

Expected value of sample information
Encyclopedia
In decision theory
, the expected value of sample information (EVSI) is the expected increase in utility that you could obtain from gaining access to a sample
of additional observations before making a decision. The additional information obtained from the sample
may allow you to make a more informed, and thus better, decision, thus resulting in an increase in expected utility. EVSI attempts to estimate what this improvement would be before seeing actual sample data; hence, EVSI is a form of what is known as preposterior analysis.

It is common (but not essential) in EVSI scenarios for ,
, 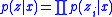 and
and 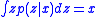 , which is to say that each observation is an unbiased sensor reading of the underlying state
, which is to say that each observation is an unbiased sensor reading of the underlying state  , with each sensor reading being independent and identically distributed.
, with each sensor reading being independent and identically distributed.
The utility from the optimal decision based only on your prior, without making any further observations, is given by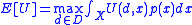
If you could gain access to a single sample, , the optimal posterior utility would be:
, the optimal posterior utility would be: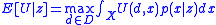
where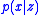 is obtained from Bayes' rule
is obtained from Bayes' rule
: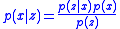
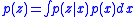
Since you don't know what sample would actually be obtained if you were to obtain a sample, you must average over all possible samples to obtain the expected utility given a sample: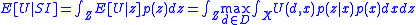
The expected value of sample information is then defined as: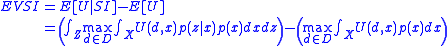
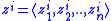 , then using it to compute the posterior
, then using it to compute the posterior 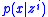 and maximizing utility based on
and maximizing utility based on 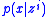 . This whole process is then repeated many times, for
. This whole process is then repeated many times, for 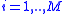 to obtain a Monte Carlo sample
to obtain a Monte Carlo sample
if optimal utilities. These are averaged to obtain the expected utility given a hypothetical sample.
 subjects. This question is answered by the EVSI.
subjects. This question is answered by the EVSI.
The diagram shows an influence diagram
depiction of an Analytica model for computing the EVSI in this example. For the reader who wishes to study this computation in greater detail, the model can be viewed and evaluated from Analytica Web Player.
The model classifies the outcome for any given subject into one of five categories: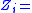 {"Cure", "Improvement", "Ineffective", "Mild side-effect", "Serious side-effect"}
{"Cure", "Improvement", "Ineffective", "Mild side-effect", "Serious side-effect"}
And for each of these outcomes, assigns a utility equal to an estimated patient-equivalent monetary value of the outcome.
A decision state, in this example is a vector of five numbers between 0 and 1 that sum to 1, giving the proportion of future patients that will experience each of the five possible outcomes. For example, a state
in this example is a vector of five numbers between 0 and 1 that sum to 1, giving the proportion of future patients that will experience each of the five possible outcomes. For example, a state 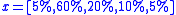 denotes the case where 5% of patients are cured, 60% improve, 20% find the treatment ineffective, 10% experience mild side-effects and 5% experience dangerous side-effects.
denotes the case where 5% of patients are cured, 60% improve, 20% find the treatment ineffective, 10% experience mild side-effects and 5% experience dangerous side-effects.
The prior,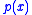 is encoded using a Dirichlet distribution, requiring five numbers (that don't sum to 1) whose relative values capture the expected relative proportion of each outcome, and whose sum encodes the strength of this prior belief. In the diagram, the parameters of the Dirichlet distribution are contained in the variable dirichlet alpha prior, while the prior distribution itself is in the chance variable Prior. The probability density graph
is encoded using a Dirichlet distribution, requiring five numbers (that don't sum to 1) whose relative values capture the expected relative proportion of each outcome, and whose sum encodes the strength of this prior belief. In the diagram, the parameters of the Dirichlet distribution are contained in the variable dirichlet alpha prior, while the prior distribution itself is in the chance variable Prior. The probability density graph
of the marginals
is shown here:
In the chance variable Trial data, trial data is simulated as a Monte Carlo sample from a Multinomial distribution. For example, when Trial_size=100, each Monte Carlo sample of Trial_data contains a vector that sums to 100 showing the number of subjects in the simulated study that experienced each of the five possible outcomes. The following result table depicts the first 8 simulated trial outcomes:
Combining this trial data with a Dirichlet prior requires only adding the outcome frequencies to the Dirichlet prior alpha values, resulting in a Diriclet posterior distribution for each simulated trial. For each of these, the decision to approve is made based on whether the mean utility is positive, and using a utility of zero when the treatment is not approved, the Pre-posterior utility is obtained. Repeating the computation for a range of possible trial sizes, an EVSI is obtained at each possible candidate trial size as depicted in this graph:
More historical background is needed here.
