

Translation Lookaside Buffer
Encyclopedia
A translation lookaside buffer (TLB) is a CPU cache
that memory management hardware
uses to improve virtual address
translation speed. All current desktop and server processors (such as x86) use a TLB to map virtual and physical address spaces, and it is ubiquitous in any hardware which utilizes virtual memory.
The TLB is typically implemented as content-addressable memory
(CAM). The CAM search key is the virtual address and the search result is a physical address. If the requested address is present in the TLB, the CAM search yields a match quickly and the retrieved physical address can be used to access memory. This is called a TLB hit. If the requested address is not in the TLB, it is a miss, and the translation proceeds by looking up the page table
in a process called a page walk. The page walk is an expensive process, as it involves reading the contents of multiple memory locations and using them to compute the physical address. After the physical address is determined by the page walk, the virtual address to physical address mapping is entered into the TLB.
entries, which map virtual addresses to physical address
es. The virtual memory
is the space seen from a process. This space is segmented in pages of a prefixed size. The page table
(generally loaded in memory) keeps track of where the virtual pages are loaded in the physical memory. The TLB is a cache of the page table
; that is, only a subset of its content are stored.
The TLB references physical memory addresses in its table. It may reside between the CPU and the CPU cache
, between the CPU cache and primary storage memory, or between levels of a multi-level cache. The placement determines whether the cache uses physical or virtual addressing. If the cache is virtually addressed, requests are sent directly from the CPU to the cache, and the TLB is accessed only on a cache miss. If the cache is physically addressed, the CPU does a TLB lookup on every memory operation and the resulting physical address is sent to the cache. There are pros and cons to both implementations. Caches that use virtual addressing have for their key part of the virtual address plus, optionally, a key called an "address space identifier" (ASID). Caches that don't have ASIDs must be flushed every context switch
in a multiprocessing
environment.
In a Harvard architecture
or hybrid thereof, a separate virtual address space or memory access hardware may exist for instructions and data. This can lead to distinct TLBs for each access type.
A common optimization for physically addressed caches is to perform the TLB lookup in parallel with the cache access. The low-order bits of any virtual address (e.g., in a virtual memory
system having 4 KB pages, the lower 12 bits of the virtual address) represent the offset of the desired address within the page, and thus they do not change in the virtual-to-physical translation. During a cache access, two steps are performed: an index is used to find an entry in the cache's data store, and then the tags for the cache line found are compared. If the cache is structured in such a way that it can be indexed using only the bits that do not change in translation, the cache can perform its "index" operation while the TLB translates the upper bits of the address. Then, the translated address from the TLB is passed to the cache. The cache performs a tag comparison to determine if this access was a hit or miss. It is possible to perform the TLB lookup in parallel with the cache access even if the cache must be indexed using some bits that may change upon address translation; see the address translation section in the cache article for more details about virtual addressing as it pertains to caches and TLBs.
The third case (the simplest case) is where the desired information itself actually is in a cache, but the information for virtual-to-physical translation is not in a TLB. These are all about equally slow, so a program "thrashing" the TLB will run just as poorly as one thrashing an instruction or data cache. That is why a well functioning TLB is important.
For instance, Intel's Nehalem microarchitecture has a four-way set associative L1 DTLB with 64 entries for 4 KiB pages and 32 entries for 2/4 MiB pages, an L1 ITLB with 128 entries for 4 KiB pages using four-way associativity and 14 fully associative entries for 2/4 MiB pages (both parts of the ITLB divided statically between two threads) and a unified 512-entry L2 TLB for 4 KiB pages, both 4-way associative.
Some TLBs may have separate sections for small pages and huge pages.
The Itanium
architecture provides an option of using either software or hardware managed TLBs.
The Alpha
architecture's TLB is managed in PALcode
, rather than in the operating system. As the PALcode for a processor can be processor-specific and operating-system-specific, this allows different versions of PALcode to implement different page table formats for different operating systems, without requiring that the TLB format, and the instructions to control the TLB, to be specified by the architecture.
If a TLB hit takes 1 clock cycle, a miss takes 30 clock cycles, and the miss rate is 1%, the effective memory cycle rate is an average of
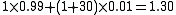
(1.30 clock cycles per memory access).
