard to understand at first reading.
Despite its age, there are few standard introductory books about Stein's method available. The following recent textbook has a chapter (Chapter 2) devoted to introducing Stein's method:
Although the book
is by large parts about Poisson approximation, it contains nevertheless a lot of information about the generator approach, in particular in the context of Poisson process approximation.
Probability theory
Probability theory is the branch of mathematics concerned with analysis of random phenomena. The central objects of probability theory are random variables, stochastic processes, and events: mathematical abstractions of non-deterministic events or measured quantities that may either be single...
to obtain bounds on the distance between two probability distributions with respect to a probability metric. It was introduced by Charles Stein, who first published it 1972, to obtain a bound between the distribution of a sum of
-dependent sequence of random variables and a standard normal distribution in the Kolmogorov (uniform) metric and hence to prove not only a central limit theoremCentral limit theorem
In probability theory, the central limit theorem states conditions under which the mean of a sufficiently large number of independent random variables, each with finite mean and variance, will be approximately normally distributed. The central limit theorem has a number of variants. In its common...
, but also bounds on the rates of convergence
Limit of a sequence
The limit of a sequence is, intuitively, the unique number or point L such that the terms of the sequence become arbitrarily close to L for "large" values of n...
for the given metric.
History
At the end of the 1960s, unsatisfied with the by-then known proofs of a specific central limit theoremCentral limit theorem
In probability theory, the central limit theorem states conditions under which the mean of a sufficiently large number of independent random variables, each with finite mean and variance, will be approximately normally distributed. The central limit theorem has a number of variants. In its common...
, Charles Stein developed a new way of proving the theorem for his statistics
Statistics
Statistics is the study of the collection, organization, analysis, and interpretation of data. It deals with all aspects of this, including the planning of data collection in terms of the design of surveys and experiments....
lecture.
The seminal paper was presented in 1970 at the sixth Berkeley Symposium and published in the corresponding proceedings.
Later, his Ph.D.
Ph.D.
A Ph.D. is a Doctor of Philosophy, an academic degree.Ph.D. may also refer to:* Ph.D. , a 1980s British group*Piled Higher and Deeper, a web comic strip*PhD: Phantasy Degree, a Korean comic series* PhD Docbook renderer, an XML renderer...
student Louis Chen Hsiao Yun
Louis Chen Hsiao Yun
Louis Chen Hsiao Yun is Tan Chin Tuan Centennial Professor of mathematics at the National University of Singapore.Yun earned his BSc from University of Singapore in 1964 and completed his MSc as well as PhD at Stanford University in 1969 and 1971 respectively. In 1972, he joined the Mathematics...
modified the method so as to obtain approximation results for the Poisson distribution
Poisson distribution
In probability theory and statistics, the Poisson distribution is a discrete probability distribution that expresses the probability of a given number of events occurring in a fixed interval of time and/or space if these events occur with a known average rate and independently of the time since...
, therefore the method is often referred to as Stein-Chen method. Whereas moderate attention was given to the new method in the 70s, it has undergone major development in the 80s, where many important contributions were made and on which today's view of the method are largely based. Probably the most important contributions are the monograph by Stein (1986), where he presents his view of the method and the concept of auxiliary randomisation, in particular using exchangeable pairs, and the articles by Barbour (1988) and Götze (1991), who introduced the so-called generator interpretation, which made it possible to easily adapt the method to many other probability distributions. An important contribution was also an article by Bolthausen (1984) on a long-standing open problem around the so-called combinatorial central limit theorem, which surely helped the method to become widely known.
In the 1990s the method was adapted to a variety of distributions, such as Gaussian process
Gaussian process
In probability theory and statistics, a Gaussian process is a stochastic process whose realisations consist of random values associated with every point in a range of times such that each such random variable has a normal distribution...
es by Barbour (1990), the binomial distribution by Ehm (1991), Poisson process
Poisson process
A Poisson process, named after the French mathematician Siméon-Denis Poisson , is a stochastic process in which events occur continuously and independently of one another...
es by Barbour and Brown (1992), the Gamma distribution by Luk (1994), and many others.
Probability metrics
Stein's method is a way to bound the distance of two probability distributions in a specific probability metric. To be tractable with the method, the metric must be given in the formHere,
and are probability measures on a measurable space , and are random variables with distribution and respectively, is the usual expectation operator and is a set of functions from to the real numbers. This set has to be large enough, so that the above definition indeed yields a metricMetric (mathematics)
In mathematics, a metric or distance function is a function which defines a distance between elements of a set. A set with a metric is called a metric space. A metric induces a topology on a set but not all topologies can be generated by a metric...
