

SUBCLU
Encyclopedia
SUBCLU is an algorithm for clustering high-dimensional data
by Karin Kailing, Hans-Peter Kriegel
and Peer Kröger. It is a subspace clustering algorithm that builds on the density-based clustering algorithm DBSCAN
. SUBCLU can find clusters in axis-parallel subspaces, and uses a bottom-up
, greedy
strategy to remain efficient.
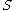 , then each subspace
, then each subspace  also contains a cluster. However, a cluster
also contains a cluster. However, a cluster 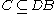 in subspace
in subspace 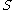 is not necessarily a cluster in
is not necessarily a cluster in 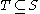 , since clusters are required to be maximal, and more objects might be contained in the cluster in
, since clusters are required to be maximal, and more objects might be contained in the cluster in 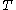 that contains
that contains 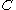 . However, a density-connected set
. However, a density-connected set
in a subspace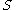 is also a density-connected set in
is also a density-connected set in 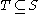 .
.
This downward-closure property is utilized by SUBCLU in a way similar to the Apriori algorithm
: first, all 1-dimensional subspaces are clustered. All clusters in a higher-dimensional subspace will be subsets of the clusters detected in this first clustering. SUBCLU hence recursively produces -dimensional candidate subspaces by combining
-dimensional candidate subspaces by combining 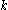 -dimensional subspaces with clusters sharing
-dimensional subspaces with clusters sharing  attributes. After pruning irrelevant candidates, DBSCAN
attributes. After pruning irrelevant candidates, DBSCAN
is applied to the candidate subspace to find out if it still contains clusters. If it does, the candidate subspace is used for the next combination of subspaces. In order to improve the runtime of DBSCAN
, only the points known to belong to clusters in one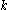 -dimensional subspace (which is chosen to contain as little clusters as possible) are considered. Due to the downward-closure property, other point cannot be part of a
-dimensional subspace (which is chosen to contain as little clusters as possible) are considered. Due to the downward-closure property, other point cannot be part of a  -dimensional cluster anyway.
-dimensional cluster anyway.
 and
and 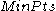 , which serve the same role as in DBSCAN
, which serve the same role as in DBSCAN
. In a first step, DBSCAN is used to find 1D-clusters in each subspace spanned by a single attribute:

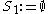
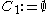
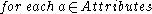
In a second step, -dimensional clusters are built from
-dimensional clusters are built from 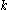 -dimensional ones:
-dimensional ones:
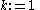
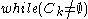
The set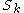 contains all the
contains all the 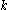 -dimensional subspaces that are known to contain clusters. The set
-dimensional subspaces that are known to contain clusters. The set 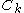 contains the sets of clusters found in the subspaces. The
contains the sets of clusters found in the subspaces. The 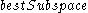 is chosen to minimize the runs of DBSCAN (and the number of points that need to be considered in each run) for finding the clusters in the candidate subspaces.
is chosen to minimize the runs of DBSCAN (and the number of points that need to be considered in each run) for finding the clusters in the candidate subspaces.
Candidate subspaces are generated much alike the Apriori algorithm
generates the frequent itemset candidates: Pairs of the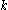 -dimensional subspaces are compared, and if they differ in one attribute only, they form a
-dimensional subspaces are compared, and if they differ in one attribute only, they form a  -dimensional candidate. However, a number of irrelevant candidates are found as well; they contain a
-dimensional candidate. However, a number of irrelevant candidates are found as well; they contain a 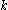 -dimensional subspace that does not contain a cluster. Hence, these candidates are removed in a second step:
-dimensional subspace that does not contain a cluster. Hence, these candidates are removed in a second step:

