

Q-learning
Encyclopedia
Q-learning is a reinforcement learning
technique that works by learning an action-value function that gives the expected utility of taking a given action in a given state and following a fixed policy thereafter. One of the strengths of Q-learning is that it is able to compare the expected utility of the available actions without requiring a model of the environment. A recent variation called delayed Q-learning has shown substantial improvements, bringing Probably approximately correct learning (PAC)
bounds to Markov decision process
es
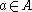 , the agent can move from state to state. Each state provides the agent a reward (a real or natural number). The goal of the agent is to maximize its total reward. It does this by learning which action is optimal for each state.
, the agent can move from state to state. Each state provides the agent a reward (a real or natural number). The goal of the agent is to maximize its total reward. It does this by learning which action is optimal for each state.
The algorithm therefore has a function which calculates the Quality of a state-action combination:
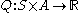
Before learning has started, Q returns a fixed value, chosen by the designer. Then, each time the agent is given a reward (the state has changed) new values are calculated for each combination of a state s from S, and action a from A. The core of the algorithm is a simple value iteration update. It assumes the old value and makes a correction based on the new information.
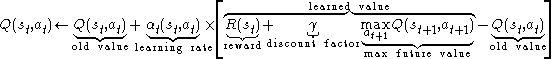
Where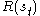 is the reward observed from
is the reward observed from 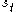 ,
, 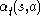 (
(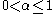 ) the learning rate (may be the same for all pairs). The discount factor
) the learning rate (may be the same for all pairs). The discount factor 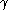 is such that
is such that 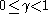
The above formula is equivalent to:
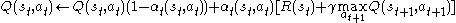
An episode of the algorithm ends when state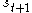 is a final state (or, "absorbing state").
is a final state (or, "absorbing state").
Note that for all final states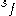 ,
, 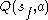 is never updated and thus retains its initial value.
is never updated and thus retains its initial value.
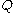 values may diverge.
values may diverge.
as a function approximator, as demonstrated by Tesauro in his Backgammon
playing temporal difference learning
research. An adaptation of the standard neural network is required because the required result (from which the error signal is generated) is itself generated at run-time.
The convergence proof was presented later by Watkins and Dayan in 1992.
Reinforcement learning
Inspired by behaviorist psychology, reinforcement learning is an area of machine learning in computer science, concerned with how an agent ought to take actions in an environment so as to maximize some notion of cumulative reward...
technique that works by learning an action-value function that gives the expected utility of taking a given action in a given state and following a fixed policy thereafter. One of the strengths of Q-learning is that it is able to compare the expected utility of the available actions without requiring a model of the environment. A recent variation called delayed Q-learning has shown substantial improvements, bringing Probably approximately correct learning (PAC)
Probably approximately correct learning
In computational learning theory, probably approximately correct learning is a framework for mathematical analysis of machine learning. It was proposed in 1984 by Leslie Valiant....
bounds to Markov decision process
Markov decision process
Markov decision processes , named after Andrey Markov, provide a mathematical framework for modeling decision-making in situations where outcomes are partly random and partly under the control of a decision maker. MDPs are useful for studying a wide range of optimization problems solved via...
es
Algorithm
The problem model consists of an agent, states S and a set of actions per state A. By performing an action, the agent can move from state to state. Each state provides the agent a reward (a real or natural number). The goal of the agent is to maximize its total reward. It does this by learning which action is optimal for each state.The algorithm therefore has a function which calculates the Quality of a state-action combination:
Before learning has started, Q returns a fixed value, chosen by the designer. Then, each time the agent is given a reward (the state has changed) new values are calculated for each combination of a state s from S, and action a from A. The core of the algorithm is a simple value iteration update. It assumes the old value and makes a correction based on the new information.
Where
is the reward observed from , () the learning rate (may be the same for all pairs). The discount factor is such that The above formula is equivalent to:
An episode of the algorithm ends when state
is a final state (or, "absorbing state").Note that for all final states
, is never updated and thus retains its initial value.Learning rate
The learning rate determines to what extent the newly acquired information will override the old information. A factor of 0 will make the agent not learn anything, while a factor of 1 would make the agent consider only the most recent information.Discount factor
The discount factor determines the importance of future rewards. A factor of 0 will make the agent "opportunistic" by only considering current rewards, while a factor approaching 1 will make it strive for a long-term high reward. If the discount factor meets or exceeds 1, the values may diverge.Implementation
Q-learning at its simplest uses tables to store data. This very quickly loses viability with increasing levels of complexity of the system it is monitoring/controlling. One answer to this problem is to use an (adapted) artificial neural networkArtificial neural network
An artificial neural network , usually called neural network , is a mathematical model or computational model that is inspired by the structure and/or functional aspects of biological neural networks. A neural network consists of an interconnected group of artificial neurons, and it processes...
as a function approximator, as demonstrated by Tesauro in his Backgammon
Backgammon
Backgammon is one of the oldest board games for two players. The playing pieces are moved according to the roll of dice, and players win by removing all of their pieces from the board. There are many variants of backgammon, most of which share common traits...
playing temporal difference learning
Temporal difference learning
Temporal difference learning is a prediction method. It has been mostly used for solving the reinforcement learning problem. "TD learning is a combination of Monte Carlo ideas and dynamic programming ideas." TD resembles a Monte Carlo method because it learns by sampling the environment according...
research. An adaptation of the standard neural network is required because the required result (from which the error signal is generated) is itself generated at run-time.
Early study
Q-learning was first introduced by Watkins in 1989.The convergence proof was presented later by Watkins and Dayan in 1992.
See also
- Reinforcement learningReinforcement learningInspired by behaviorist psychology, reinforcement learning is an area of machine learning in computer science, concerned with how an agent ought to take actions in an environment so as to maximize some notion of cumulative reward...
- Temporal difference learningTemporal difference learningTemporal difference learning is a prediction method. It has been mostly used for solving the reinforcement learning problem. "TD learning is a combination of Monte Carlo ideas and dynamic programming ideas." TD resembles a Monte Carlo method because it learns by sampling the environment according...
- SARSASARSASARSA is an algorithm for learning a Markov decision process policy, used in the reinforcement learning area of machine learning...
- Iterated prisoner's dilemma
- Game theoryGame theoryGame theory is a mathematical method for analyzing calculated circumstances, such as in games, where a person’s success is based upon the choices of others...
- Fitted Q iteration algorithm
External links
- Q-Learning topic on KnolKnolKnol is a Google project that aims to include user-written articles on a range of topics. The project was led by Udi Manber of Google, announced December 13, 2007, and was opened in beta to the public on July 23, 2008 with a few hundred articles mostly in the health and medical field.Knol has no...
- Watkins, C.J.C.H. (1989). Learning from Delayed Rewards. PhD thesis, Cambridge University, Cambridge, England.
- Strehl, Li, Wiewiora, Langford, Littman (2006). PAC model-free reinforcement learning
- Q-Learning by Examples
- Reinforcement Learning: An Introduction by Richard Sutton and Andrew S. Barto, an online textbook. See "6.5 Q-Learning: Off-Policy TD Control".
- Connectionist Q-learning Java Framework
- Piqle: a Generic Java Platform for Reinforcement Learning
- Reinforcement Learning Maze, a demonstration of guiding an ant through a maze using Q-learning.
- Q-learning work by Gerald Tesauro
- Q-learning work by Tesauro Citeseer Link
- Q-learning algorithm implemented in processing.org language
- Example java applet for pole balancing in 2D with source code