. Important examples are the total variation metric, where we let
consist of all the indicator functions of measurable sets, the Kolmogorov (uniform) metric for probability measures on the real numbers, where we consider all the half-line indicator functions, and the Lipschitz (first order Wasserstein; Kantorovich) metricWasserstein metric
In mathematics, the Wasserstein metric is a distance function defined between probability distributions on a given metric space M....
, where the underlying space is itself a metric space and we take the set
to be all Lipschitz-continuousLipschitz continuity
In mathematical analysis, Lipschitz continuity, named after Rudolf Lipschitz, is a strong form of uniform continuity for functions. Intuitively, a Lipschitz continuous function is limited in how fast it can change: for every pair of points on the graph of this function, the absolute value of the...
functions with Lipschitz-constant 1. However, note that not every metric can be represented in the form (1.1).
In what follows we think of
as a complicated distribution (e.g. a sum of dependent random variables), which we want to approximate by a much simpler and tractable distribution (e.g. the standard normal distribution to obtain a central limit theorem).The Stein operator
We assume now that the distribution is a fixed distribution; in what follows we shall in particular consider the case where is the standard normal distribution, which serves as a classical example of the application of Stein's method.First of all, we need an operator
which acts on functions from to the real numbers, and which 'characterizes' the distribution in the sense that the following equivalence holds:We call such an operator the Stein operator. For the standard normal distribution, Stein's lemma
Stein's lemma
Stein's lemma, named in honor of Charles Stein, is a theorem of probability theory that is of interest primarily because of its applications to statistical inference — in particular, to James–Stein estimation and empirical Bayes methods — and its applications to portfolio choice...
exactly yields such an operator:
thus we can take
We note that there are in general infinitely many such operators and it still remains an open question, which one to choose. However, it seems that for many distributions there is a particular good one, like (2.3) for the normal distribution.
There are different ways to find Stein operators. But by far the most important one is via generators. This approach was, as already mentioned, introduced by Barbour and Götze. Assume that
is a (homogeneous) continuous time Markov process taking values in . If has the stationary distributionStationary distribution
Stationary distribution may refer to:* The limiting distribution in a Markov chain* The marginal distribution of a stationary process or stationary time series* The set of joint probability distributions of a stationary process or stationary time series...
it is easy to see that, if is the generatorInfinitesimal generator (stochastic processes)
In mathematics — specifically, in stochastic analysis — the infinitesimal generator of a stochastic process is a partial differential operator that encodes a great deal of information about the process...
of
, we have for a large set of functions . Thus, generators are natural candidates for Stein operators and this approach will also help us for later computations.Setting up the Stein equation
Observe now that saying that is close to with respect to is equivalent to saying that the difference of expectations in (1.1) is close to 0, and indeed if it is equal to 0. We hope now that the operator exhibits the same behavior: clearly if we have and hopefully if we have .To make this statement rigorous we could find a function
, such that, for a given function ,so that the behavior of the right hand side is reproduced by the operator
and .However, this equation is too general. We solve instead the more specific equation
which is called Stein equation. Replacing
by and taking expectation with respect to , we are back to (3.1), which is what we effectively want. Now all the effort is worth only if the left hand side of (3.1) is easier to bound than the right hand side. This is, surprisingly, often the case.If
is the standard normal distribution and we use (2.3), the corresponding Stein equation iswhich is just an ordinary differential equation
Ordinary differential equation
In mathematics, an ordinary differential equation is a relation that contains functions of only one independent variable, and one or more of their derivatives with respect to that variable....
.
Solving the Stein equation
Now, in general, we cannot say much about how the equation (3.2) is to be solved. However, there are important cases, where we can.Analytic methods. We see from (3.3) that equation (3.2) can in particular be a differential equation
Differential equation
A differential equation is a mathematical equation for an unknown function of one or several variables that relates the values of the function itself and its derivatives of various orders...
(if
is concentrated on the integers, it will often turn out to be a difference equation). As there are many methods available to treat such equations, we can use them to solve the equation. For example, (3.3) can be easily solved explicitly:Generator method. If
is the generator of a Markov process as explained before, we can give a general solution to (3.2):where
denotes expectation with respect to the process being started in . However, one still has to prove that the solution (4.2) exists for all desired functions .Properties of the solution to the Stein equation
After showing the existence of a solution to (3.2) we can now try to analyze its properties. Usually, one tries to give bounds on and its derivatives (which has to be carefully defined if is a more complicated space) or differences in terms of and its derivatives or differences, that is, inequalities of the formfor some specific
(typically or , respectively, depending on the form of the Stein operator) and where often is taken to be the supremum norm. Here, denotes the differential operatorDifferential operator
In mathematics, a differential operator is an operator defined as a function of the differentiation operator. It is helpful, as a matter of notation first, to consider differentiation as an abstract operation, accepting a function and returning another .This article considers only linear operators,...