, some TLB entries can become invalid, since the virtual-to-physical mapping is different. The simplest strategy to deal with this is to completely flush the TLB. Newer CPUs use more effective strategies marking which process an entry is for. This means that if a second process runs for only a short time and jumps back to a first process, it may still have valid entries, saving the time to reload them.
For example in the Alpha 21264
, each TLB entry is tagged with an "address space number" (ASN), and only TLB entries with an ASN matching the current task are considered valid. Another example in the Intel Pentium Pro, the page global enable (PGE) flag in the register CR4 and the global (G) flag of a page-directory or page-table entry can be used to prevent frequently used pages from being automatically invalidated in the TLBs on a task switch or a load of register CR3.
While selective flushing of the TLB is an option in software managed TLBs, the only option in some hardware TLBs (for example, the TLB in the Intel 80386
) is the complete flushing of the TLB on a context switch. Other hardware TLBs (for example, the TLB in the Intel 80486
and later x86 processors, and the TLB in ARM
processors) allow the flushing of individual entries from the TLB indexed by virtual address.
Normally, the entries in the x86 TLBs are not associated with any address space. Hence, every time there is a change in address space, such as a context switch, the entire TLB has to be flushed. Maintaining a tag which associates each TLB entry with an address space in software and comparing this tag during TLB lookup and TLB flush is very expensive, especially since the x86 TLB is designed to operate with very low latency and completely in hardware. In 2008, both Intel (Nehalem) and AMD (SVM) have introduced tags as part of the TLB entry and dedicated hardware which checks the tag during lookup. Even though these are not fully exploited, it is envisioned that in the future, these tags will identify the address space to which every TLB entry belongs. Thus a context switch will not result in the flushing of the TLB – but just changing the tag of the current address space to the tag of the address space of the new task.
CPU cache
A CPU cache is a cache used by the central processing unit of a computer to reduce the average time to access memory. The cache is a smaller, faster memory which stores copies of the data from the most frequently used main memory locations...
that memory management hardware
Memory management unit
A memory management unit , sometimes called paged memory management unit , is a computer hardware component responsible for handling accesses to memory requested by the CPU...
uses to improve virtual address
Virtual address
In computer technology, a virtual address is an address identifying a virtual, i.e. non-physical, entity.-Description:The term virtual address is most commonly used for an address pointing to virtual memory or, in networking, when referring to a virtual network address...
translation speed. All current desktop and server processors (such as x86) use a TLB to map virtual and physical address spaces, and it is ubiquitous in any hardware which utilizes virtual memory.
The TLB is typically implemented as content-addressable memory
Content-addressable memory
Content-addressable memory is a special type of computer memory used in certain very high speed searching applications. It is also known as associative memory, associative storage, or associative array, although the last term is more often used for a programming data structure...
(CAM). The CAM search key is the virtual address and the search result is a physical address. If the requested address is present in the TLB, the CAM search yields a match quickly and the retrieved physical address can be used to access memory. This is called a TLB hit. If the requested address is not in the TLB, it is a miss, and the translation proceeds by looking up the page table
Page table
A page table is the data structure used by a virtual memory system in a computer operating system to store the mapping between virtual addresses and physical addresses. Virtual addresses are those unique to the accessing process...
in a process called a page walk. The page walk is an expensive process, as it involves reading the contents of multiple memory locations and using them to compute the physical address. After the physical address is determined by the page walk, the virtual address to physical address mapping is entered into the TLB.
Overview
A TLB has a fixed number of slots that contain page tablePage table
A page table is the data structure used by a virtual memory system in a computer operating system to store the mapping between virtual addresses and physical addresses. Virtual addresses are those unique to the accessing process...
entries, which map virtual addresses to physical address
Physical address
In computing, a physical address, also real address, or binary address, is the memory address that is represented in the form of a binary number on the address bus circuitry in order to enable the data bus to access a particular storage cell of main memory.In a computer with virtual memory, the...
es. The virtual memory
Virtual memory
In computing, virtual memory is a memory management technique developed for multitasking kernels. This technique virtualizes a computer architecture's various forms of computer data storage , allowing a program to be designed as though there is only one kind of memory, "virtual" memory, which...
is the space seen from a process. This space is segmented in pages of a prefixed size. The page table
Page table
A page table is the data structure used by a virtual memory system in a computer operating system to store the mapping between virtual addresses and physical addresses. Virtual addresses are those unique to the accessing process...
