

Patent visualisation
Encyclopedia
Patent visualisation is an application of information visualisation. Patents number has been increasing , thus forcing companies to consider intellectual property as a part of their strategy.. So patent visualisation like patent mapping
is used to quickly view patents portfolio.
Patent visualisation dedicated software began to appear in 2000 like Aureka from Aurigin now owned by Thomson Reuters
. Taking advantage of the innate visual language, software have been developed to convert patents in clear infographics or maps, to allow the analyst to "get insight into the data" and draw conclusions. Also referred as patinformatics, it is the "science of analysing patent information to discover relationsips and trends that would be difficult to see when working with patent documents on a one-and-one basis".
Patents contain two types of information: Structured data like publication number which are processed by data-mining and unstructured text like title, abstract and claims which are used with text mining
.
has emerged in the late 1980s. Used in computer science and genetic algorithms, data mining is the union of statistics, artificial intelligence and machine learning to assist in the analysis of patents. Patent data mining extracts information from the structured data of the patent document. These structured data are bibliographic fields like location or date or status :
Text mining is based on a statistical approach of words recurrence or occurrence in the patents corpus. An algorithm decomposes the corpus into a text sea, extracts words and expressions from title, summary and claims and gather them by declension. The conjunctions such as "and" or "if" are labeled as non-information bearing words and are stored in the stopword list. These stoplists can be personalized, in order to create an accurate analysis. Next, the algorithm will rank the words by weight, according to their frequency in the patent's corpus and the documents frequency containing this word. It literally fishes the whole Text Sea for words or expressions and counts their occurrence. The score for each word is calculated using this formula :
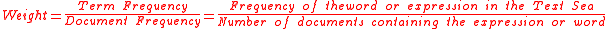
According to this, a frequently used word in several documents will have less weight or score than a frequently used word in a few patents. Words under a minimum weight are eliminated, only to have left a list of n pertinent words or descriptors. Then each patent is associated to the descriptors found in the selected document. Further, in the process of clusterization, these descriptors are used as subsets, in which the patent are regrouped or they can be used as tags to place the patents in predetermined categories for example keywords from International Patent Classifications.
There are four different full-text parts that can be processed with text-mining :
Software offer different combinations but using title, abstract and claim is generally the most used, having a good balance between interferences and relevancy.
Field application:
Patent map
A patent map is a graphical model of patent visualisation. This practice "enables companies to identify the patents in a particular technology space, verify the characteristics of these patents, and .....
is used to quickly view patents portfolio.
Patent visualisation dedicated software began to appear in 2000 like Aureka from Aurigin now owned by Thomson Reuters
Thomson Reuters
Thomson Reuters Corporation is a provider of information for the world's businesses and professionals and is created by the Thomson Corporation's purchase of Reuters Group on 17 April 2008. Thomson Reuters is headquartered at 3 Times Square, New York City, USA...
. Taking advantage of the innate visual language, software have been developed to convert patents in clear infographics or maps, to allow the analyst to "get insight into the data" and draw conclusions. Also referred as patinformatics, it is the "science of analysing patent information to discover relationsips and trends that would be difficult to see when working with patent documents on a one-and-one basis".
Patents contain two types of information: Structured data like publication number which are processed by data-mining and unstructured text like title, abstract and claims which are used with text mining
Text mining
Text mining, sometimes alternately referred to as text data mining, roughly equivalent to text analytics, refers to the process of deriving high-quality information from text. High-quality information is typically derived through the devising of patterns and trends through means such as...
.
Datamining
The main step in processing structured information lies on data-mining. Data miningData mining
Data mining , a relatively young and interdisciplinary field of computer science is the process of discovering new patterns from large data sets involving methods at the intersection of artificial intelligence, machine learning, statistics and database systems...
has emerged in the late 1980s. Used in computer science and genetic algorithms, data mining is the union of statistics, artificial intelligence and machine learning to assist in the analysis of patents. Patent data mining extracts information from the structured data of the patent document. These structured data are bibliographic fields like location or date or status :
Structured fields
| Structured data | Description | Business Intelligence use |
|---|---|---|
| Datas | Patent contain different identifying data such as priority, publication data and the issue date
|
Priority application data often propose information such as priority country. Crossing dates and locations fields offer a global vision of a technology in time and space. |
| Assignee | Patent assignees are organizations or individuals, owners of the patent's invention. | The field can offer a ranking of the principal actors of the environment thus allowing seeing potential competitors or partners. |
| Inventor | Inventors developed the invention | Inventors field combined to the assignee field can create a social network and follow field experts. |
| Classification | The classification will regroup inventions with similar technologies. The most commonly used is the International Patent Classification IPC. However patent organizations have their own classification for instance the European Patent Office with ECLA. | Grouping patents by thematics offers an overview of the corpus and the potential applications of studied technology. |
| Status | The legal status is an easy way to access report that lets you view the legal status for all members of a patent family in a single view. | Patent family and legal status searching is very important for litigation and even competitive intelligence. |
Advantages
Data mining offers a statistical analysis tool to study filing patterns of competitors, locate the main patent flers within a specific area of technology. This type of approach can be very helpful to monitor competitors environment, moves and innovation trends and gives a macro-view of a technology status in order to evaluates its maturity and complexity.Principle
Text-mining is used to search through unstructured full-text patents. This technique is very well known due to the Internet development, its success in bioinformatics and now in the intellectual property environment.Text mining is based on a statistical approach of words recurrence or occurrence in the patents corpus. An algorithm decomposes the corpus into a text sea, extracts words and expressions from title, summary and claims and gather them by declension. The conjunctions such as "and" or "if" are labeled as non-information bearing words and are stored in the stopword list. These stoplists can be personalized, in order to create an accurate analysis. Next, the algorithm will rank the words by weight, according to their frequency in the patent's corpus and the documents frequency containing this word. It literally fishes the whole Text Sea for words or expressions and counts their occurrence. The score for each word is calculated using this formula :
According to this, a frequently used word in several documents will have less weight or score than a frequently used word in a few patents. Words under a minimum weight are eliminated, only to have left a list of n pertinent words or descriptors. Then each patent is associated to the descriptors found in the selected document. Further, in the process of clusterization, these descriptors are used as subsets, in which the patent are regrouped or they can be used as tags to place the patents in predetermined categories for example keywords from International Patent Classifications.
