

Sørensen similarity index
Encyclopedia
The Sørensen index, also known as Sørensen’s similarity coefficient, is a statistic
used for comparing the similarity
of two samples
. It was developed by the botanist Thorvald Sørensen
and published in 1948.
It is often misspelled as Sorenson index, Soerenson index and Sörenson index (also with the correct ending -sen).
Sørensen's original formula was intended to be applied to presence/absence data, and is
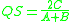
where A and B are the number of species in samples A and B, respectively, and C is the number of species shared by the two samples; QS is the quotient of similarity and ranges from 0 - 1. This expression is easily extended to abundance
instead of presence/absence of species. This quantitative version of the Sørensen index is also known as Czekanowski
index. The Sørensen index is identical to Dice's coefficient which is always in [0, 1] range. The Sørensen index used as a distance measure, 1 − QS, is identical to Hellinger distance
and Bray Curtis dissimilarity
when applied to quantitative data.
The Sørensen coefficient is mainly useful for ecological community data (e.g. Looman & Campbell, 1960). Justification for its use is primarily empirical rather than theoretical (although it can be justified theoretically as the intersection of two fuzzy set
s). As compared to Euclidean distance
, Sørensen distance retains sensitivity in more heterogeneous data sets and gives less weight to outliers .
Statistic
A statistic is a single measure of some attribute of a sample . It is calculated by applying a function to the values of the items comprising the sample which are known together as a set of data.More formally, statistical theory defines a statistic as a function of a sample where the function...
used for comparing the similarity
Similarity
-Specific definitions:Different fields provide differing definitions of similarity:-In computer science:* string metric, aka string similarity* semantic similarity in computational linguistics-In other fields:...
of two samples
Sample (statistics)
In statistics, a sample is a subset of a population. Typically, the population is very large, making a census or a complete enumeration of all the values in the population impractical or impossible. The sample represents a subset of manageable size...
. It was developed by the botanist Thorvald Sørensen
Thorvald Sørensen
Thorvald Julius Sørensen was a Danish botanist and evolutionary biologist.Sørensen was professor at the Royal Veterinary and Agricultural College 1953-1955 and at the University of Copenhagen 1955-1972...
and published in 1948.
It is often misspelled as Sorenson index, Soerenson index and Sörenson index (also with the correct ending -sen).
Sørensen's original formula was intended to be applied to presence/absence data, and is
where A and B are the number of species in samples A and B, respectively, and C is the number of species shared by the two samples; QS is the quotient of similarity and ranges from 0 - 1. This expression is easily extended to abundance
Abundance
Abundance may refer to:In science and technology:* Abundance , the opposite of scarcities* Abundance , growing food with plentiful resources that will not run out -- sunshine, CO2, and waste or brine water....
instead of presence/absence of species. This quantitative version of the Sørensen index is also known as Czekanowski
Jan Czekanowski
Jan Czekanowski was a Polish anthropologist, statistician and linguist. Czekanowski is known for having played an important role in saving the Polish-Lithuanian branch of the Karaim people from Holocaust extermination...
index. The Sørensen index is identical to Dice's coefficient which is always in [0, 1] range. The Sørensen index used as a distance measure, 1 − QS, is identical to Hellinger distance
Hellinger distance
In probability and statistics, the Hellinger distance is used to quantify the similarity between two probability distributions. It is a type of f-divergence...
and Bray Curtis dissimilarity
Bray Curtis dissimilarity
In ecology and biology, the Bray–Curtis dissimilarity, named after J. Roger Bray and John T. Curtis, is a statistic used to quantify the compositional dissimilarity between two different sites. It is equivalent to the total number of species that are unique to any one of the two sites divided by...
when applied to quantitative data.
The Sørensen coefficient is mainly useful for ecological community data (e.g. Looman & Campbell, 1960). Justification for its use is primarily empirical rather than theoretical (although it can be justified theoretically as the intersection of two fuzzy set
Fuzzy set
Fuzzy sets are sets whose elements have degrees of membership. Fuzzy sets were introduced simultaneously by Lotfi A. Zadeh and Dieter Klaua in 1965 as an extension of the classical notion of set. In classical set theory, the membership of elements in a set is assessed in binary terms according to...
s). As compared to Euclidean distance
Euclidean distance
In mathematics, the Euclidean distance or Euclidean metric is the "ordinary" distance between two points that one would measure with a ruler, and is given by the Pythagorean formula. By using this formula as distance, Euclidean space becomes a metric space...
, Sørensen distance retains sensitivity in more heterogeneous data sets and gives less weight to outliers .
See also
- Jaccard indexJaccard indexThe Jaccard index, also known as the Jaccard similarity coefficient , is a statistic used for comparing the similarity and diversity of sample sets....
- Kulczyński similarity index
- Renkonen similarity index (due to Olavi Renkonen)
- Czekanowski similarity index
- Hamming distanceHamming distanceIn information theory, the Hamming distance between two strings of equal length is the number of positions at which the corresponding symbols are different...
- CorrelationCorrelationIn statistics, dependence refers to any statistical relationship between two random variables or two sets of data. Correlation refers to any of a broad class of statistical relationships involving dependence....