(generally loaded in memory) keeps track of where the virtual pages are loaded in the physical memory. The TLB is a cache of the page table
Page table
A page table is the data structure used by a virtual memory system in a computer operating system to store the mapping between virtual addresses and physical addresses. Virtual addresses are those unique to the accessing process...
; that is, only a subset of its content are stored.
The TLB references physical memory addresses in its table. It may reside between the CPU and the CPU cache
CPU cache
A CPU cache is a cache used by the central processing unit of a computer to reduce the average time to access memory. The cache is a smaller, faster memory which stores copies of the data from the most frequently used main memory locations...
, between the CPU cache and primary storage memory, or between levels of a multi-level cache. The placement determines whether the cache uses physical or virtual addressing. If the cache is virtually addressed, requests are sent directly from the CPU to the cache, and the TLB is accessed only on a cache miss. If the cache is physically addressed, the CPU does a TLB lookup on every memory operation and the resulting physical address is sent to the cache. There are pros and cons to both implementations. Caches that use virtual addressing have for their key part of the virtual address plus, optionally, a key called an "address space identifier" (ASID). Caches that don't have ASIDs must be flushed every context switch
Context switch
A context switch is the computing process of storing and restoring the state of a CPU so that execution can be resumed from the same point at a later time. This enables multiple processes to share a single CPU. The context switch is an essential feature of a multitasking operating system...
in a multiprocessing
Multiprocessing
Multiprocessing is the use of two or more central processing units within a single computer system. The term also refers to the ability of a system to support more than one processor and/or the ability to allocate tasks between them...
environment.
In a Harvard architecture
Harvard architecture
The Harvard architecture is a computer architecture with physically separate storage and signal pathways for instructions and data. The term originated from the Harvard Mark I relay-based computer, which stored instructions on punched tape and data in electro-mechanical counters...
or hybrid thereof, a separate virtual address space or memory access hardware may exist for instructions and data. This can lead to distinct TLBs for each access type.
A common optimization for physically addressed caches is to perform the TLB lookup in parallel with the cache access. The low-order bits of any virtual address (e.g., in a virtual memory
Virtual memory
In computing, virtual memory is a memory management technique developed for multitasking kernels. This technique virtualizes a computer architecture's various forms of computer data storage , allowing a program to be designed as though there is only one kind of memory, "virtual" memory, which...
system having 4 KB pages, the lower 12 bits of the virtual address) represent the offset of the desired address within the page, and thus they do not change in the virtual-to-physical translation. During a cache access, two steps are performed: an index is used to find an entry in the cache's data store, and then the tags for the cache line found are compared. If the cache is structured in such a way that it can be indexed using only the bits that do not change in translation, the cache can perform its "index" operation while the TLB translates the upper bits of the address. Then, the translated address from the TLB is passed to the cache. The cache performs a tag comparison to determine if this access was a hit or miss. It is possible to perform the TLB lookup in parallel with the cache access even if the cache must be indexed using some bits that may change upon address translation; see the address translation section in the cache article for more details about virtual addressing as it pertains to caches and TLBs.
Implications for performance
The CPU has to access main memory for a:- instruction cache miss
- data cache miss
- TLB miss
The third case (the simplest case) is where the desired information itself actually is in a cache, but the information for virtual-to-physical translation is not in a TLB. These are all about equally slow, so a program "thrashing" the TLB will run just as poorly as one thrashing an instruction or data cache. That is why a well functioning TLB is important.
Multiple TLBs
Similar to caches, TLBs may have multiple levels. CPUs can be (and nowadays usually are) built with multiple TLBs, for example a small "L1" TLB (potentially fully associative) that is extremely fast, and a larger "L2" TLB that is somewhat slower. When ITLB and DTLB are used, a CPU can have three (ITLB1, DTLB1, TLB2) or four TLBs.For instance, Intel's Nehalem microarchitecture has a four-way set associative L1 DTLB with 64 entries for 4 KiB pages and 32 entries for 2/4 MiB pages, an L1 ITLB with 128 entries for 4 KiB pages using four-way associativity and 14 fully associative entries for 2/4 MiB pages (both parts of the ITLB divided statically between two threads) and a unified 512-entry L2 TLB for 4 KiB pages, both 4-way associative.
