

Cache-oblivious model
Encyclopedia
In computing
, a cache-oblivious algorithm (or cache-transcendent algorithm) is an algorithm
designed to take advantage of a CPU cache
without having the size of the cache (or the length of the cache lines, etcetera) as an explicit parameter. An optimal cache-oblivious algorithm is a cache-oblivious algorithm that uses the cache optimally (in an asymptotic sense, ignoring constant factors). Thus, a cache oblivious algorithm is designed to perform well, without modification, on multiple machines with different cache sizes, or for a memory hierarchy
with different levels of cache having different sizes. The idea (and name) for cache-oblivious algorithms was conceived by Charles E. Leiserson
as early as 1996 and first published by Harald Prokop
in his master's thesis at the Massachusetts Institute of Technology
in 1999.
Optimal cache-oblivious algorithms are known for the Cooley–Tukey FFT algorithm, matrix multiplication
, sorting
, matrix transposition, and several other problems. Because these algorithms are only optimal in an asymptotic sense (ignoring constant factors), further machine-specific tuning may be required to obtain nearly optimal performance in an absolute sense. The goal of cache-oblivious algorithms is to reduce the amount of such tuning that is required.
Typically, a cache-oblivious algorithm works by a recursive
divide and conquer algorithm
, where the problem is divided into smaller and smaller subproblems. Eventually, one reaches a subproblem size that fits into cache, regardless of the cache size. For example, an optimal cache-oblivious matrix multiplication is obtained by recursively dividing each matrix into four sub-matrices to be multiplied, multiplying the submatrices in a depth-first fashion.
In particular, the cache-oblivious model is an abstract machine
(i.e. a theoretical model of computation). It is similar to the RAM machine model which replaces the Turing machine
's infinite tape with an infinite array. Each location within the array can be accessed in time, similar to the Random access memory on a real computer. Unlike the RAM machine model, it also introduces a cache: a second level of storage between the RAM and the CPU. The other differences between the two models are listed below. In the cache-oblivious model:
time, similar to the Random access memory on a real computer. Unlike the RAM machine model, it also introduces a cache: a second level of storage between the RAM and the CPU. The other differences between the two models are listed below. In the cache-oblivious model:
To measure the complexity of an algorithm that executes within the cache-oblivious model, we can measure the familiar (running time) work complexity . However, we can also measure the cache complexity,
. However, we can also measure the cache complexity,  , the number of cache misses that the algorithm will experience.
, the number of cache misses that the algorithm will experience.
The goal for creating a good cache-oblivious algorithm is to match the work complexity of some optimal RAM model algorithm while minimizing . Furthermore, unlike the external-memory model, which shares many of the listed features, we would like our algorithm to be independent of cache parameters (
. Furthermore, unlike the external-memory model, which shares many of the listed features, we would like our algorithm to be independent of cache parameters ( and
and  ). The benefit of such an algorithm is that what is efficient on a cache-oblivious machine is likely to be efficient across many real machines without fine tuning for particular real machine parameters. Frigo et al. showed that for many problems, an optimal cache-oblivious algorithm will also be optimal for a machine with more than two memory hierarchy
). The benefit of such an algorithm is that what is efficient on a cache-oblivious machine is likely to be efficient across many real machines without fine tuning for particular real machine parameters. Frigo et al. showed that for many problems, an optimal cache-oblivious algorithm will also be optimal for a machine with more than two memory hierarchy
levels.
s which is cache-oblivious and allows list traversal of elements in
elements in  time, where
time, where  is the cache size in elements. For a fixed
is the cache size in elements. For a fixed  , this is
, this is  time. However, the advantage of the algorithm is that it can scale to take advantage of larger cache line sizes (larger values of
time. However, the advantage of the algorithm is that it can scale to take advantage of larger cache line sizes (larger values of  ).
).
