
Layered hidden Markov model
Encyclopedia
The layered hidden Markov model
(LHMM) is a statistical model
derived from the hidden Markov model (HMM).
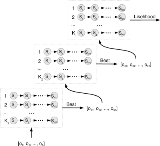
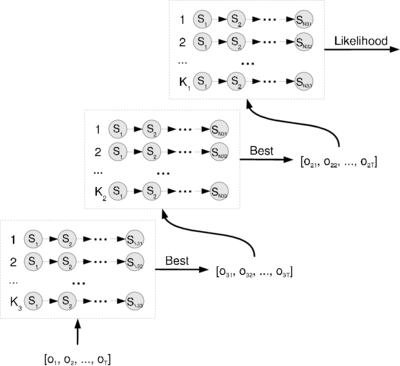
A layered hidden Markov model (LHMM) consists of N levels of HMMs, where the HMMs on level i + 1 correspond to observation symbols or probability generators at level i.
Every level i of the LHMM consists of Ki HMMs running in parallel.
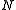 levels of HMMs where the HMMs on level
levels of HMMs where the HMMs on level 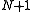 corresponds to observation symbols or probability generators at level
corresponds to observation symbols or probability generators at level 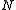 .
.
Every level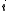 of the LHMM consists of
of the LHMM consists of 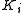 HMMs running in parallel.
HMMs running in parallel.
 At any given level
At any given level 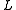 in the LHMM a sequence of
in the LHMM a sequence of 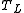 observation symbols
observation symbols
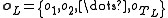 can be used to classify the input into one of
can be used to classify the input into one of 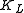 classes, where each class corresponds to each of the
classes, where each class corresponds to each of the 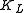 HMMs at level
HMMs at level 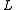 . This classification can then be used to generate a new observation for the level
. This classification can then be used to generate a new observation for the level 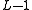 HMMs. At the lowest layer, i.e. level
HMMs. At the lowest layer, i.e. level 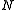 , primitive observation symbols
, primitive observation symbols 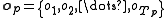 would be generated directly from observations of the modeled process. For example in a trajectory tracking task the primitive observation symbols would originate from the quantized sensor values. Thus at each layer in the LHMM the observations originate from the classification of the underlying layer, except for the lowest layer where the observation symbols originate from measurements of the observed process.
would be generated directly from observations of the modeled process. For example in a trajectory tracking task the primitive observation symbols would originate from the quantized sensor values. Thus at each layer in the LHMM the observations originate from the classification of the underlying layer, except for the lowest layer where the observation symbols originate from measurements of the observed process.
It is not necessary to run all levels at the same time granularity. For example it is possible to use windowing at any level in the structure so that the classification takes the average of several classifications into consideration before passing the results up the layers of the LHMM.
Instead of simply using the winning HMM at level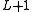 as an input symbol for the HMM at level
as an input symbol for the HMM at level 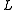 it is possible to use it as a probability generator by passing the complete probability distribution
it is possible to use it as a probability generator by passing the complete probability distribution
up the layers of the LHMM. Thus instead of having a "winner takes all" strategy where the most probable HMM is selected as an observation symbol, the likelihood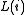 of observing the
of observing the 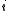 th HMM can be used in the recursion formula of the level
th HMM can be used in the recursion formula of the level 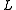 HMM to account for the uncertainty in the classification of the HMMs at level
HMM to account for the uncertainty in the classification of the HMMs at level 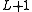 . Thus, if the classification of the HMMs at level
. Thus, if the classification of the HMMs at level 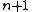 is uncertain, it is possible to pay more attention to the a-priori information encoded in the HMM at level
is uncertain, it is possible to pay more attention to the a-priori information encoded in the HMM at level  .
.
A LHMM could in practice be transformed into a single layered HMM where all the different models are concatenated together. Some of the advantages that may be expected from using the LHMM over a large single layer HMM is that the LHMM is less likely to suffer from over-fitting since the individual sub-components are trained independently on smaller amounts of data. A consequence of this is that a significantly smaller amount of training data is required for the LHMM to achieve a performance comparable of the HMM. Another advantage is that the layers at the bottom of the LHMM, which are more sensitive to changes in the environment such as the type of sensors, sampling rate etc, can be retrained separately without altering the higher layers of the LHMM.
Hidden Markov model
A hidden Markov model is a statistical Markov model in which the system being modeled is assumed to be a Markov process with unobserved states. An HMM can be considered as the simplest dynamic Bayesian network. The mathematics behind the HMM was developed by L. E...
(LHMM) is a statistical model
Statistical model
A statistical model is a formalization of relationships between variables in the form of mathematical equations. A statistical model describes how one or more random variables are related to one or more random variables. The model is statistical as the variables are not deterministically but...
derived from the hidden Markov model (HMM).
A layered hidden Markov model (LHMM) consists of N levels of HMMs, where the HMMs on level i + 1 correspond to observation symbols or probability generators at level i.
Every level i of the LHMM consists of Ki HMMs running in parallel.
Background
LHMMs are sometimes useful in specific structures because they can facilitate learning and generalization. For example, even though a fully connected HMM could always be used if enough training data were available, it is often useful to constrain the model by not allowing arbitrary state transitions. In the same way it can be beneficial to embed the HMM in a layered structure which, theoretically, may not be able to solve any problems the basic HMM cannot, but can solve some problems more efficiently because less training data is needed.The layered hidden Markov model
A layered hidden Markov model (LHMM) consists of levels of HMMs where the HMMs on level corresponds to observation symbols or probability generators at level .Every level
of the LHMM consists of HMMs running in parallel. in the LHMM a sequence of observation symbols can be used to classify the input into one of classes, where each class corresponds to each of the HMMs at level . This classification can then be used to generate a new observation for the level HMMs. At the lowest layer, i.e. level , primitive observation symbols would be generated directly from observations of the modeled process. For example in a trajectory tracking task the primitive observation symbols would originate from the quantized sensor values. Thus at each layer in the LHMM the observations originate from the classification of the underlying layer, except for the lowest layer where the observation symbols originate from measurements of the observed process.It is not necessary to run all levels at the same time granularity. For example it is possible to use windowing at any level in the structure so that the classification takes the average of several classifications into consideration before passing the results up the layers of the LHMM.
Instead of simply using the winning HMM at level
as an input symbol for the HMM at level it is possible to use it as a probability generator by passing the complete probability distributionProbability distribution
In probability theory, a probability mass, probability density, or probability distribution is a function that describes the probability of a random variable taking certain values....
up the layers of the LHMM. Thus instead of having a "winner takes all" strategy where the most probable HMM is selected as an observation symbol, the likelihood
of observing the th HMM can be used in the recursion formula of the level HMM to account for the uncertainty in the classification of the HMMs at level . Thus, if the classification of the HMMs at level is uncertain, it is possible to pay more attention to the a-priori information encoded in the HMM at level .A LHMM could in practice be transformed into a single layered HMM where all the different models are concatenated together. Some of the advantages that may be expected from using the LHMM over a large single layer HMM is that the LHMM is less likely to suffer from over-fitting since the individual sub-components are trained independently on smaller amounts of data. A consequence of this is that a significantly smaller amount of training data is required for the LHMM to achieve a performance comparable of the HMM. Another advantage is that the layers at the bottom of the LHMM, which are more sensitive to changes in the environment such as the type of sensors, sampling rate etc, can be retrained separately without altering the higher layers of the LHMM.