

LabelMe
Encyclopedia
LabelMe is a project created by the MIT Computer Science and Artificial Intelligence Laboratory
(CSAIL) which provides a dataset of digital images with annotations. The dataset is dynamic, free to use, and open to public contribution. The most applicable use of LabelMe is in computer vision
research. As of October 31, 2010, LabelMe has 187,240 images, 62,197 annotated images, and 658,992 labeled objects.
with javascript
support. When the tool is loaded, it chooses a random image from the LabelMe dataset and displays it on the screen. If the image already has object labels associated with it, they will be overlaid on top of the image in polygon format. Each distinct object label is displayed in a different color.
If the image is not completely labeled, the user can use the mouse
to draw a polygon containing an object in the image. For example, in the image to the right, if a person was standing in front of the building, the user could click on a point on the border of the person, and continue clicking along the outside edge until returning to the starting point. Once the polygon is closed, a bubble pops up on the screen which allows the user to enter a label for the object. The user can choose whatever label the user thinks best describes the object. If the user disagrees with the previous labeling of the image, the user can click on the outline polygon of an object and either delete the polygon completely or edit the text label to give it a new name.
As soon as changes are made to the image by the user, they are saved and openly available for anyone to download from the LabelMe dataset. In this way, the data is always changing due to contributions by the community of users who use the tool. Once the user is finished with an image, the Show me another image link can be clicked and another random image will be selected to display to the user.
The creators of LabelMe decided to leave these decisions up to the annotator. The reason for this is that they believe people will tend to annotate the images according to what they think is the natural labeling of the images. This also provides some variability in the data, which can help researchers tune their algorithms to account for this variability.
WordNet
is a database of words organized into a structural way. It allows assigning a word to a category, or in WordNet language: a sense. Sense assignment is not easy to do automatically. When the authors of LabelMe tried automatic sense assignment, they found that it was prone to a high rate of error, so instead they assigned words to senses manually. At first, this may seem like a daunting task since new labels are added to the LabelMe project continuously. To the right is a graph comparing the growth of polygons to the growth of words (descriptions). As you can see, the growth of words is small compared with the continuous growth of polygons, and therefore is easy enough to keep up to date manually by the LabelMe team.
Once WordNet assignment is done, searches in the LabelMe database are much more effective. For example, a search for animal might bring up pictures of dogs, cats and snakes. However, since the assignment was done manually, a picture of a computer mouse labeled as mouse would not show up in a search for animals. Also, if objects are labeled with more complex terms like dog walking, WordNet still allows the search of dog to return these objects as results. WordNet makes the LabelMe database much more useful.
This algorithm allows the automatic classification of parts of an object when the part objects are frequently contained within the outer object.
MIT Computer Science and Artificial Intelligence Laboratory
MIT Computer Science and Artificial Intelligence Laboratory is a research laboratory at the Massachusetts Institute of Technology formed by the 2003 merger of the Laboratory for Computer Science and Artificial Intelligence Laboratory...
(CSAIL) which provides a dataset of digital images with annotations. The dataset is dynamic, free to use, and open to public contribution. The most applicable use of LabelMe is in computer vision
Computer vision
Computer vision is a field that includes methods for acquiring, processing, analysing, and understanding images and, in general, high-dimensional data from the real world in order to produce numerical or symbolic information, e.g., in the forms of decisions...
research. As of October 31, 2010, LabelMe has 187,240 images, 62,197 annotated images, and 658,992 labeled objects.
Motivation
The motivation behind creating LabelMe comes from the history of publicly available data for computer vision researchers. Most available data was tailored to a specific research group's problems and caused new researchers to have to collect additional data to solve their own problems. LabelMe was created to solve several common shortcomings of available data. The following is a list of qualities that distinguish LabelMe from previous work.- Designed for recognition of a class of objects instead of single instances of an object. For example, a traditional dataset may have contained images of dogs, each of the same size and orientation. In contrast, LabelMe contains images of dogs in multiple angles, sizes, and orientations.
- Designed for recognizing objects embedded in arbitrary scenes instead of images that are cropped, normalizedNormalization (image processing)In image processing, normalization is a process that changes the range of pixel intensity values. Applications include photographs with poor contrast due to glare, for example. Normalization is sometimes called contrast stretching...
