

Multiple-try Metropolis
Encyclopedia
In Markov chain Monte Carlo
, the Metropolis–Hastings algorithm (MH) can be used to sample from a probability distribution
which is difficult to sample from directly. However, the MH algorithm requires the user to supply a proposal distribution, which can be relatively arbitrary. In many cases, one uses a Gaussian distribution centered on the current point in the probability space, of the form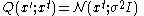 . This proposal distribution is convenient to sample from and may be the best choice if one has little knowledge about the target distribution,
. This proposal distribution is convenient to sample from and may be the best choice if one has little knowledge about the target distribution,  . If desired, one can use the more general multivariate normal distribution,
. If desired, one can use the more general multivariate normal distribution, 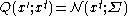 , where
, where  is the covariance matrix which the user believes is similar to the target distribution.
is the covariance matrix which the user believes is similar to the target distribution.
Although this method must converge to the stationary distribution in the limit of infinite sample size, in practice the progress can be exceedingly slow. If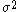 is too large, almost all steps under the MH algorithm will be rejected. On the other hand, if
is too large, almost all steps under the MH algorithm will be rejected. On the other hand, if 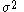 is too small, almost all steps will be accepted, and the Markov chain will be similar to a random walk through the probability space. In the simpler case of
is too small, almost all steps will be accepted, and the Markov chain will be similar to a random walk through the probability space. In the simpler case of 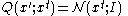 , we see that
, we see that 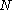 steps only takes us a distance of
steps only takes us a distance of 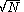 . In this event, the Markov Chain will not fully explore the probability space in any reasonable amount of time. Thus the MH algorithm requires reasonable tuning of the scale parameter (
. In this event, the Markov Chain will not fully explore the probability space in any reasonable amount of time. Thus the MH algorithm requires reasonable tuning of the scale parameter (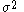 or
or 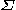 ).
).
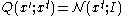 . In one dimension, this corresponds to a Gaussian distribution with mean 0 and variance 1. For one dimension, this distribution has a mean step of zero, however the mean squared step size is given by
. In one dimension, this corresponds to a Gaussian distribution with mean 0 and variance 1. For one dimension, this distribution has a mean step of zero, however the mean squared step size is given by
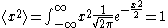
As the number of dimensions increases, the expected step size becomes larger and larger. In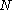 dimensions, the probability of moving a radial distance
dimensions, the probability of moving a radial distance 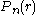 is related to the Chi distribution, and is given by
is related to the Chi distribution, and is given by
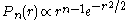
This distribution is peaked at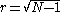 which is
which is 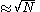 for large
for large 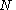 . This means that the step size will increase as the roughly the square root of the number of dimensions. For the MH algorithm, large steps will almost always land in regions of low probability, and therefore be rejected.
. This means that the step size will increase as the roughly the square root of the number of dimensions. For the MH algorithm, large steps will almost always land in regions of low probability, and therefore be rejected.
If we now add the scale parameter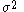 back in, we find that to retain a reasonable acceptance rate, we must make the transformation
back in, we find that to retain a reasonable acceptance rate, we must make the transformation 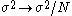 . In this situation, the acceptance rate can now be made reasonable, but the exploration of the probability space becomes increasingly slow. To see this, consider a slice along any one dimension of the problem. By making the scale transformation above, the expected step size is any one dimension is not
. In this situation, the acceptance rate can now be made reasonable, but the exploration of the probability space becomes increasingly slow. To see this, consider a slice along any one dimension of the problem. By making the scale transformation above, the expected step size is any one dimension is not 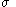 but instead is
but instead is 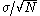 . As this step size is much smaller than the "true" scale of the probability distribution (assuming that
. As this step size is much smaller than the "true" scale of the probability distribution (assuming that 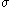 is somehow known a priori, which is the best possible case), the algorithm executes a random walk along every parameter.
is somehow known a priori, which is the best possible case), the algorithm executes a random walk along every parameter.
Suppose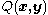 is an arbitrary proposal function. We require that
is an arbitrary proposal function. We require that 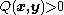 only if
only if 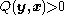 . Additionally,
. Additionally, 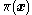 is the likelihood function.
is the likelihood function.
Define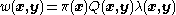 where
where 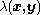 is a non-negative symmetric function in
is a non-negative symmetric function in 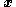 and
and 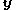 that can be chosen by the user.
that can be chosen by the user.
Now suppose the current state is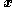 . The MTM algorithm is as follows:
. The MTM algorithm is as follows:
1) Draw k independent trial proposals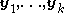 from
from 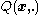 . Compute the weights
. Compute the weights 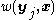 for each of these.
for each of these.
2) Select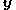 from the
from the 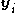 with probability proportional to the weights.
with probability proportional to the weights.