Some TLBs may have separate sections for small pages and huge pages.
TLB miss handling
Two schemes for handling TLB misses are commonly found in modern architectures:- With hardware TLB management, the CPU itself walks the page tablePage tableA page table is the data structure used by a virtual memory system in a computer operating system to store the mapping between virtual addresses and physical addresses. Virtual addresses are those unique to the accessing process...
s (using the CR3 register on x86 for instance) to see if there is a valid page table entry for the specified virtual address. If an entry exists, it is brought into the TLB and the TLB access is retried: this time the access will hit, and the program can proceed normally. If the CPU finds no valid entry for the virtual address in the page tables, it raises a page faultPage faultA page fault is a trap to the software raised by the hardware when a program accesses a page that is mapped in the virtual address space, but not loaded in physical memory. In the typical case the operating system tries to handle the page fault by making the required page accessible at a location...
exceptionException handlingException handling is a programming language construct or computer hardware mechanism designed to handle the occurrence of exceptions, special conditions that change the normal flow of program execution....
, which the operating systemOperating systemAn operating system is a set of programs that manage computer hardware resources and provide common services for application software. The operating system is the most important type of system software in a computer system...
must handle. Handling page faults usually involves bringing the requested data into physical memory, setting up a page table entry to map the faulting virtual address to the correct physical address, and resuming the program (see Page faultPage faultA page fault is a trap to the software raised by the hardware when a program accesses a page that is mapped in the virtual address space, but not loaded in physical memory. In the typical case the operating system tries to handle the page fault by making the required page accessible at a location...
for more details.) With a hardware-managed TLB, the format of the TLB entries is not visible to software, and can change from CPU to CPU without causing loss of compatibility for the programs. - With software-managed TLBs, a TLB miss generates a "TLB miss" exception, and the operating system must walk the page tables and perform the translation in software. The operating system then loads the translation into the TLB and restarts the program from the instruction that caused the TLB miss. As with hardware TLB management, if the OS finds no valid translation in the page tables, a page fault has occurred, and the OS must handle it accordingly. Instruction setsInstruction setAn instruction set, or instruction set architecture , is the part of the computer architecture related to programming, including the native data types, instructions, registers, addressing modes, memory architecture, interrupt and exception handling, and external I/O...
of CPUs that have software-managed TLBs have instructions that allow loading entries into any slot in the TLB. The format of the TLB entry is defined as a part of the instruction set architecture (ISA). The MIPS architectureMIPS architectureMIPS is a reduced instruction set computer instruction set architecture developed by MIPS Technologies . The early MIPS architectures were 32-bit, and later versions were 64-bit...
specifies a software-managed TLB; the SPARC V9 architecture allows an implementation of SPARC V9 to have no MMU, an MMU with a software-managed TLB, or an MMU with a hardware-managed TLB., and the UltraSPARC architecture specifies a software-managed TLB.
The Itanium
Itanium
Itanium is a family of 64-bit Intel microprocessors that implement the Intel Itanium architecture . Intel markets the processors for enterprise servers and high-performance computing systems...
architecture provides an option of using either software or hardware managed TLBs.
The Alpha
DEC Alpha
Alpha, originally known as Alpha AXP, is a 64-bit reduced instruction set computer instruction set architecture developed by Digital Equipment Corporation , designed to replace the 32-bit VAX complex instruction set computer ISA and its implementations. Alpha was implemented in microprocessors...
architecture's TLB is managed in PALcode
PALcode
In computing, in the Alpha instruction set architecture, PALcode is the name used by DEC for a set of functions in the SRM or AlphaBIOS firmware, providing a hardware abstraction layer for system software, covering features such as cache management, translation lookaside buffer miss handling,...
, rather than in the operating system. As the PALcode for a processor can be processor-specific and operating-system-specific, this allows different versions of PALcode to implement different page table formats for different operating systems, without requiring that the TLB format, and the instructions to control the TLB, to be specified by the architecture.