, and/or resized to display a single object. - Complex annotation: Instead of labeling an entire image (which also limits each image to containing a single object), LabelMe allows annotation of multiple objects within an image by specifying a polygonPolygonIn geometry a polygon is a flat shape consisting of straight lines that are joined to form a closed chain orcircuit.A polygon is traditionally a plane figure that is bounded by a closed path, composed of a finite sequence of straight line segments...
bounding box that contains the object. - Contains a large number of object classes and allows the creation of new classes easily.
- Diverse images: LabelMe contains images from many different scenes.
- Provides non-copyrightCopyrightCopyright is a legal concept, enacted by most governments, giving the creator of an original work exclusive rights to it, usually for a limited time...
ed images and allows public additions to the annotations. This creates a free environment.
Annotation Tool
The LabelMe annotation tool provides a means for users to contribute to the project. The tool can be accessed anonymously or by logging in to a free account. To access the tool, users must have a compatible web browserWeb browser
A web browser is a software application for retrieving, presenting, and traversing information resources on the World Wide Web. An information resource is identified by a Uniform Resource Identifier and may be a web page, image, video, or other piece of content...
with javascript
JavaScript
JavaScript is a prototype-based scripting language that is dynamic, weakly typed and has first-class functions. It is a multi-paradigm language, supporting object-oriented, imperative, and functional programming styles....
support. When the tool is loaded, it chooses a random image from the LabelMe dataset and displays it on the screen. If the image already has object labels associated with it, they will be overlaid on top of the image in polygon format. Each distinct object label is displayed in a different color.
If the image is not completely labeled, the user can use the mouse
Mouse (computing)
In computing, a mouse is a pointing device that functions by detecting two-dimensional motion relative to its supporting surface. Physically, a mouse consists of an object held under one of the user's hands, with one or more buttons...
to draw a polygon containing an object in the image. For example, in the image to the right, if a person was standing in front of the building, the user could click on a point on the border of the person, and continue clicking along the outside edge until returning to the starting point. Once the polygon is closed, a bubble pops up on the screen which allows the user to enter a label for the object. The user can choose whatever label the user thinks best describes the object. If the user disagrees with the previous labeling of the image, the user can click on the outline polygon of an object and either delete the polygon completely or edit the text label to give it a new name.
As soon as changes are made to the image by the user, they are saved and openly available for anyone to download from the LabelMe dataset. In this way, the data is always changing due to contributions by the community of users who use the tool. Once the user is finished with an image, the Show me another image link can be clicked and another random image will be selected to display to the user.
Problems with the data
The LabelMe dataset has some problems that should be noted. Some are inherent in the data, such as the objects in the images not being uniformly distributed with respect to size and image location. This is due to the images being primarily taken by humans who tend to focus the camera on interesting objects in a scene. However, cropping and rescaling the images randomly can simulate a uniform distribution.. Other problems are caused by the amount of freedom given to the users of the annotation tool. Some problems that arise are:- The user can choose which objects in the scene to outline. Should an occludedHidden surface determinationIn 3D computer graphics, hidden surface determination is the process used to determine which surfaces and parts of surfaces are not visible from a certain viewpoint...
person be labeled? Should the sky be labeled? - The user has to describe the shape of the object themselves by outlining a polygon. Should the fingers of a hand on a person be outlined with detail? How much precision must be used when outlining objects?
- The user chooses what text to enter as the label for the object. Should the label be person, man, or pedestrian?
The creators of LabelMe decided to leave these decisions up to the annotator. The reason for this is that they believe people will tend to annotate the images according to what they think is the natural labeling of the images. This also provides some variability in the data, which can help researchers tune their algorithms to account for this variability.
