

Consistent hashing
Encyclopedia
Consistent hashing is a special kind of hashing. In contrast, in most traditional hash tables, a change in the number of array slots causes nearly all keys to be remapped. By using consistent hashing, only 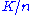 keys need to be remapped on average, where
keys need to be remapped on average, where  is the number of keys, and
is the number of keys, and  is the number of slots.
is the number of slots.
Consistent hashing could play an increasingly important role as internet use increases and as distributed systems grow more prevalent.
An academic paper from 1997 introduced the term "consistent hashing" as a way of distributing requests among a changing population of Web servers. Each slot is then represented by a node in a distributed system. The addition (joins) and removal (leaves/failures) of nodes only requires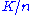 items to be re-shuffled when the number of slots/nodes change.
items to be re-shuffled when the number of slots/nodes change.
This same concept, however, appeared in 1996 within the Super Proxy Script technique created by SHARP for optimizing use by web browsers of multiple caching HTTP proxies.
Consistent hashing has also been used to reduce the impact of partial system failures in large Web applications as to allow for robust caches without incurring the system wide fallout of a failure.
The consistent hashing concept also applies to the design of distributed hash table
s (DHTs). DHTs use consistent hashing to partition a keyspace among a distributed set of nodes, and additionally provide an overlay network that connects nodes such that the node responsible for any key can be efficiently located.
 cache machines is to put object
cache machines is to put object  in cache machine number
in cache machine number 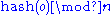 . But this will not work if a cache machine is added or removed because
. But this will not work if a cache machine is added or removed because  changes and every object is hashed to a new location. This can be disastrous since the originating content servers are flooded with requests from the cache machines. Hence consistent hashing is needed to avoid swamping of servers.
changes and every object is hashed to a new location. This can be disastrous since the originating content servers are flooded with requests from the cache machines. Hence consistent hashing is needed to avoid swamping of servers.
Consistent hashing maps objects to the same cache machine, as far as possible. It means when a cache machine is added, it takes its share of objects from all the other cache machines and when it is removed, its objects are shared between the remaining machines.
The main idea behind the consistent hashing algorithm is to hash both objects and caches using the same hash function. This is done to map the cache to an interval, which contains a number of object hashes. If the cache is removed its interval is taken over by a cache with an adjacent interval. All the remaining caches are unchanged.
Consistent hashing is based on mapping items to a real angle (or equivalently a point on the edge of a circle). Each of the available machines (or other storage buckets) is also pseudo-randomly mapped on to a series of angles around the circle. The bucket where each item should be stored is then chosen by selecting the next highest angle to which an available bucket maps to. The result is that each bucket contains the resources mapping to an angle between it and the next smallest angle.
If a bucket becomes unavailable (for example because the computer it resides on is not reachable), then the angles it maps to will be removed. Requests for resources that would have mapped to each of those points now map to the next highest point. Since each bucket is associated with many pseudo-randomly distributed points, the resources that were held by that bucket will now map to many different buckets. The items that mapped to the lost bucket must be redistributed among the remaining ones, but values mapping to other buckets will still do so and do not need to be moved.
A similar process occurs when a bucket is added. By adding an angle, we make any resources between that and the next smallest angle map to the new bucket. These resources will no longer be associated with the previous bucket, and any value previously stored there will not be found by the selection method described above.
The portion of the keys associated with each bucket can be altered by altering the number of angles that bucket maps to.
keys need to be remapped on average, where is the number of keys, and is the number of slots.Consistent hashing could play an increasingly important role as internet use increases and as distributed systems grow more prevalent.
History
Originally devised by Karger et. al. at MIT for use in distributed caching. The idea has now been expanded to other areas also.An academic paper from 1997 introduced the term "consistent hashing" as a way of distributing requests among a changing population of Web servers. Each slot is then represented by a node in a distributed system. The addition (joins) and removal (leaves/failures) of nodes only requires
items to be re-shuffled when the number of slots/nodes change.This same concept, however, appeared in 1996 within the Super Proxy Script technique created by SHARP for optimizing use by web browsers of multiple caching HTTP proxies.
Consistent hashing has also been used to reduce the impact of partial system failures in large Web applications as to allow for robust caches without incurring the system wide fallout of a failure.
The consistent hashing concept also applies to the design of distributed hash table
Distributed hash table
A distributed hash table is a class of a decentralized distributed system that provides a lookup service similar to a hash table; pairs are stored in a DHT, and any participating node can efficiently retrieve the value associated with a given key...
s (DHTs). DHTs use consistent hashing to partition a keyspace among a distributed set of nodes, and additionally provide an overlay network that connects nodes such that the node responsible for any key can be efficiently located.
Need for consistent hashing
While running collections of caching machines some limitations are experienced. A common way of load balancing cache machines is to put object in cache machine number . But this will not work if a cache machine is added or removed because changes and every object is hashed to a new location. This can be disastrous since the originating content servers are flooded with requests from the cache machines. Hence consistent hashing is needed to avoid swamping of servers.Consistent hashing maps objects to the same cache machine, as far as possible. It means when a cache machine is added, it takes its share of objects from all the other cache machines and when it is removed, its objects are shared between the remaining machines.
The main idea behind the consistent hashing algorithm is to hash both objects and caches using the same hash function. This is done to map the cache to an interval, which contains a number of object hashes. If the cache is removed its interval is taken over by a cache with an adjacent interval. All the remaining caches are unchanged.
Technique
Like most hashing schemes, consistent hashing assigns a set of items to buckets so that each bin receives almost same number of items.But unlike standard hashing schemes, a small change in buckets does not induce a total remapping of items to bucket.Consistent hashing is based on mapping items to a real angle (or equivalently a point on the edge of a circle). Each of the available machines (or other storage buckets) is also pseudo-randomly mapped on to a series of angles around the circle. The bucket where each item should be stored is then chosen by selecting the next highest angle to which an available bucket maps to. The result is that each bucket contains the resources mapping to an angle between it and the next smallest angle.
If a bucket becomes unavailable (for example because the computer it resides on is not reachable), then the angles it maps to will be removed. Requests for resources that would have mapped to each of those points now map to the next highest point. Since each bucket is associated with many pseudo-randomly distributed points, the resources that were held by that bucket will now map to many different buckets. The items that mapped to the lost bucket must be redistributed among the remaining ones, but values mapping to other buckets will still do so and do not need to be moved.
A similar process occurs when a bucket is added. By adding an angle, we make any resources between that and the next smallest angle map to the new bucket. These resources will no longer be associated with the previous bucket, and any value previously stored there will not be found by the selection method described above.
The portion of the keys associated with each bucket can be altered by altering the number of angles that bucket maps to.
Monotonic Keys
If it is known that key values will always increase monotonically, an alternative approach to consistent hashing is possible.Properties
Some properties of consistent hashing make it a different and more improved method than other standard hashing schemes. They are:- The 'Spread' property implies that even in the presence of inconsistent views of the world, the references given for a specific object are directed to only a small set of cache. Thus, all clients will be able to access data without using a lot of storage.
- The 'Load' property implies that any particular cache is not assigned an unreasonable number of objects.
- The 'Smoothness' property implies that smooth changes in the set of caching machines are matched by a smooth change in the location of the cache objects.
- The 'Balance' property implies that items are distributed to caches randomly.
- The 'Monotonic' property implies that when a bucket is added, only the items assigned to the new bucket are reassigned.