The simplest cache-oblivious algorithm presented in Frigo et al. is an out-of-place matrix transpose operation (in-place algorithms
have also been devised for transposition, but are much more complicated for non-square matrices). Given m×n array A and n×m array B, we would like to store the transpose of in
in  . The naive solution traverses one array in row-major order and another in column-major. The result is that when the matrices are large, we get a cache miss on every step of the column-wise traversal. The total number of cache misses is
. The naive solution traverses one array in row-major order and another in column-major. The result is that when the matrices are large, we get a cache miss on every step of the column-wise traversal. The total number of cache misses is  .
.
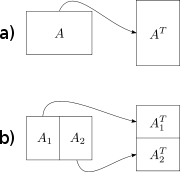 The cache-oblivious algorithm has optimal work complexity
The cache-oblivious algorithm has optimal work complexity  and optimal cache complexity
and optimal cache complexity  . The basic idea is to reduce the transpose of two large matrices into the transpose of small (sub)matrices. We do this by dividing the matrices in half along their larger dimension until we just have to perform the transpose of a matrix that will fit into the cache. Because the cache size is not known to the algorithm, the matrices will continue to be divided recursively even after this point, but these further subdivisions will be in cache. Once the dimensions
. The basic idea is to reduce the transpose of two large matrices into the transpose of small (sub)matrices. We do this by dividing the matrices in half along their larger dimension until we just have to perform the transpose of a matrix that will fit into the cache. Because the cache size is not known to the algorithm, the matrices will continue to be divided recursively even after this point, but these further subdivisions will be in cache. Once the dimensions  and
and  are small enough so an input array of size
are small enough so an input array of size  and an output array of size
and an output array of size  fit into the cache, both row-major and column-major traversals result in
fit into the cache, both row-major and column-major traversals result in  work and
work and  cache misses. By using this divide and conquer approach we can achieve the same level of complexity for the overall matrix.
cache misses. By using this divide and conquer approach we can achieve the same level of complexity for the overall matrix.
(In principle, one could continue dividing the matrices until a base case of size 1×1 is reached, but in practice one uses a larger base case (e.g. 16×16) in order to amortize
the overhead of the recursive subroutine calls.)
Most cache-oblivious algorithms rely on a divide-and-conquer approach. They reduce the problem, so that it eventually fits in cache no matter how small the cache is, and end the recursion at some small size determined by the function-call overhead and similar cache-unrelated optimizations, and then use some cache-efficient access pattern to merge the results of these small, solved problems.
Computing
Computing is usually defined as the activity of using and improving computer hardware and software. It is the computer-specific part of information technology...
, a cache-oblivious algorithm (or cache-transcendent algorithm) is an algorithm
Algorithm
In mathematics and computer science, an algorithm is an effective method expressed as a finite list of well-defined instructions for calculating a function. Algorithms are used for calculation, data processing, and automated reasoning...
designed to take advantage of a CPU cache
CPU cache
A CPU cache is a cache used by the central processing unit of a computer to reduce the average time to access memory. The cache is a smaller, faster memory which stores copies of the data from the most frequently used main memory locations...
without having the size of the cache (or the length of the cache lines, etcetera) as an explicit parameter. An optimal cache-oblivious algorithm is a cache-oblivious algorithm that uses the cache optimally (in an asymptotic sense, ignoring constant factors). Thus, a cache oblivious algorithm is designed to perform well, without modification, on multiple machines with different cache sizes, or for a memory hierarchy
Memory hierarchy
The term memory hierarchy is used in the theory of computation when discussing performance issues in computer architectural design, algorithm predictions, and the lower level programming constructs such as involving locality of reference. A 'memory hierarchy' in computer storage distinguishes each...
with different levels of cache having different sizes. The idea (and name) for cache-oblivious algorithms was conceived by Charles E. Leiserson
Charles E. Leiserson
Charles Eric Leiserson is a computer scientist, specializing in the theory of parallel computing and distributed computing, and particularly practical applications thereof; as part of this effort, he developed the Cilk multithreaded language...
as early as 1996 and first published by Harald Prokop
Harald Prokop
Harald Prokop is the Senior Vice President of Engineering at Akamai Technologies, and is also known for having elucidated the concept of the cache-oblivious algorithm....
in his master's thesis at the Massachusetts Institute of Technology
Massachusetts Institute of Technology
The Massachusetts Institute of Technology is a private research university located in Cambridge, Massachusetts. MIT has five schools and one college, containing a total of 32 academic departments, with a strong emphasis on scientific and technological education and research.Founded in 1861 in...
in 1999.
