

The iDistance Technique
Encyclopedia
In pattern recognition
, the iDistance is an indexing and query processing technique for k-nearest neighbor queries
on point data in multi-dimensional
metric space
s. The kNN query is one of the hardest problems on multi-dimensional data, especially when the dimensionality of the data is high
. The iDistance is designed to process kNN queries in high-dimensional spaces efficiently and it is especially good for skewed data distributions, which usually occur in real-life data sets.
 Building the iDistance index has two steps:
Building the iDistance index has two steps:
point's iDistance. By this means, points in a multi-dimensional space are mapped to one-dimensional values, and then a B+-tree
can be adopted to index the points using the iDistance as the key.
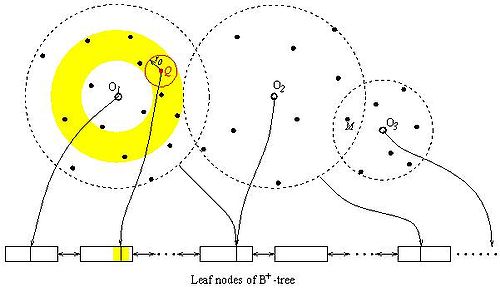
The figure on the right shows an example where three reference points (O1, O2, O3) are chosen. The data points are then mapped to a one-dimensional space and indexed in a B+-tree.
one-dimensional range queries, which can be processed efficiently
on a B+-tree. In the above figure, the query Q is mapped to a value in the B+-tree while the kNN search ``sphere" is mapped to a range in the B+-tree. The search sphere expands gradually until the k NNs are found. This corresponds to gradually expanding range searches in the B+-tree.
The iDistance technique can be viewed as a way of accelerating the sequential scan. Instead of scanning records from the beginning to the end of the data file, the iDistance starts the scan from spots where the nearest neighbors can be obtained early with a very high probability.
Kian-Lee Tan and H V Jagadish
in 2001. Later, together with Rui Zhang, they improved the technique and performed
a more comprehensive study on it in 2005.
Pattern recognition
In machine learning, pattern recognition is the assignment of some sort of output value to a given input value , according to some specific algorithm. An example of pattern recognition is classification, which attempts to assign each input value to one of a given set of classes...
, the iDistance is an indexing and query processing technique for k-nearest neighbor queries
K-nearest neighbor algorithm
In pattern recognition, the k-nearest neighbor algorithm is a method for classifying objects based on closest training examples in the feature space. k-NN is a type of instance-based learning, or lazy learning where the function is only approximated locally and all computation is deferred until...
on point data in multi-dimensional
Dimension
In physics and mathematics, the dimension of a space or object is informally defined as the minimum number of coordinates needed to specify any point within it. Thus a line has a dimension of one because only one coordinate is needed to specify a point on it...
metric space
Metric space
In mathematics, a metric space is a set where a notion of distance between elements of the set is defined.The metric space which most closely corresponds to our intuitive understanding of space is the 3-dimensional Euclidean space...
s. The kNN query is one of the hardest problems on multi-dimensional data, especially when the dimensionality of the data is high
Curse of dimensionality
The curse of dimensionality refers to various phenomena that arise when analyzing and organizing high-dimensional spaces that do not occur in low-dimensional settings such as the physical space commonly modeled with just three dimensions.There are multiple phenomena referred to by this name in...
. The iDistance is designed to process kNN queries in high-dimensional spaces efficiently and it is especially good for skewed data distributions, which usually occur in real-life data sets.
Indexing
- A number of reference points in the data space are chosen. There are various ways of choosing reference points. Using cluster centers as reference points is the most efficient way.
- The distance between a data point and its closest reference point is calculated. This distance plus a scaling value is called the
point's iDistance. By this means, points in a multi-dimensional space are mapped to one-dimensional values, and then a B+-tree
B+ tree
In computer science, a B+ tree or B plus tree is a type of tree which represents sorted data in a way that allows for efficient insertion, retrieval and removal of records, each of which is identified by a key. It is a dynamic, multilevel index, with maximum and minimum bounds on the number of...
can be adopted to index the points using the iDistance as the key.
The figure on the right shows an example where three reference points (O1, O2, O3) are chosen. The data points are then mapped to a one-dimensional space and indexed in a B+-tree.
Query processing
To process a kNN query, the query is mapped to a number ofone-dimensional range queries, which can be processed efficiently
on a B+-tree. In the above figure, the query Q is mapped to a value in the B+-tree while the kNN search ``sphere" is mapped to a range in the B+-tree. The search sphere expands gradually until the k NNs are found. This corresponds to gradually expanding range searches in the B+-tree.
The iDistance technique can be viewed as a way of accelerating the sequential scan. Instead of scanning records from the beginning to the end of the data file, the iDistance starts the scan from spots where the nearest neighbors can be obtained early with a very high probability.
Applications
The iDistance has been used in many applications including- Image Retrieval
- Video indexing
- Similarity search in P2P systems
- Mobile computing
Historical background
The iDistance was first proposed by Cui Yu, Beng Chin Ooi,Kian-Lee Tan and H V Jagadish
H V Jagadish
Hosagrahar Visvesvaraya Jagadish is a computer scientist in the field of database systems research. He is the Bernard A. Galler Collegiate Professor of Electrical Engineering and Computer Science at the University of Michigan at Ann Arbor and a Senior Scientific Director of the established by the...
in 2001. Later, together with Rui Zhang, they improved the technique and performed
a more comprehensive study on it in 2005.