

Adjusted Mutual Information
Encyclopedia
Adjusted mutual information
(AMI) is used for comparing clusterings. It corrects the effect of agreement solely due to chance between clusterings, similar to the way the adjusted rand index corrects the Rand index
. It is closely related to variation of information: when a similar adjustment is made to the VI index, it becomes equivalent to the AMI. The adjusted measure however is no longer metrical.
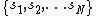 . We
. We
consider the case of hard clustering. Given two clusterings of S,
namely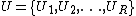 with R clusters, and
with R clusters, and
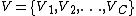 with C clusters
with C clusters
(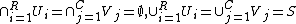 ), the information on cluster
), the information on cluster
overlap between U and V can be summarized in
the form of a RxC contingency table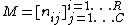 where
where 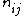 denotes the number of objects that are common to
denotes the number of objects that are common to
clusters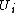 and
and 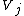 .
.
Suppose that we pick an object at random from S,
then the probability that the object falls into cluster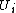 is:
is: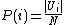
We define the entropy associated with the clustering U
as: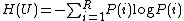
H(U) is non-negative and takes the value 0 only when
there is no uncertainty determining an object's cluster membership,
i.e., there is only one cluster. Similarly, the entropy of the
clustering V can be calculated as: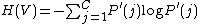 where
where 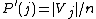 .
.
Now we arrive at the mutual information
(MI) between two
clusterings: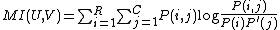
where P(i,j) denotes the probability that a point belongs to
cluster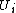 in U and cluster
in U and cluster 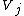 in V:
in V: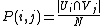
MI is a non-negative quantity upper bounded by the entropies
H(U) and H(V). It quantifies the information
shared by the two clusterings and thus can be employed as a
clustering similarity measure.
, the base line value of mutual information between two random clusterings does not take on a constant value, and tends to be larger when the two clusterings have a larger number of clusters (with a fixed number of data point N).
By adopting a hypergeometric model of randomness, it can be shown that the expected mutual information between two random clusterings is: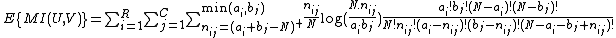
where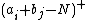
denotes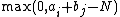 .
.
Then the adjusted measure for the mutual information can be: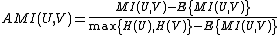
which takes a value of 1 when the two clusterings are identical and 0 when the MI between two clusterings equals to that expected by chance.
Mutual information
In probability theory and information theory, the mutual information of two random variables is a quantity that measures the mutual dependence of the two random variables...
(AMI) is used for comparing clusterings. It corrects the effect of agreement solely due to chance between clusterings, similar to the way the adjusted rand index corrects the Rand index
Rand index
The Rand index or Rand measure in statistics, and in particular in data clustering, is a measure of the similarity between two data clusterings...
. It is closely related to variation of information: when a similar adjustment is made to the VI index, it becomes equivalent to the AMI. The adjusted measure however is no longer metrical.
Preliminaries: Mutual Information
Let S be a set of N data points. Weconsider the case of hard clustering. Given two clusterings of S,
namely
with R clusters, and with C clusters(
), the information on clusteroverlap between U and V can be summarized in
the form of a RxC contingency table
where denotes the number of objects that are common toclusters
and .Suppose that we pick an object at random from S,
then the probability that the object falls into cluster
is:We define the entropy associated with the clustering U
as:
H(U) is non-negative and takes the value 0 only when
there is no uncertainty determining an object's cluster membership,
i.e., there is only one cluster. Similarly, the entropy of the
clustering V can be calculated as:
where .Now we arrive at the mutual information
Mutual information
In probability theory and information theory, the mutual information of two random variables is a quantity that measures the mutual dependence of the two random variables...
(MI) between two
clusterings:
where P(i,j) denotes the probability that a point belongs to
cluster
in U and cluster in V:MI is a non-negative quantity upper bounded by the entropies
H(U) and H(V). It quantifies the information
shared by the two clusterings and thus can be employed as a
clustering similarity measure.
Adjustment for chance
Like the Rand indexRand index
The Rand index or Rand measure in statistics, and in particular in data clustering, is a measure of the similarity between two data clusterings...
, the base line value of mutual information between two random clusterings does not take on a constant value, and tends to be larger when the two clusterings have a larger number of clusters (with a fixed number of data point N).
By adopting a hypergeometric model of randomness, it can be shown that the expected mutual information between two random clusterings is:
where
denotes
.Then the adjusted measure for the mutual information can be:
which takes a value of 1 when the two clusterings are identical and 0 when the MI between two clusterings equals to that expected by chance.