There are four different full-text parts that can be processed with text-mining :
- Title
- Abstract
- Claim
- Patent Full-Text
Software offer different combinations but using title, abstract and claim is generally the most used, having a good balance between interferences and relevancy.
Advantages
Text-mining approache has numerous advantages. First, it is useful to narrow down a search or quickly evaluate a patent corpus. For instance, if a query has taken irrelevant documents, a multi level clustering hierarchy will identify them in order to delete them and refine the search. Moreover, this approach offers the possibility to create internal taxonomies specific to a corpus, thus preparing possible mapping.Visualisations
This art of allying patent analysis and informatic tools offers an overview of the environment through value-added visualisations. As patent contain two types of information, structured and unstructured one, visualisations can be distinguished in two categories. Structured data can be rendered with data mining in macrothematic maps and statistical analysis. Whereas unstructured information extracted by text-mining are represented in a more intuitive way like clouds, cluster maps, 2D keyword map.Data mining visualisation
| Visualisation | Picture | Description | Business Intelligence use |
|---|---|---|---|
| Matrix chart | Picture | Graphic organizer used to summarize a multidimensional data set in a grid | Data comparison |
| Location map | Picture | Map with overlaid data values on geographic regions |
|
| Bar chart Bar chart A bar chart or bar graph is a chart with rectangular bars with lengths proportional to the values that they represent. The bars can be plotted vertically or horizontally.... |
Picture | Graph with rectangular bars proportional to the values that they represent, useful for numerical comparisons. | Data evolution |
| Line graph Line graph In graph theory, the line graph L of undirected graph G is another graph L that represents the adjacencies between edges of G... |
Picture | Graph used to summarize how two parameters are related and how they vary. | Data evolution and relationships |
| Pie chart Pie chart A pie chart is a circular chart divided into sectors, illustrating proportion. In a pie chart, the arc length of each sector , is proportional to the quantity it represents. When angles are measured with 1 turn as unit then a number of percent is identified with the same number of centiturns... |
Picture | Circular chart divided into sections, to illustrate proportions. | Data comparison |
Text mining visualisation
| Visualisation | Description | Business Intelligence use |
|---|---|---|
| Tree list Tree (data structure) In computer science, a tree is a widely-used data structure that emulates a hierarchical tree structure with a set of linked nodes.Mathematically, it is an ordered directed tree, more specifically an arborescence: an acyclic connected graph where each node has zero or more children nodes and at... |
Hierarchy list |
|
| Tag cloud Tag cloud A tag cloud is a visual representation for text data, typically used to depict keyword metadata on websites, or to visualize free form text. 'Tags' are usually single words, and the importance of each tag is shown with font size or color... |
Full text of concepts. The size of each word is determined by its frequency in the corpus |
|
| 2D keyword map | Tomographic map with quantitative representation of relief, usually using contour lines and colors. Distance on the map will be proportional to the difference between patent themes |
Som Som may refer to:* Som * Som, Uttar Pradesh, India* Som, slang for sommelier* Som, an alternative name for the Hungarian wine grape Furmint* Som , a Bengali Indian surname... |
{kind=link}
Visualisation for both data-mining and text-mining
Mapping visualisations can be used for both text-mining and data-mining results.| Visualisation | Picture | Description | Business Intelligence use |
|---|---|---|---|
| Tree Map | Picture | Visualization of hierarchical structures. Each data item, or row in the data set, is represented by a rectangle, whose area is proportional to selected parameters. |
|
| Network map Network Mapping Network mapping is the study of the physical connectivity of networks. Internet mapping is the study of the physical connectivity of the Internet. Network mapping often attempts to determine the servers and operating systems run on networks... |
Picture | In a network diagram, entities are connected to each other in the form of a node and link diagram. |
|
Uses
What can patent visualisation highlights:- Competitors
- Partners
- New innovations
- Technologic environment description
- NetworksComputer networkA computer network, often simply referred to as a network, is a collection of hardware components and computers interconnected by communication channels that allow sharing of resources and information....
Field application:
- R&D strategy management
- Competitive intelligenceCompetitive intelligenceA broad definition of competitive intelligence is the action of defining, gathering, analyzing, and distributing intelligence about products, customers, competitors and any aspect of the environment needed to support executives and managers in making strategic decisions for an organization.Key...
- Licensing
- Strategy