
Genetic code
Overview
The genetic code is the set of rules by which information encoded in genetic material (DNA
or mRNA sequences) is translated
into protein
s (amino acid
sequences) by living cell
s.
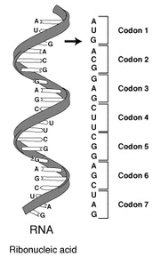
The code defines how sequences of three nucleotides, called codons, specify which amino acid will be added next during protein synthesis. With some exceptions, a three-nucleotide codon in a nucleic acid sequence specifies a single amino acid.
DNA
Deoxyribonucleic acid is a nucleic acid that contains the genetic instructions used in the development and functioning of all known living organisms . The DNA segments that carry this genetic information are called genes, but other DNA sequences have structural purposes, or are involved in...
or mRNA sequences) is translated
Translation (genetics)
In molecular biology and genetics, translation is the third stage of protein biosynthesis . In translation, messenger RNA produced by transcription is decoded by the ribosome to produce a specific amino acid chain, or polypeptide, that will later fold into an active protein...
into protein
Protein
Proteins are biochemical compounds consisting of one or more polypeptides typically folded into a globular or fibrous form, facilitating a biological function. A polypeptide is a single linear polymer chain of amino acids bonded together by peptide bonds between the carboxyl and amino groups of...
s (amino acid
Amino acid
Amino acids are molecules containing an amine group, a carboxylic acid group and a side-chain that varies between different amino acids. The key elements of an amino acid are carbon, hydrogen, oxygen, and nitrogen...
sequences) by living cell
Cell (biology)
The cell is the basic structural and functional unit of all known living organisms. It is the smallest unit of life that is classified as a living thing, and is often called the building block of life. The Alberts text discusses how the "cellular building blocks" move to shape developing embryos....
s.
The code defines how sequences of three nucleotides, called codons, specify which amino acid will be added next during protein synthesis. With some exceptions, a three-nucleotide codon in a nucleic acid sequence specifies a single amino acid.