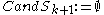
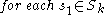
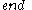
.
Clustering high-dimensional data
Clustering high-dimensional data is the cluster analysis of data with anywhere from a few dozen to many thousands of dimensions. Such high-dimensional data spaces are often encountered in areas such as medicine, where DNA microarray technology can produce a large number of measurements at once, and...
by Karin Kailing, Hans-Peter Kriegel
Hans-Peter Kriegel
Hans-Peter Kriegel is a German computer scientist and professor at the Ludwig Maximilian University of Munich and leading the Database Systems Group in the Department of Computer Science....
and Peer Kröger. It is a subspace clustering algorithm that builds on the density-based clustering algorithm DBSCAN
DBSCAN
DBSCAN is a data clustering algorithm proposed by Martin Ester, Hans-Peter Kriegel, Jörg Sander and Xiaowei Xu in 1996....
. SUBCLU can find clusters in axis-parallel subspaces, and uses a bottom-up
Top-down and bottom-up design
Top–down and bottom–up are strategies of information processing and knowledge ordering, mostly involving software, but also other humanistic and scientific theories . In practice, they can be seen as a style of thinking and teaching...
, greedy
Greedy algorithm
A greedy algorithm is any algorithm that follows the problem solving heuristic of making the locally optimal choice at each stagewith the hope of finding the global optimum....
strategy to remain efficient.
Approach
SUBCLU uses a monotonicity criteria: if a cluster is found in a subspace, then each subspace also contains a cluster. However, a cluster in subspace is not necessarily a cluster in , since clusters are required to be maximal, and more objects might be contained in the cluster in that contains . However, a density-connected setDBSCAN
DBSCAN is a data clustering algorithm proposed by Martin Ester, Hans-Peter Kriegel, Jörg Sander and Xiaowei Xu in 1996....
in a subspace
is also a density-connected set in .This downward-closure property is utilized by SUBCLU in a way similar to the Apriori algorithm
Apriori algorithm
In computer science and data mining, Apriori is a classic algorithm for learning association rules. Apriori is designed to operate on databases containing transactions...
: first, all 1-dimensional subspaces are clustered. All clusters in a higher-dimensional subspace will be subsets of the clusters detected in this first clustering. SUBCLU hence recursively produces
-dimensional candidate subspaces by combining -dimensional subspaces with clusters sharing attributes. After pruning irrelevant candidates, DBSCANDBSCAN
DBSCAN is a data clustering algorithm proposed by Martin Ester, Hans-Peter Kriegel, Jörg Sander and Xiaowei Xu in 1996....
is applied to the candidate subspace to find out if it still contains clusters. If it does, the candidate subspace is used for the next combination of subspaces. In order to improve the runtime of DBSCAN
DBSCAN
DBSCAN is a data clustering algorithm proposed by Martin Ester, Hans-Peter Kriegel, Jörg Sander and Xiaowei Xu in 1996....
, only the points known to belong to clusters in one
-dimensional subspace (which is chosen to contain as little clusters as possible) are considered. Due to the downward-closure property, other point cannot be part of a -dimensional cluster anyway.Pseudocode
SUBCLU takes two parameters, and , which serve the same role as in DBSCANDBSCAN
DBSCAN is a data clustering algorithm proposed by Martin Ester, Hans-Peter Kriegel, Jörg Sander and Xiaowei Xu in 1996....
. In a first step, DBSCAN is used to find 1D-clusters in each subspace spanned by a single attribute:
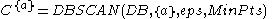
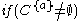
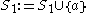
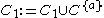
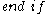
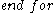
In a second step,
-dimensional clusters are built from -dimensional ones:
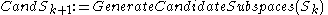
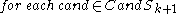

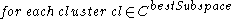
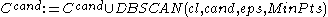
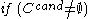
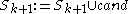
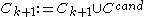
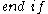

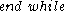
The set
contains all the -dimensional subspaces that are known to contain clusters. The set contains the sets of clusters found in the subspaces. The is chosen to minimize the runs of DBSCAN (and the number of points that need to be considered in each run) for finding the clusters in the candidate subspaces.Candidate subspaces are generated much alike the Apriori algorithm
Apriori algorithm
In computer science and data mining, Apriori is a classic algorithm for learning association rules. Apriori is designed to operate on databases containing transactions...
generates the frequent itemset candidates: Pairs of the
-dimensional subspaces are compared, and if they differ in one attribute only, they form a -dimensional candidate. However, a number of irrelevant candidates are found as well; they contain a -dimensional subspace that does not contain a cluster. Hence, these candidates are removed in a second step:
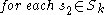
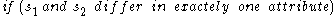
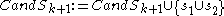
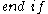

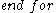
- // Pruning of irrelevant candidate subspaces

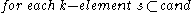
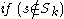
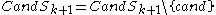

Availability
An example implementation of SUBCLU is available in the ELKI frameworkEnvironment for DeveLoping KDD-Applications Supported by Index-Structures
ELKI is a knowledge discovery in databases software framework developed for use in research and teaching by the database systems research unit of Professor Hans-Peter Kriegel at the Ludwig Maximilian University of Munich, Germany...
.