3) Now produce a reference set by drawing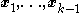 from the distribution
from the distribution 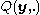 . Set
. Set 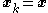 (the current point).
(the current point).
4) Accept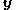 with probability
with probability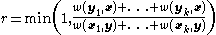
It can be shown that this method satisfies the detailed balance
property and therefore produces a reversible Markov chain with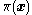 as the stationary distribution.
as the stationary distribution.
If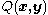 is symmetric (as is the case for the multivariate normal distribution), then one can choose
is symmetric (as is the case for the multivariate normal distribution), then one can choose 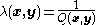 which gives
which gives 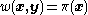
Markov chain Monte Carlo
Markov chain Monte Carlo methods are a class of algorithms for sampling from probability distributions based on constructing a Markov chain that has the desired distribution as its equilibrium distribution. The state of the chain after a large number of steps is then used as a sample of the...
, the Metropolis–Hastings algorithm (MH) can be used to sample from a probability distribution
Probability distribution
In probability theory, a probability mass, probability density, or probability distribution is a function that describes the probability of a random variable taking certain values....
which is difficult to sample from directly. However, the MH algorithm requires the user to supply a proposal distribution, which can be relatively arbitrary. In many cases, one uses a Gaussian distribution centered on the current point in the probability space, of the form
. This proposal distribution is convenient to sample from and may be the best choice if one has little knowledge about the target distribution, . If desired, one can use the more general multivariate normal distribution, , where is the covariance matrix which the user believes is similar to the target distribution.Although this method must converge to the stationary distribution in the limit of infinite sample size, in practice the progress can be exceedingly slow. If
is too large, almost all steps under the MH algorithm will be rejected. On the other hand, if is too small, almost all steps will be accepted, and the Markov chain will be similar to a random walk through the probability space. In the simpler case of , we see that steps only takes us a distance of . In this event, the Markov Chain will not fully explore the probability space in any reasonable amount of time. Thus the MH algorithm requires reasonable tuning of the scale parameter ( or ).Problems with high dimensionality
Even if the scale parameter is well-tuned, as the dimensionality of the problem increases, progress can still remain exceedingly slow. To see this, again consider. In one dimension, this corresponds to a Gaussian distribution with mean 0 and variance 1. For one dimension, this distribution has a mean step of zero, however the mean squared step size is given byAs the number of dimensions increases, the expected step size becomes larger and larger. In
dimensions, the probability of moving a radial distance is related to the Chi distribution, and is given byThis distribution is peaked at
which is for large . This means that the step size will increase as the roughly the square root of the number of dimensions. For the MH algorithm, large steps will almost always land in regions of low probability, and therefore be rejected.If we now add the scale parameter
back in, we find that to retain a reasonable acceptance rate, we must make the transformation . In this situation, the acceptance rate can now be made reasonable, but the exploration of the probability space becomes increasingly slow. To see this, consider a slice along any one dimension of the problem. By making the scale transformation above, the expected step size is any one dimension is not but instead is . As this step size is much smaller than the "true" scale of the probability distribution (assuming that is somehow known a priori, which is the best possible case), the algorithm executes a random walk along every parameter.Multiple-try Metropolis
Liu et al. (2000) have suggested a modified MH algorithm, which they call the Multiple-try Metropolis algorithm (MTM), which allows larger step sizes whilst still retaining a reasonable acceptance rate.Suppose
is an arbitrary proposal function. We require that only if . Additionally, is the likelihood function.Define
where is a non-negative symmetric function in and that can be chosen by the user.Now suppose the current state is
. The MTM algorithm is as follows:1) Draw k independent trial proposals
from . Compute the weights for each of these.2) Select
from the with probability proportional to the weights.3) Now produce a reference set by drawing
from the distribution . Set (the current point).4) Accept
with probabilityIt can be shown that this method satisfies the detailed balance
Detailed balance
The principle of detailed balance is formulated for kinetic systems which are decomposed into elementary processes : At equilibrium, each elementary process should be equilibrated by its reverse process....
property and therefore produces a reversible Markov chain with
as the stationary distribution.If
is symmetric (as is the case for the multivariate normal distribution), then one can choose which gives See also
- Markov chain Monte CarloMarkov chain Monte CarloMarkov chain Monte Carlo methods are a class of algorithms for sampling from probability distributions based on constructing a Markov chain that has the desired distribution as its equilibrium distribution. The state of the chain after a large number of steps is then used as a sample of the...
- Metropolis–Hastings algorithm
- Detailed balanceDetailed balanceThe principle of detailed balance is formulated for kinetic systems which are decomposed into elementary processes : At equilibrium, each elementary process should be equilibrated by its reverse process....