

Yates Analysis
Encyclopedia
Full- and fractional-factorial designs are common in designed experiments for engineering and scientific applications. In these designs, each factor is assigned two levels. These are typically called the low and high levels. For computational purposes, the factors are scaled so that the low level is assigned a value of -1 and the high level is assigned a value of +1. These are also commonly referred to as "-" and "+".
A full factorial design contains all possible combinations of low/high levels for all the factors. A fractional factorial design contains a carefully chosen subset of these combinations. The criterion for choosing the subsets is discussed in detail in the fractional factorial designs
article.
Formalized by Frank Yates
, a Yates analysis exploits the special structure of these designs to generate least squares
estimates for factor effects for all factors and all relevant interactions. The Yates analysis can be used to answer the following questions:
The mathematical details of the Yates analysis are given in chapter 10 of Box, Hunter, and Hunter (1978).
The Yates analysis is typically complemented by a number of graphical techniques such as the dex mean plot and the dex contour plot ("dex" stands for "design of experiments").
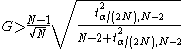




Determining the Yates order for fractional factorial designs requires knowledge of the confounding structure of the fractional factorial design.
A full factorial design contains all possible combinations of low/high levels for all the factors. A fractional factorial design contains a carefully chosen subset of these combinations. The criterion for choosing the subsets is discussed in detail in the fractional factorial designs
Fractional factorial designs
In statistics, fractional factorial designs are experimental designs consisting of a carefully chosen subset of the experimental runs of a full factorial design...
article.
Formalized by Frank Yates
Frank Yates
Frank Yates FRS was one of the pioneers of 20th century statistics.He was born in Manchester. Yates was the eldest of five children, and the only boy, born to Edith and Percy Yates. His father was a seed merchant. He attended Wadham House, a private school, before gaining a scholarship to Clifton...
, a Yates analysis exploits the special structure of these designs to generate least squares
Least squares
The method of least squares is a standard approach to the approximate solution of overdetermined systems, i.e., sets of equations in which there are more equations than unknowns. "Least squares" means that the overall solution minimizes the sum of the squares of the errors made in solving every...
estimates for factor effects for all factors and all relevant interactions. The Yates analysis can be used to answer the following questions:
- What is the ranked list of factors?
- What is the goodness-of-fit (as measured by the residual standard deviation) for the various models?
The mathematical details of the Yates analysis are given in chapter 10 of Box, Hunter, and Hunter (1978).
The Yates analysis is typically complemented by a number of graphical techniques such as the dex mean plot and the dex contour plot ("dex" stands for "design of experiments").
Yates order
Before performing a Yates analysis, the data should be arranged in "Yates order". That is, given k factors, the kth column consists of 2(k - 1) minus signs (i.e., the low level of the factor) followed by 2(k - 1) plus signs (i.e., the high level of the factor). For example, for a full factorial design with three factors, the design matrix isDetermining the Yates order for fractional factorial designs requires knowledge of the confounding structure of the fractional factorial design.
Output
A Yates analysis generates the following output.- A factor identifier (from Yates order). The specific identifier will vary depending on the program used to generate the Yates analysis. DataplotDataplotDataplot is a public-domain software system for scientific visualization and statistical analysis. It was developed at the National Institute of Standards and Technology.-External links:*...
, for example, uses the following for a 3-factor model.
-
- 1 = factor 1
- 2 = factor 2
- 3 = factor 3
- 12 = interaction of factor 1 and factor 2
- 13 = interaction of factor 1 and factor 3
- 23 = interaction of factor 2 and factor 3
- 123 = interaction of factors 1, 2, and 3
- A ranked list of important factors. That is, least squares estimated factor effects ordered from largest in magnitude (most significant) to smallest in magnitude (least significant).
