

BIRCH (data clustering)
Encyclopedia
BIRCH is an unsupervised data mining
algorithm used to perform hierarchical clustering
over particularly large data-sets. An advantage of Birch is its ability to incrementally and dynamically cluster incoming, multi-dimensional metric data point
s in an attempt to produce the best quality clustering for a given set of resources (memory and time constraint
s). In most cases, Birch only requires a single scan of the database. In addition, Birch is recognized as the, "first clustering algorithm proposed in the database area to handle 'noise' (data points that are not part of the underlying pattern) effectively".
It exploits the observation that data space is not usually uniformly occupied and not every data point is equally important.
It makes full use of available memory to derive the finest possible sub-clusters while minimizing I/O costs.
It is also an incremental method that does not require the whole data set
in advance.
Clustering Feature : Given N d-dimensional data points in a cluster,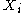 ,
, 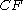 vector of the cluster is defined as a triple
vector of the cluster is defined as a triple 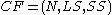 , where
, where 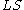 is the linear sum and
is the linear sum and 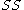 is the square sum of data points.
is the square sum of data points.
CF tree : A CF tree is a height balanced tree
with two parameters: branching factor
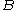 and threshold
and threshold 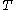 . Each non-leaf node contains at most
. Each non-leaf node contains at most 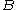 entries of the form
entries of the form  , where
, where 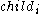 is a pointer to its
is a pointer to its  th child node
th child node
and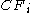 is the subcluster represented by this child. A leaf node contains at most
is the subcluster represented by this child. A leaf node contains at most 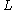 entries each of the form
entries each of the form 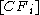 . It also has to two pointers prev and next which are used to chain all leaf nodes together. The tree size is a function of T. The larger the T is, the smaller the tree is. We also require a node to fit in a page of size of p. B and L are determined by P. So P can be varied for performance tuning
. It also has to two pointers prev and next which are used to chain all leaf nodes together. The tree size is a function of T. The larger the T is, the smaller the tree is. We also require a node to fit in a page of size of p. B and L are determined by P. So P can be varied for performance tuning
. It is a very compact representation of the dataset because each entry in a leaf node is not a single data point but a subcluster.
In the algorithm in the first step it scans all data and builds an initial memory CF tree using the given amount of memory. In the second step it scans all the leaf entries in the initial CF tree to rebuild a smaller CF tree, while removing outliers and grouping crowded subclusters into larger ones. In step three we use an existing clustering algorithm to cluster all leaf entries. Here an agglomerative hierarchial clustering algorithm is applied directly to the subclusters represented by their CF vectors. It also provides the flexibiltiy of allowing the user to specify either the desired number of clusters or the desired diameter threshold for clusters. After this step we obtain a set of clusters that captures major distribution pattern in the data. However there might exist minor and localized inaccuracies which can be handled by an optional step 4. In step 4 we use the centroids of the clusters produced in step as seeds and redistribute the data points to its closest sees to obtain a new set of clusters. Step 4 also provides us with an option of discarding outliers. That is a point which is too far from its closest seed can be treated as an outlier.
Data mining
Data mining , a relatively young and interdisciplinary field of computer science is the process of discovering new patterns from large data sets involving methods at the intersection of artificial intelligence, machine learning, statistics and database systems...
algorithm used to perform hierarchical clustering
Data clustering
Cluster analysis or clustering is the task of assigning a set of objects into groups so that the objects in the same cluster are more similar to each other than to those in other clusters....
over particularly large data-sets. An advantage of Birch is its ability to incrementally and dynamically cluster incoming, multi-dimensional metric data point
Data point
In statistics, a data point is a set of measurements on a single member of a statistical population, or a subset of those measurements for a given individual...
s in an attempt to produce the best quality clustering for a given set of resources (memory and time constraint
Time constraint
In law, time constraints are placed on certain actions and filings in the interest of speedy justice, and additionally to prevent the evasion of the ends of justice by waiting until a matter is moot...
s). In most cases, Birch only requires a single scan of the database. In addition, Birch is recognized as the, "first clustering algorithm proposed in the database area to handle 'noise' (data points that are not part of the underlying pattern) effectively".
Problem with previous methods
Previous clustering algorithms performed less effectively over very large databases and did not adequately consider the case wherein a data-set was too large to fit in main memory. As a result, there was a lot of overhead maintaining high clustering quality while minimizing the cost of addition IO (input/output) operations. Furthermore, most of Birch's predecessors inspect all data points (or all currently existing clusters) equally for each 'clustering decision' and do not perform heuristic weighting based on the distance between these data points.Advantages with BIRCH
It is local in that each clustering decision is made without scanning all data points and currently existing clusters.It exploits the observation that data space is not usually uniformly occupied and not every data point is equally important.
It makes full use of available memory to derive the finest possible sub-clusters while minimizing I/O costs.
It is also an incremental method that does not require the whole data set
Data set
A data set is a collection of data, usually presented in tabular form. Each column represents a particular variable. Each row corresponds to a given member of the data set in question. Its values for each of the variables, such as height and weight of an object or values of random numbers. Each...
in advance.
BIRCH Clustering Algorithm
For this first we define the following concepts::Clustering Feature : Given N d-dimensional data points in a cluster,
, vector of the cluster is defined as a triple , where is the linear sum and is the square sum of data points.CF tree : A CF tree is a height balanced tree
Self-balancing binary search tree
In computer science, a self-balancing binary search tree is any node based binary search tree that automatically keeps its height small in the face of arbitrary item insertions and deletions....
with two parameters: branching factor
Branching factor
In computing, tree data structures, and game theory, the branching factor is the number of children at each node. If this value is not uniform, an average branching factor can be calculated....
and threshold . Each non-leaf node contains at most entries of the form , where is a pointer to its th child nodeTree (data structure)
In computer science, a tree is a widely-used data structure that emulates a hierarchical tree structure with a set of linked nodes.Mathematically, it is an ordered directed tree, more specifically an arborescence: an acyclic connected graph where each node has zero or more children nodes and at...
and
is the subcluster represented by this child. A leaf node contains at most entries each of the form . It also has to two pointers prev and next which are used to chain all leaf nodes together. The tree size is a function of T. The larger the T is, the smaller the tree is. We also require a node to fit in a page of size of p. B and L are determined by P. So P can be varied for performance tuningPerformance tuning
Performance tuning is the improvement of system performance. This is typically a computer application, but the same methods can be applied to economic markets, bureaucracies or other complex systems. The motivation for such activity is called a performance problem, which can be real or anticipated....
. It is a very compact representation of the dataset because each entry in a leaf node is not a single data point but a subcluster.
In the algorithm in the first step it scans all data and builds an initial memory CF tree using the given amount of memory. In the second step it scans all the leaf entries in the initial CF tree to rebuild a smaller CF tree, while removing outliers and grouping crowded subclusters into larger ones. In step three we use an existing clustering algorithm to cluster all leaf entries. Here an agglomerative hierarchial clustering algorithm is applied directly to the subclusters represented by their CF vectors. It also provides the flexibiltiy of allowing the user to specify either the desired number of clusters or the desired diameter threshold for clusters. After this step we obtain a set of clusters that captures major distribution pattern in the data. However there might exist minor and localized inaccuracies which can be handled by an optional step 4. In step 4 we use the centroids of the clusters produced in step as seeds and redistribute the data points to its closest sees to obtain a new set of clusters. Step 4 also provides us with an option of discarding outliers. That is a point which is too far from its closest seed can be treated as an outlier.