

Flashsort
Encyclopedia
Flashsort is a distribution sorting algorithm showing linear computational complexity 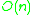 for uniformly distributed data sets and relatively little additional memory requirement. The original work was published in 1998 by Karl-Dietrich Neubert.
for uniformly distributed data sets and relatively little additional memory requirement. The original work was published in 1998 by Karl-Dietrich Neubert.
 , the class of an item
, the class of an item 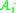 is computed as:
is computed as:
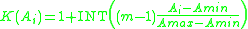
where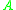 is the input set. The range covered by every class is equal, except the last class which includes only the maximum(s). The classification ensures that every element in a class is greater than any element in a lower class. This partially orders the data and reduces the number of inversions. Insertion sort is then applied to the classified set. As long as the data is uniformly distributed, class sizes will be consistent and insertion sort will be computationally efficient.
is the input set. The range covered by every class is equal, except the last class which includes only the maximum(s). The classification ensures that every element in a class is greater than any element in a lower class. This partially orders the data and reduces the number of inversions. Insertion sort is then applied to the classified set. As long as the data is uniformly distributed, class sizes will be consistent and insertion sort will be computationally efficient.
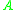 in an auxiliary vector
in an auxiliary vector 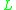 . These upper bounds are obtained by counting the number of elements in each class, and the upper bound of a class is the number of elements in that class and every class before it. These bounds serve as pointers into the classes.
. These upper bounds are obtained by counting the number of elements in each class, and the upper bound of a class is the number of elements in that class and every class before it. These bounds serve as pointers into the classes.
Classification is implemented through a series of cycles, where a cycle-leader is taken from the input array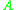 and its class is calculated. The pointers in vector
and its class is calculated. The pointers in vector 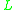 are used to insert the cycle-leader into the correct class, and the class’s pointer in
are used to insert the cycle-leader into the correct class, and the class’s pointer in 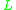 is decremented after each insertion. Inserting the cycle-leader will evict another element from array
is decremented after each insertion. Inserting the cycle-leader will evict another element from array 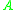 , which will be classified and inserted into another location and so on. The cycle terminates when an element is inserted into the cycle-leader’s starting location.
, which will be classified and inserted into another location and so on. The cycle terminates when an element is inserted into the cycle-leader’s starting location.
An element is a valid cycle-leader if it has not yet been classified. As the algorithm iterates on array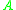 , previously classified elements are skipped and unclassified elements are used to initiate new cycles. It is possible to discern whether an element has been classified or not without using additional tags: An element has been classified if and only if its index is greater than the class’s pointer value in
, previously classified elements are skipped and unclassified elements are used to initiate new cycles. It is possible to discern whether an element has been classified or not without using additional tags: An element has been classified if and only if its index is greater than the class’s pointer value in 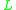 . To prove this, consider the current index of array
. To prove this, consider the current index of array 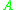 the algorithm is processing. Let this index be
the algorithm is processing. Let this index be 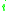 . Elements
. Elements 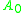 through
through 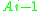 have already been classified and inserted into the correct class. Suppose that
have already been classified and inserted into the correct class. Suppose that 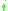 is greater than the current pointer to
is greater than the current pointer to 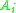 ’s class. Now suppose that the
’s class. Now suppose that the 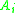 is unclassified and could be legally inserted into the index indicated by its class pointer, which would replace a classified element in another class. This is impossible since the initial pointers of each class are their upper bounds, which ensures that the exact needed amount of space is allocated for each class on the array
is unclassified and could be legally inserted into the index indicated by its class pointer, which would replace a classified element in another class. This is impossible since the initial pointers of each class are their upper bounds, which ensures that the exact needed amount of space is allocated for each class on the array 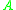 . Therefore, every element in
. Therefore, every element in 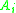 ’s class, including
’s class, including 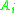 itself, has already been classified. Also, if an element has already been classified, the class’s pointer would have been decremented below the element’s new index.
itself, has already been classified. Also, if an element has already been classified, the class’s pointer would have been decremented below the element’s new index.
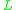 for storing class bounds and the constant number of other variables used.
for storing class bounds and the constant number of other variables used.
In the ideal case of a balanced data set, each class will be approximately the same size, and sorting an individual class by itself has complexity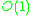 . If the number
. If the number  of classes is proportional to the input set size
of classes is proportional to the input set size  , the running time of the final insertion sort is
, the running time of the final insertion sort is 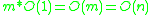 . In the worst-case scenarios where almost all the elements are in a few or one class, the complexity of the algorithm as a whole is limited by the performance of the final-step sorting method. For insertion sort, this is
. In the worst-case scenarios where almost all the elements are in a few or one class, the complexity of the algorithm as a whole is limited by the performance of the final-step sorting method. For insertion sort, this is 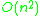 . Variations of the algorithm improve worst-case performance by using better-performing sorts such as quicksort or recursive flashsort on classes that exceed a certain size limit.