- A t-value for the individual factor effect estimates. The t-value is computed as
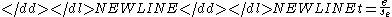
where e is the estimated factor effect and se is the standard deviationStandard deviationStandard deviation is a widely used measure of variability or diversity used in statistics and probability theory. It shows how much variation or "dispersion" there is from the average...
of the estimated factor effect.- The residual standard deviation that results from the model with the single term only. That is, the residual standard deviation from the model
-
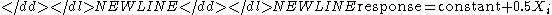
where Xi is the estimate of the ith factor or interaction effect.- The cumulative residual standard deviation that results from the model using the current term plus all terms preceding that term. That is,
-
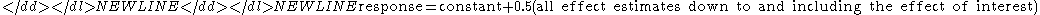
This consists of a monotonically decreasing set of residual standard deviations (indicating a better fit as the number of terms in the model increases). The first cumulative residual standard deviation is for the model-
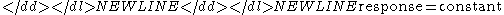
where the constant is the overall mean of the response variable. The last cumulative residual standard deviation is for the model-
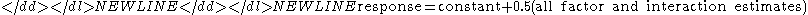
This last model will have a residual standard deviation of zero.
Parameter estimates as terms are added
In most cases of least squares fitting, the model coefficients for previously added terms change depending on what was successively added. For example, the X1 coefficient might change depending on whether or not an X2 term was included in the model. This is not the case when the design is orthogonal, as is a 23 full factorial design. For orthogonal designs, the estimates for the previously included terms do not change as additional terms are added. This means the ranked list of effect estimates simultaneously serves as the least squares coefficient estimates for progressively more complicated models.
Model selection and validation
From the above Yates output, one can define the potential models from the Yates analysis. An important component of a Yates analysis is selecting the best model from the available potential models. The above step lists all the potential models. From this list, we want to select the most appropriate model. This requires balancing the following two goals.- We want the model to include all important factors.
- We want the model to be parsimonious. That is, the model should be as simple as possible.
In short, we want our model to include all the important factors and interactions and to omit the unimportant factors and interactions. Note that the residual standard deviation alone is insufficient for determining the most appropriate model as it will always be decreased by adding additional factors. Instead, seven criteria are utilized to define important factors. These seven criteria are not all equally important, nor will they yield identical subsets, in which case a consensus subset or a weighted consensus subset must be extracted. In practice, some of these criteria may not apply in all situations, and some analysts may have additional criteria. These criteria are given as useful guidelines. Mosts analysts will focus on those criteria that they find most useful.- Practical significance of effects
- Order of magnitudeOrder of magnitudeAn order of magnitude is the class of scale or magnitude of any amount, where each class contains values of a fixed ratio to the class preceding it. In its most common usage, the amount being scaled is 10 and the scale is the exponent being applied to this amount...
of effects - Statistical significanceStatistical significanceIn statistics, a result is called statistically significant if it is unlikely to have occurred by chance. The phrase test of significance was coined by Ronald Fisher....
of effects - Probability plotProbability plotIn statistics, a P-P plot is a probability plot for assessing how closely two data sets agree, which plots the two cumulative distribution functions against each other....
s of effects - Youden plot of averages
- Practical significance of residual standard deviation
- Statistical significance of residual standard deviation
The first four criteria focus on effect sizeEffect sizeIn statistics, an effect size is a measure of the strength of the relationship between two variables in a statistical population, or a sample-based estimate of that quantity...
s with three numeric criteria and one graphical criterion. The fifth criterion focuses on averages. The last two criteria focus on the residual standard deviation of the model. Once a tentative model has been selected, the error term should follow the assumptions for a univariate measurement process. That is, the model should be validated by analyzing the residuals.
Graphical presentation
Some analysts may prefer a more graphical presentation of the Yates results. In particular, the following plots may be useful:- Ordered data plot
- Ordered absolute effects plot
- Cumulative residual standard deviation plot
Related Techniques
- Multi-factor analysis of variance
- Dex mean plot
- Block plot
- Dex contour plot
-
-