

Data synchronization
Encyclopedia
Data synchronization is the process of establishing consistency among data
from a source to a target data storage and vice versa and the continuous harmonization of the data over time. It is fundamental to a wide variety of applications, including file synchronization
and mobile device synchronization e.g. for PDAs
.
, version control (CVS
, Subversion, etc.), distributed filesystems (Coda
, etc.), and mirroring
(rsync
, etc.), in that all these attempt to keep sets of files synchronized. However, only version control and file synchronization tools can deal with modifications to more than one copy of the files.
Synchronization can also be useful in encryption
for synchronizing Public Key
Servers.
in information theory
. The models are classified based on how they consider the data to be synchronized.
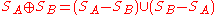 between two remote sets
between two remote sets 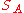
and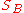 of b-bit numbers. Some solutions to this problem are typified by:
of b-bit numbers. Some solutions to this problem are typified by:
Wholesale transfer: In this case all data is transferred to one host for a local comparison.
Timestamp synchronization: In this case all changes to the data are marked with timestamps. Synchronization proceeds by transferring all data with a timestamp later than the previous synchronization.
Mathematical synchronization: In this case data are treated as mathematical objects and synchronization corresponds to a mathematical process.
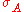 and
and 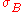 need to be reconcilied. Typically, it is assumed that these strings differ by up to a fixed number of edits (i.e. character insertions, deletions, or modifications). Then data synchronization is the process of reducing edit distance
need to be reconcilied. Typically, it is assumed that these strings differ by up to a fixed number of edits (i.e. character insertions, deletions, or modifications). Then data synchronization is the process of reducing edit distance
between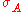 and
and 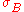 , up to the ideal distance of zero. This is applied in all filesystem based synchronizations (where the data is ordered). Many practical applications of this are discussed or referenced above.
, up to the ideal distance of zero. This is applied in all filesystem based synchronizations (where the data is ordered). Many practical applications of this are discussed or referenced above.
It is sometimes possible to transform the problem to one of unordered data through a process known as shingling (splitting the strings into shingles).
Data
The term data refers to qualitative or quantitative attributes of a variable or set of variables. Data are typically the results of measurements and can be the basis of graphs, images, or observations of a set of variables. Data are often viewed as the lowest level of abstraction from which...
from a source to a target data storage and vice versa and the continuous harmonization of the data over time. It is fundamental to a wide variety of applications, including file synchronization
File synchronization
File synchronization in computing is the process of ensuring that computer files in two or more locations are updated via certain rules....
and mobile device synchronization e.g. for PDAs
Personal digital assistant
A personal digital assistant , also known as a palmtop computer, or personal data assistant, is a mobile device that functions as a personal information manager. Current PDAs often have the ability to connect to the Internet...
.
File-based solutions
There are tools available for file synchronizationFile synchronization
File synchronization in computing is the process of ensuring that computer files in two or more locations are updated via certain rules....
, version control (CVS
Concurrent Versions System
The Concurrent Versions System , also known as the Concurrent Versioning System, is a client-server free software revision control system in the field of software development. Version control system software keeps track of all work and all changes in a set of files, and allows several developers ...
, Subversion, etc.), distributed filesystems (Coda
Coda (file system)
Coda is a distributed file system developed as a research project at Carnegie Mellon University since 1987 under the direction of Mahadev Satyanarayanan. It descended directly from an older version of AFS and offers many similar features. The InterMezzo file system was inspired by Coda...
, etc.), and mirroring
Mirror (computing)
In computing, a mirror is an exact copy of a data set. On the Internet, a mirror site is an exact copy of another Internet site.Mirror sites are most commonly used to provide multiple sources of the same information, and are of particular value as a way of providing reliable access to large downloads...
(rsync
Rsync
rsync is a software application and network protocol for Unix-like and Windows systems which synchronizes files and directories from one location to another while minimizing data transfer using delta encoding when appropriate. An important feature of rsync not found in most similar...
, etc.), in that all these attempt to keep sets of files synchronized. However, only version control and file synchronization tools can deal with modifications to more than one copy of the files.