(EVPI) metric, which encodes the increase of utility that would be obtained if one were to learn the true underlying state, . Essentially EVPI indicates the value of perfect information, while EVSI indicates the value of some limited and incomplete information.
. Essentially EVPI indicates the value of perfect information, while EVSI indicates the value of some limited and incomplete information.
The Expected value of including uncertainty
(EVIU) compares the value of modeling uncertain information as compared to modeling a situation without taking uncertainty into account. Since the impact of uncertainty on computed results is often analysed using Monte Carlo methods, EVIU appears to be very similar to the value of carrying out an analysis using a Monte Carlo sample, which closely resembles in statement the notion captured with EVSI. However, EVSI and EVIU are quite distinct—a notable difference between the manner in which EVSI uses Bayesian updating
to incorporate the simulated sample.
Decision theory
Decision theory in economics, psychology, philosophy, mathematics, and statistics is concerned with identifying the values, uncertainties and other issues relevant in a given decision, its rationality, and the resulting optimal decision...
, the expected value of sample information (EVSI) is the expected increase in utility that you could obtain from gaining access to a sample
Sample (statistics)
In statistics, a sample is a subset of a population. Typically, the population is very large, making a census or a complete enumeration of all the values in the population impractical or impossible. The sample represents a subset of manageable size...
of additional observations before making a decision. The additional information obtained from the sample
Sample (statistics)
In statistics, a sample is a subset of a population. Typically, the population is very large, making a census or a complete enumeration of all the values in the population impractical or impossible. The sample represents a subset of manageable size...
may allow you to make a more informed, and thus better, decision, thus resulting in an increase in expected utility. EVSI attempts to estimate what this improvement would be before seeing actual sample data; hence, EVSI is a form of what is known as preposterior analysis.
Formulation
LetIt is common (but not essential) in EVSI scenarios for
, and , which is to say that each observation is an unbiased sensor reading of the underlying state , with each sensor reading being independent and identically distributed.The utility from the optimal decision based only on your prior, without making any further observations, is given by
If you could gain access to a single sample,
, the optimal posterior utility would be:where
is obtained from Bayes' ruleBayes' theorem
In probability theory and applications, Bayes' theorem relates the conditional probabilities P and P. It is commonly used in science and engineering. The theorem is named for Thomas Bayes ....
:
Since you don't know what sample would actually be obtained if you were to obtain a sample, you must average over all possible samples to obtain the expected utility given a sample:
The expected value of sample information is then defined as:
Computation
It is seldom feasible to carry out the integration over the space of possible observations in E[U|SI] analytically, so the computation of EVSI usually requires a Monte Carlo simulation. The method involves randomly simulating a sample,, then using it to compute the posterior and maximizing utility based on . This whole process is then repeated many times, for to obtain a Monte Carlo sampleMonte Carlo method
Monte Carlo methods are a class of computational algorithms that rely on repeated random sampling to compute their results. Monte Carlo methods are often used in computer simulations of physical and mathematical systems...
if optimal utilities. These are averaged to obtain the expected utility given a hypothetical sample.
Example
A regulatory agency is to decide whether to approve a new treatment. Before making the final approve/reject decision, they ask what the value would be of conducting a further trial study on subjects. This question is answered by the EVSI.The diagram shows an influence diagram
Influence diagram
An influence diagram is a compact graphical and mathematical representation of a decision situation...
depiction of an Analytica model for computing the EVSI in this example. For the reader who wishes to study this computation in greater detail, the model can be viewed and evaluated from Analytica Web Player.