, but in discrete settings it usually refers to a difference operator. The constants
may contain the parameters of the distribution . If there are any, they are often referred to as Stein factors or magic factors.In the case of (4.1) we can prove for the supremum norm that
where the last bound is of course only applicable if
is differentiable (or at least Lipschitz-continuous, which, for example, is not the case if we regard the total variation metric or the Kolmogorov metric!). As the standard normal distribution has no extra parameters, in this specific case, the constants are free of additional parameters.Note that, up to this point, we did not make use of the random variable
. So, the steps up to here in general have to be calculated only once for a specific combination of distribution , metric and Stein operator . However, if we have bounds in the general form (5.1), we usually are able to treat many probability metrics together. Furthermore as there is often a particular 'good' Stein operator for a distribution (e.g., no other operator than (2.3) has been used for the standard normal distribution up to now), one can often just start with the next step below, if bounds of the form (5.1) are already available (which is the case for many distributions).An abstract approximation theorem
We are now in a position to bound the left hand side of (3.1). As this step heavily depends on the form of the Stein operator, we directly regard the case of the standard normal distribution.Now, at this point we could directly plug in our random variable
which we want to approximate and try to find upper bounds. However, it is often fruitful to formulate a more general theorem using only abstract properties of . Let us consider here the case of local dependence.To this end, assume that
is a sum of random variables such that the and varianceVariance
In probability theory and statistics, the variance is a measure of how far a set of numbers is spread out. It is one of several descriptors of a probability distribution, describing how far the numbers lie from the mean . In particular, the variance is one of the moments of a distribution...
. Assume that, for every , there is a set , such that is independent of all the random variables with . We call this set the 'neighborhood' of . Likewise let be a set such that all with are independent of all , . We can think of as the neighbors in the neighborhood of , a second-order neighborhood, so to speak. For a set define now the sum .Using basically only Taylor expansion, it is possible to prove that
Note that, if we follow this line of argument, we can bound (1.1) only for functions where
is bounded because of the third inequality of (5.2) (and in fact, if has discontinuities, so will ). To obtain a bound similar to (6.1) which contains only the expressions and , the argument is much more involved and the result is not as simple as (6.1); however, it can be done.Theorem A. If
is as described above, we have for the Lipschitz metric thatProof. Recall that the Lipschitz metric is of the form (1.1) where the functions
are Lipschitz-continuous with Lipschitz-constant 1, thus . Combining this with (6.1) and the last bound in (5.2) proves the theorem.Thus, roughly speaking, we have proved that, to calculate the Lipschitz-distance between a
with local dependence structure and a standard normal distribution, we only need to know the third moments of and the size of the neighborhoods and .Application of the theorem
We can treat the case of sums of independent and identically distributed random variables with Theorem A. So assume now that, and . We can take and we obtain from Theorem A thatConnections to other methods
- Lindeberg's method. LindebergJarl Waldemar LindebergJarl Waldemar Lindeberg was a Finnish mathematician known for work on the central limit theorem....
(1922) introduced in a seminal article a method, where the difference in (1.1) is directly bounded. This method usually also heavily relies on Taylor expansion and thus shows some similarities with Stein's method.
- Tikhomirov's method. Clearly the approach via (1.1) and (3.1) does not involve characteristic functionsCharacteristic function (probability theory)In probability theory and statistics, the characteristic function of any random variable completely defines its probability distribution. Thus it provides the basis of an alternative route to analytical results compared with working directly with probability density functions or cumulative...
. However, Tikhomirov (1980) presented a proof of a central limit theorem based on characteristic functions and a differential operator similar to (2.3). The basic observation is that the characteristic function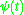 of the standard normal distribution satisfies the differential equation
of the standard normal distribution satisfies the differential equation  for all
for all  . Thus, if the characteristic function
. Thus, if the characteristic function  of
of  is such that
is such that 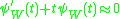 we expect that
we expect that 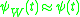 and hence that
and hence that 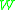 is close to the normal distribution. Tikhomirov states in his paper that he was inspired by Stein's seminal paper.
is close to the normal distribution. Tikhomirov states in his paper that he was inspired by Stein's seminal paper.
Literature
The following text is advanced, and gives a comprehensive overview of the normal caseAnother advanced book, but having some introductory character, is
A standard reference is the book by Stein,
which contains a lot of interesting material, but may be a little hard to understand at first reading.
Despite its age, there are few standard introductory books about Stein's method available. The following recent textbook has a chapter (Chapter 2) devoted to introducing Stein's method:
Although the book
is by large parts about Poisson approximation, it contains nevertheless a lot of information about the generator approach, in particular in the context of Poisson process approximation.