Using WordNet
Since the text labels for objects provided in LabelMe come from user input, there is a lot of variation in the labels used (as described above). Because of this, analysis of objects can be difficult. For example, a picture of a dog might be labeled as dog, canine, hound, pooch, or animal. Ideally, when using the data, the object class dog at the abstract level should incorporate all of these text labels.WordNet
WordNet
WordNet is a lexical database for the English language. It groups English words into sets of synonyms called synsets, provides short, general definitions, and records the various semantic relations between these synonym sets...
is a database of words organized into a structural way. It allows assigning a word to a category, or in WordNet language: a sense. Sense assignment is not easy to do automatically. When the authors of LabelMe tried automatic sense assignment, they found that it was prone to a high rate of error, so instead they assigned words to senses manually. At first, this may seem like a daunting task since new labels are added to the LabelMe project continuously. To the right is a graph comparing the growth of polygons to the growth of words (descriptions). As you can see, the growth of words is small compared with the continuous growth of polygons, and therefore is easy enough to keep up to date manually by the LabelMe team.
Once WordNet assignment is done, searches in the LabelMe database are much more effective. For example, a search for animal might bring up pictures of dogs, cats and snakes. However, since the assignment was done manually, a picture of a computer mouse labeled as mouse would not show up in a search for animals. Also, if objects are labeled with more complex terms like dog walking, WordNet still allows the search of dog to return these objects as results. WordNet makes the LabelMe database much more useful.
Object-part hierarchy
Having a large dataset of objects where overlap is allowed provides enough data to try and categorize objects as being a part of another object. For example, most of the labels assigned wheel are probably part of objects assigned to other labels like car or bicycle. These are called part labels. To determine if label P is a part label for label O:- Let
 denote the set of images containing an object (e.g. car)
denote the set of images containing an object (e.g. car) - Let
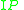 denote the set of images containing a part (e.g. wheel)
denote the set of images containing a part (e.g. wheel) - Let the overlap score between object O and part P,
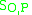 , be defined as the ratio of the intersection area to the area of the part polygon. (e.g.
, be defined as the ratio of the intersection area to the area of the part polygon. (e.g.  )
) - Let
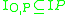 denote the images where object and part polygons have
denote the images where object and part polygons have 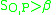 where
where 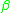 is some threshold value. The authors of LabelMe use
is some threshold value. The authors of LabelMe use 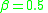
- The object-part score for a candidate label is
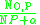 where
where 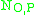 and
and 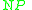 are the number of images in
are the number of images in 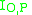 and
and 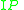 , respectively, and
, respectively, and 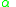 is a concentration parameter. The authors of LabelMe use
is a concentration parameter. The authors of LabelMe use 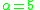 .
.
This algorithm allows the automatic classification of parts of an object when the part objects are frequently contained within the outer object.
Object depth ordering
Another instance of object overlap is when one object is actually on top of the other. For example, an image might contain a person standing in front of a building. The person is not a part label as above since the person is not part of the building. Instead, they are two separate objects that happen to overlap. To automatically determine which object is the foreground and which is the background, the authors of LabelMe propose several options:- If an object is completely contained within another object, then the inner object must be in the foreground. Otherwise, it would not be visible in the image. The only exception is with transparent or translucent objects, but these occur rarely.
- One of the objects could be labeled as something that cannot be in the foreground. Examples are sky, ground, or road.
- The object with more polygon points inside the intersecting area is most likely the foreground. The authors tested this hypothesis and found it to be highly accurate.
- Histogram intersection can be used. To do this, a color histogramColor histogramIn image processing and photography, a color histogram is a representation of the distribution of colors in an image. For digital images, a color histogram represents the number of pixels that have colors in each of a fixed list of color ranges, that span the image's color space, the set of all...
in the intersecting areas is compared to the color histogram of the two objects. The object with the closer color histogram is assigned as the foreground. This method is less accurate than counting the polygon points.
Matlab Toolbox
The LabelMe project provides a set of tools for using the LabelMe dataset from Matlab. Since research is often done in Matlab, this allows the integration of the dataset with existing tools in computer vision. The entire dataset can be downloaded and used offline, or the toolbox allows dynamic downloading of content on demand.External links
- http://labelme.csail.mit.edu/ - LabelMe - The open annotation tool
- http://people.csail.mit.edu/torralba/research/LabelMe/js/LabelMeQueryObjectFast.cgi - Search LabelMe objects
- http://labelme.csail.mit.edu/tool.html - Contribute to the LabelMe project
- http://labelme.csail.mit.edu/LabelMeToolbox/index.html - LabelMe Matlab Toolbox