The model classifies the outcome for any given subject into one of five categories:
{"Cure", "Improvement", "Ineffective", "Mild side-effect", "Serious side-effect"}And for each of these outcomes, assigns a utility equal to an estimated patient-equivalent monetary value of the outcome.
A decision state,
in this example is a vector of five numbers between 0 and 1 that sum to 1, giving the proportion of future patients that will experience each of the five possible outcomes. For example, a state denotes the case where 5% of patients are cured, 60% improve, 20% find the treatment ineffective, 10% experience mild side-effects and 5% experience dangerous side-effects.The prior,
is encoded using a Dirichlet distribution, requiring five numbers (that don't sum to 1) whose relative values capture the expected relative proportion of each outcome, and whose sum encodes the strength of this prior belief. In the diagram, the parameters of the Dirichlet distribution are contained in the variable dirichlet alpha prior, while the prior distribution itself is in the chance variable Prior. The probability density graphProbability density function
In probability theory, a probability density function , or density of a continuous random variable is a function that describes the relative likelihood for this random variable to occur at a given point. The probability for the random variable to fall within a particular region is given by the...
of the marginals
Marginal distribution
In probability theory and statistics, the marginal distribution of a subset of a collection of random variables is the probability distribution of the variables contained in the subset. The term marginal variable is used to refer to those variables in the subset of variables being retained...
is shown here:
In the chance variable Trial data, trial data is simulated as a Monte Carlo sample from a Multinomial distribution. For example, when Trial_size=100, each Monte Carlo sample of Trial_data contains a vector that sums to 100 showing the number of subjects in the simulated study that experienced each of the five possible outcomes. The following result table depicts the first 8 simulated trial outcomes:
Combining this trial data with a Dirichlet prior requires only adding the outcome frequencies to the Dirichlet prior alpha values, resulting in a Diriclet posterior distribution for each simulated trial. For each of these, the decision to approve is made based on whether the mean utility is positive, and using a utility of zero when the treatment is not approved, the Pre-posterior utility is obtained. Repeating the computation for a range of possible trial sizes, an EVSI is obtained at each possible candidate trial size as depicted in this graph:
Historical background
The 1961 book Applied Statistical Decision Theory by Schlaifer and Raiffa was among the earliest to utilize EVSI extensively.More historical background is needed here.
Comparison to related measures
Expected value of sample information (EVSI) is a relaxation of the Expected value of perfect informationExpected value of perfect information
In decision theory, the expected value of perfect information is the price that one would be willing to pay in order to gain access to perfect information....
(EVPI) metric, which encodes the increase of utility that would be obtained if one were to learn the true underlying state,
. Essentially EVPI indicates the value of perfect information, while EVSI indicates the value of some limited and incomplete information.The Expected value of including uncertainty
Expected value of including uncertainty
In decision theory and quantitative policy analysis, the expected value of including information is the expected difference in the value of a decision based on a probabilistic analysis versus a decision based on an analysis that ignores uncertainty....
(EVIU) compares the value of modeling uncertain information as compared to modeling a situation without taking uncertainty into account. Since the impact of uncertainty on computed results is often analysed using Monte Carlo methods, EVIU appears to be very similar to the value of carrying out an analysis using a Monte Carlo sample, which closely resembles in statement the notion captured with EVSI. However, EVSI and EVIU are quite distinct—a notable difference between the manner in which EVSI uses Bayesian updating
Bayes' theorem
In probability theory and applications, Bayes' theorem relates the conditional probabilities P and P. It is commonly used in science and engineering. The theorem is named for Thomas Bayes ....
to incorporate the simulated sample.
See also
- Expected value of perfect informationExpected value of perfect informationIn decision theory, the expected value of perfect information is the price that one would be willing to pay in order to gain access to perfect information....
(EVPI) - Expected value of including uncertaintyExpected value of including uncertaintyIn decision theory and quantitative policy analysis, the expected value of including information is the expected difference in the value of a decision based on a probabilistic analysis versus a decision based on an analysis that ignores uncertainty....
(EVIU)