Optimal cache-oblivious algorithms are known for the Cooley–Tukey FFT algorithm, matrix multiplication
Matrix multiplication
In mathematics, matrix multiplication is a binary operation that takes a pair of matrices, and produces another matrix. If A is an n-by-m matrix and B is an m-by-p matrix, the result AB of their multiplication is an n-by-p matrix defined only if the number of columns m of the left matrix A is the...
, sorting
Sorting
Sorting is any process of arranging items in some sequence and/or in different sets, and accordingly, it has two common, yet distinct meanings:# ordering: arranging items of the same kind, class, nature, etc...
, matrix transposition, and several other problems. Because these algorithms are only optimal in an asymptotic sense (ignoring constant factors), further machine-specific tuning may be required to obtain nearly optimal performance in an absolute sense. The goal of cache-oblivious algorithms is to reduce the amount of such tuning that is required.
Typically, a cache-oblivious algorithm works by a recursive
Recursion
Recursion is the process of repeating items in a self-similar way. For instance, when the surfaces of two mirrors are exactly parallel with each other the nested images that occur are a form of infinite recursion. The term has a variety of meanings specific to a variety of disciplines ranging from...
divide and conquer algorithm
Divide and conquer algorithm
In computer science, divide and conquer is an important algorithm design paradigm based on multi-branched recursion. A divide and conquer algorithm works by recursively breaking down a problem into two or more sub-problems of the same type, until these become simple enough to be solved directly...
, where the problem is divided into smaller and smaller subproblems. Eventually, one reaches a subproblem size that fits into cache, regardless of the cache size. For example, an optimal cache-oblivious matrix multiplication is obtained by recursively dividing each matrix into four sub-matrices to be multiplied, multiplying the submatrices in a depth-first fashion.
Idealized cache model
Cache-oblivious algorithms are typically analyzed using an idealized model of the cache, sometimes called the cache-oblivious model. This model is much easier to analyze than a real cache's characteristics (which have complicated associativity, replacement policies, etcetera), but in many cases is provably within a constant factor of a more realistic cache's performance.In particular, the cache-oblivious model is an abstract machine
Abstract machine
An abstract machine, also called an abstract computer, is a theoretical model of a computer hardware or software system used in automata theory...
(i.e. a theoretical model of computation). It is similar to the RAM machine model which replaces the Turing machine
Turing machine
A Turing machine is a theoretical device that manipulates symbols on a strip of tape according to a table of rules. Despite its simplicity, a Turing machine can be adapted to simulate the logic of any computer algorithm, and is particularly useful in explaining the functions of a CPU inside a...
's infinite tape with an infinite array. Each location within the array can be accessed in
time, similar to the Random access memory on a real computer. Unlike the RAM machine model, it also introduces a cache: a second level of storage between the RAM and the CPU. The other differences between the two models are listed below. In the cache-oblivious model:- Memory is broken into lines of
 words each
words each - A load or a store between main memory and a CPU register may now be serviced from the cache.
- If a load or a store cannot be serviced from the cache, it is called a cache miss.
- A cache miss results in one line being loaded from main memory into the cache. Namely, if the CPU tries to access word
 and
and  is the line containing
is the line containing  , then
, then  is loaded into the cache. If the cache was previously full, then a line will be evicted as well (see replacement policy below).
is loaded into the cache. If the cache was previously full, then a line will be evicted as well (see replacement policy below). - The cache holds
 words, where
words, where  . This is also known as the tall cache assumption.
. This is also known as the tall cache assumption. - The cache is fully associative: each line can be loaded into any location in the cache.