- File synchronizationFile synchronizationFile synchronization in computing is the process of ensuring that computer files in two or more locations are updated via certain rules....
is commonly used for home backups on external hard drives or updating for transport on USB flash drives. The automatic process prevents copying already identical files and thus can save considerable time from a manual copy, also being faster and less error prone. - Version control tools are intended to deal with situations where more than one person wants to simultaneously modify the same file, while file synchronizers are optimized for situations where only one copy of the file will be edited at a time. For this reason, although version control tools can be used for file synchronization, dedicated programs require less overheadComputational overheadIn computer science, overhead is generally considered any combination of excess or indirect computation time, memory, bandwidth, or other resources that are required to attain a particular goal...
. - Distributed filesystems may also be seen as ensuring multiple versions of a file are synchronized. This normally requires that the devices storing the files are always connected, but some distributed file systems like CodaCoda (file system)Coda is a distributed file system developed as a research project at Carnegie Mellon University since 1987 under the direction of Mahadev Satyanarayanan. It descended directly from an older version of AFS and offers many similar features. The InterMezzo file system was inspired by Coda...
allow disconnected operation followed by reconciliation. The merging facilities of a distributed file system are typically more limited than those of a version control system because most file systems do not keep a version graph. - MirroringMirror (computing)In computing, a mirror is an exact copy of a data set. On the Internet, a mirror site is an exact copy of another Internet site.Mirror sites are most commonly used to provide multiple sources of the same information, and are of particular value as a way of providing reliable access to large downloads...
: A mirror is an exact copy of a data set. On the Internet, a mirror site is an exact copy of another Internet site. Mirror sites are most commonly used to provide multiple sources of the same information, and are of particular value as a way of providing reliable access to large downloads.
Synchronization can also be useful in encryption
Encryption
In cryptography, encryption is the process of transforming information using an algorithm to make it unreadable to anyone except those possessing special knowledge, usually referred to as a key. The result of the process is encrypted information...
for synchronizing Public Key
Public-key cryptography
Public-key cryptography refers to a cryptographic system requiring two separate keys, one to lock or encrypt the plaintext, and one to unlock or decrypt the cyphertext. Neither key will do both functions. One of these keys is published or public and the other is kept private...
Servers.
Theoretical models
Several theoretical models of data synchronization exist in the research literature, and the problem is also related to problem of Slepian-Wolf codingSlepian-Wolf coding
Slepian–Wolf coding is a method of coding using two compressed correlated sources....
in information theory
Information theory
Information theory is a branch of applied mathematics and electrical engineering involving the quantification of information. Information theory was developed by Claude E. Shannon to find fundamental limits on signal processing operations such as compressing data and on reliably storing and...
. The models are classified based on how they consider the data to be synchronized.
Unordered data
The problem of synchronizing unordered data (also known as the set reconciliation problem) is modeled as an attempt to compute the symmetric difference between two remote sets and
of b-bit numbers. Some solutions to this problem are typified by:Wholesale transfer: In this case all data is transferred to one host for a local comparison.
Timestamp synchronization: In this case all changes to the data are marked with timestamps. Synchronization proceeds by transferring all data with a timestamp later than the previous synchronization.
Mathematical synchronization: In this case data are treated as mathematical objects and synchronization corresponds to a mathematical process.
Ordered data
In this case, two remote strings and need to be reconcilied. Typically, it is assumed that these strings differ by up to a fixed number of edits (i.e. character insertions, deletions, or modifications). Then data synchronization is the process of reducing edit distanceEdit distance
In information theory and computer science, the edit distance between two strings of characters generally refers to the Levenshtein distance. However, according to Nico Jacobs, “The term ‘edit distance’ is sometimes used to refer to the distance in which insertions and deletions have equal cost and...
between
and , up to the ideal distance of zero. This is applied in all filesystem based synchronizations (where the data is ordered). Many practical applications of this are discussed or referenced above.It is sometimes possible to transform the problem to one of unordered data through a process known as shingling (splitting the strings into shingles).