. Variations of the algorithm improve worst-case performance by using better-performing sorts such as quicksort or recursive flashsort on classes that exceed a certain size limit.
Choosing a value for , the number of classes, trades off time spent classifying elements (high
, the number of classes, trades off time spent classifying elements (high  ) and time spent in the final insertion sort step (low
) and time spent in the final insertion sort step (low  ). Based on his research, Neubert found
). Based on his research, Neubert found  to be optimal.
to be optimal.
Memory-wise, flashsort avoids the overhead needed to store classes in the very similar bucketsort. For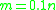 with uniform random data, flashsort is faster than heapsort for all
with uniform random data, flashsort is faster than heapsort for all  and faster than quicksort for
and faster than quicksort for 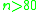 . It becomes about as twice as fast as quicksort at
. It becomes about as twice as fast as quicksort at 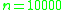 .
.
Due to the classification process, flashsort is not stable.
for uniformly distributed data sets and relatively little additional memory requirement. The original work was published in 1998 by Karl-Dietrich Neubert.Concept
The basic idea behind flashsort is that in a data set with a uniform distribution, it is easy to immediately estimate where an element should be placed after sorting when the range of the set is known. For example, if given a uniform data set where the minimum is 1 and the maximum is 100 and 50 is an element of the set, it’s reasonable to guess that 50 would be near the middle of the set after it is sorted. This approximate location is called a class. If numbered 1 to, the class of an item is computed as:where
is the input set. The range covered by every class is equal, except the last class which includes only the maximum(s). The classification ensures that every element in a class is greater than any element in a lower class. This partially orders the data and reduces the number of inversions. Insertion sort is then applied to the classified set. As long as the data is uniformly distributed, class sizes will be consistent and insertion sort will be computationally efficient.Memory efficient implementation
To execute flashsort with its low memory benefits, the algorithm does not use addition data structures to store the classes. Instead it stores the upper bounds of each class on the input array in an auxiliary vector . These upper bounds are obtained by counting the number of elements in each class, and the upper bound of a class is the number of elements in that class and every class before it. These bounds serve as pointers into the classes.Classification is implemented through a series of cycles, where a cycle-leader is taken from the input array
and its class is calculated. The pointers in vector are used to insert the cycle-leader into the correct class, and the class’s pointer in is decremented after each insertion. Inserting the cycle-leader will evict another element from array , which will be classified and inserted into another location and so on. The cycle terminates when an element is inserted into the cycle-leader’s starting location.An element is a valid cycle-leader if it has not yet been classified. As the algorithm iterates on array
, previously classified elements are skipped and unclassified elements are used to initiate new cycles. It is possible to discern whether an element has been classified or not without using additional tags: An element has been classified if and only if its index is greater than the class’s pointer value in . To prove this, consider the current index of array the algorithm is processing. Let this index be . Elements through have already been classified and inserted into the correct class. Suppose that is greater than the current pointer to ’s class. Now suppose that the is unclassified and could be legally inserted into the index indicated by its class pointer, which would replace a classified element in another class. This is impossible since the initial pointers of each class are their upper bounds, which ensures that the exact needed amount of space is allocated for each class on the array . Therefore, every element in ’s class, including itself, has already been classified. Also, if an element has already been classified, the class’s pointer would have been decremented below the element’s new index.Performance
The only extra memory requirements are the auxiliary vector for storing class bounds and the constant number of other variables used.In the ideal case of a balanced data set, each class will be approximately the same size, and sorting an individual class by itself has complexity
. If the number of classes is proportional to the input set size , the running time of the final insertion sort is . In the worst-case scenarios where almost all the elements are in a few or one class, the complexity of the algorithm as a whole is limited by the performance of the final-step sorting method. For insertion sort, this is . Variations of the algorithm improve worst-case performance by using better-performing sorts such as quicksort or recursive flashsort on classes that exceed a certain size limit.Choosing a value for
, the number of classes, trades off time spent classifying elements (high ) and time spent in the final insertion sort step (low ). Based on his research, Neubert found to be optimal.Memory-wise, flashsort avoids the overhead needed to store classes in the very similar bucketsort. For
with uniform random data, flashsort is faster than heapsort for all and faster than quicksort for . It becomes about as twice as fast as quicksort at .Due to the classification process, flashsort is not stable.