- The replacement policy is optimal. In other words, the cache is assumed to be given the entire sequence of memory accesses during algorithm execution. If it needs to evict a line at time
 , it will look into its sequence of future requests and evict the line that is accessed furthest in the future. This can be emulated in practice with the Least Recently Used policy, which is shown to be within a small constant factor of the offline optimal replacement strategy (Frigo et al., 1999, Sleator and Tarjan, 1985).
, it will look into its sequence of future requests and evict the line that is accessed furthest in the future. This can be emulated in practice with the Least Recently Used policy, which is shown to be within a small constant factor of the offline optimal replacement strategy (Frigo et al., 1999, Sleator and Tarjan, 1985).
To measure the complexity of an algorithm that executes within the cache-oblivious model, we can measure the familiar (running time) work complexity
. However, we can also measure the cache complexity, , the number of cache misses that the algorithm will experience.The goal for creating a good cache-oblivious algorithm is to match the work complexity of some optimal RAM model algorithm while minimizing
. Furthermore, unlike the external-memory model, which shares many of the listed features, we would like our algorithm to be independent of cache parameters ( and ). The benefit of such an algorithm is that what is efficient on a cache-oblivious machine is likely to be efficient across many real machines without fine tuning for particular real machine parameters. Frigo et al. showed that for many problems, an optimal cache-oblivious algorithm will also be optimal for a machine with more than two memory hierarchyMemory hierarchy
The term memory hierarchy is used in the theory of computation when discussing performance issues in computer architectural design, algorithm predictions, and the lower level programming constructs such as involving locality of reference. A 'memory hierarchy' in computer storage distinguishes each...
levels.
Examples
For example, it is possible to design a variant of unrolled linked listUnrolled linked list
In computer programming, an unrolled linked list is a variation on the linked list which stores multiple elements in each node. It can drastically increase cache performance, while decreasing the memory overhead associated with storing list metadata such as references...
s which is cache-oblivious and allows list traversal of
elements in time, where is the cache size in elements. For a fixed , this is time. However, the advantage of the algorithm is that it can scale to take advantage of larger cache line sizes (larger values of ).The simplest cache-oblivious algorithm presented in Frigo et al. is an out-of-place matrix transpose operation (in-place algorithms
In-place matrix transposition
In-place matrix transposition, also called in-situ matrix transposition, is the problem of transposing an N×M matrix in-place in computer memory, ideally with O additional storage, or at most with additional storage much less than NM...
have also been devised for transposition, but are much more complicated for non-square matrices). Given m×n array A and n×m array B, we would like to store the transpose of
in . The naive solution traverses one array in row-major order and another in column-major. The result is that when the matrices are large, we get a cache miss on every step of the column-wise traversal. The total number of cache misses is . and optimal cache complexity . The basic idea is to reduce the transpose of two large matrices into the transpose of small (sub)matrices. We do this by dividing the matrices in half along their larger dimension until we just have to perform the transpose of a matrix that will fit into the cache. Because the cache size is not known to the algorithm, the matrices will continue to be divided recursively even after this point, but these further subdivisions will be in cache. Once the dimensions and are small enough so an input array of size and an output array of size fit into the cache, both row-major and column-major traversals result in work and cache misses. By using this divide and conquer approach we can achieve the same level of complexity for the overall matrix.(In principle, one could continue dividing the matrices until a base case of size 1×1 is reached, but in practice one uses a larger base case (e.g. 16×16) in order to amortize
Amortized analysis
In computer science, amortized analysis is a method of analyzing algorithms that considers the entire sequence of operations of the program. It allows for the establishment of a worst-case bound for the performance of an algorithm irrespective of the inputs by looking at all of the operations...
the overhead of the recursive subroutine calls.)
Most cache-oblivious algorithms rely on a divide-and-conquer approach. They reduce the problem, so that it eventually fits in cache no matter how small the cache is, and end the recursion at some small size determined by the function-call overhead and similar cache-unrelated optimizations, and then use some cache-efficient access pattern to merge the results of these small, solved problems.