Typical TLB
- Size: 8 - 4,096 entries
- Hit time: 0.5 - 1 clock cycle
- Miss penalty: 10 - 100 clock cycles
- Miss rate: 0.01 - 1%
If a TLB hit takes 1 clock cycle, a miss takes 30 clock cycles, and the miss rate is 1%, the effective memory cycle rate is an average of
(1.30 clock cycles per memory access).
Context switch
On a context switchContext switch
A context switch is the computing process of storing and restoring the state of a CPU so that execution can be resumed from the same point at a later time. This enables multiple processes to share a single CPU. The context switch is an essential feature of a multitasking operating system...
, some TLB entries can become invalid, since the virtual-to-physical mapping is different. The simplest strategy to deal with this is to completely flush the TLB. Newer CPUs use more effective strategies marking which process an entry is for. This means that if a second process runs for only a short time and jumps back to a first process, it may still have valid entries, saving the time to reload them.
For example in the Alpha 21264
Alpha 21264
The Alpha 21264 was a Digital Equipment Corporation RISC microprocessor introduced in October, 1996. The 21264 implemented the Alpha instruction set architecture .- Description :...
, each TLB entry is tagged with an "address space number" (ASN), and only TLB entries with an ASN matching the current task are considered valid. Another example in the Intel Pentium Pro, the page global enable (PGE) flag in the register CR4 and the global (G) flag of a page-directory or page-table entry can be used to prevent frequently used pages from being automatically invalidated in the TLBs on a task switch or a load of register CR3.
While selective flushing of the TLB is an option in software managed TLBs, the only option in some hardware TLBs (for example, the TLB in the Intel 80386
Intel 80386
The Intel 80386, also known as the i386, or just 386, was a 32-bit microprocessor introduced by Intel in 1985. The first versions had 275,000 transistors and were used as the central processing unit of many workstations and high-end personal computers of the time...
) is the complete flushing of the TLB on a context switch. Other hardware TLBs (for example, the TLB in the Intel 80486
Intel 80486
The Intel 80486 microprocessor was a higher performance follow up on the Intel 80386. Introduced in 1989, it was the first tightly pipelined x86 design as well as the first x86 chip to use more than a million transistors, due to a large on-chip cache and an integrated floating point unit...
and later x86 processors, and the TLB in ARM
ARM architecture
ARM is a 32-bit reduced instruction set computer instruction set architecture developed by ARM Holdings. It was named the Advanced RISC Machine, and before that, the Acorn RISC Machine. The ARM architecture is the most widely used 32-bit ISA in numbers produced...
processors) allow the flushing of individual entries from the TLB indexed by virtual address.
Virtualization and x86 TLB
With the advent of virtualization for server consolidation, a lot of effort has gone into making the x86 architecture easier to virtualize and to ensure better performance of virtual machines on x86 hardware. In a long list of such changes to the x86 architecture, the TLB is the latest.Normally, the entries in the x86 TLBs are not associated with any address space. Hence, every time there is a change in address space, such as a context switch, the entire TLB has to be flushed. Maintaining a tag which associates each TLB entry with an address space in software and comparing this tag during TLB lookup and TLB flush is very expensive, especially since the x86 TLB is designed to operate with very low latency and completely in hardware. In 2008, both Intel (Nehalem) and AMD (SVM) have introduced tags as part of the TLB entry and dedicated hardware which checks the tag during lookup. Even though these are not fully exploited, it is envisioned that in the future, these tags will identify the address space to which every TLB entry belongs. Thus a context switch will not result in the flushing of the TLB – but just changing the tag of the current address space to the tag of the address space of the new task.
See also
- Memory managementMemory managementMemory management is the act of managing computer memory. The essential requirement of memory management is to provide ways to dynamically allocate portions of memory to programs at their request, and freeing it for reuse when no longer needed. This is critical to the computer system.Several...
- PagingPagingIn computer operating systems, paging is one of the memory-management schemes by which a computer can store and retrieve data from secondary storage for use in main memory. In the paging memory-management scheme, the operating system retrieves data from secondary storage in same-size blocks called...