

Configural frequency analysis
Encyclopedia
Configural frequency analysis (CFA) (Lienert, 1969) is a method of exploratory data analysis
. The goal of a configural frequency analysis is to detect patterns in the data that occur significantly
more (such patterns are called Types) or significantly less often (such patterns are called Antitypes) than expected by chance. Thus, the idea of a CFA is to provide by the identified types and antitypes some insight into the structure of the data. Types are interpreted as concepts which are constituted by a pattern of variable values. Antitypes are interpreted as patterns of variable values that do in general not occur together.
Each record in the data set is thus an m-tuple (x1, ..., xm) where each xi is either equal to 0 (patient does not show symptom i) or 1 (patient does show symptom i).
Each such m-tuple is called a configuration. Let C be the set of all possible configurations, i.e. the set of all possible m-tuples on {0,1}m. The data set can thus be described by listing the observed frequencies f(c) of all possible configurations in C.
The basic idea of CFA is to estimate the frequency of each configuration under the assumption that the m symptoms are independent from the data. Let e(c) be this estimated frequency under the assumption of independence.
Let pi(1) be the probability that a member of the investigated population shows symptom si and pi(0) be the probability that a member of the investigated population does not show symptom si. Under the assumption that all symptoms are independent we can calculate the expected relative frequency of a configuration c = (c1 , ..., cm) by:
Now f(c) and e(c) can be compared by a statistical test (typical tests applied in CFA are the 2-test, the binomial test or the hypergeometric test of Lehmacher).
2-test, the binomial test or the hypergeometric test of Lehmacher).
If the statistical test suggests for a given -level that the difference between f(c) and e(c) is significant then c is called a type if f(c) > e(c) and is called an antitype if f(c) < e(c).
-level that the difference between f(c) and e(c) is significant then c is called a type if f(c) > e(c) and is called an antitype if f(c) < e(c).
If there is no significant difference between f(c) and e(c), then c is neither a type nor an antitype. Thus, each configuration c can have in principle three different states. It can be a type, an antitype, or not classified.
Types and antitypes are defined symmetrically. But in practical applications researchers are mainly interested to detect types. For example, clinical studies are typically interested to detect symptom combinations that are indicators for a disease. These are by definition symptom combinations which occur more often than expected by chance, i.e. types.
In most applications of CFA the assumption that all symptoms are independent is used as the chance model. A CFA using that chance model is called first-order CFA. This is the classical method of CFA that is in many publications even considered to be the only CFA method. An example of an alternative chance model is the assumption that all configurations have the same probability. A CFA using that chance model is called zero-order CFA.
Exploratory data analysis
In statistics, exploratory data analysis is an approach to analysing data sets to summarize their main characteristics in easy-to-understand form, often with visual graphs, without using a statistical model or having formulated a hypothesis...
. The goal of a configural frequency analysis is to detect patterns in the data that occur significantly
Statistical significance
In statistics, a result is called statistically significant if it is unlikely to have occurred by chance. The phrase test of significance was coined by Ronald Fisher....
more (such patterns are called Types) or significantly less often (such patterns are called Antitypes) than expected by chance. Thus, the idea of a CFA is to provide by the identified types and antitypes some insight into the structure of the data. Types are interpreted as concepts which are constituted by a pattern of variable values. Antitypes are interpreted as patterns of variable values that do in general not occur together.
Basic idea of the CFA algorithm
We explain the basic idea of CFA by a simple example. Assume that we have a data set that describes for each of n patients if they show certain symptoms s1, ..., sm. We assume for simplicity that a symptom is shown or not, i.e. we have a dichotomous data set.Each record in the data set is thus an m-tuple (x1, ..., xm) where each xi is either equal to 0 (patient does not show symptom i) or 1 (patient does show symptom i).
Each such m-tuple is called a configuration. Let C be the set of all possible configurations, i.e. the set of all possible m-tuples on {0,1}m. The data set can thus be described by listing the observed frequencies f(c) of all possible configurations in C.
The basic idea of CFA is to estimate the frequency of each configuration under the assumption that the m symptoms are independent from the data. Let e(c) be this estimated frequency under the assumption of independence.
Let pi(1) be the probability that a member of the investigated population shows symptom si and pi(0) be the probability that a member of the investigated population does not show symptom si. Under the assumption that all symptoms are independent we can calculate the expected relative frequency of a configuration c = (c1 , ..., cm) by:
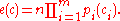
Now f(c) and e(c) can be compared by a statistical test (typical tests applied in CFA are the
2-test, the binomial test or the hypergeometric test of Lehmacher).If the statistical test suggests for a given
-level that the difference between f(c) and e(c) is significant then c is called a type if f(c) > e(c) and is called an antitype if f(c) < e(c).If there is no significant difference between f(c) and e(c), then c is neither a type nor an antitype. Thus, each configuration c can have in principle three different states. It can be a type, an antitype, or not classified.
Types and antitypes are defined symmetrically. But in practical applications researchers are mainly interested to detect types. For example, clinical studies are typically interested to detect symptom combinations that are indicators for a disease. These are by definition symptom combinations which occur more often than expected by chance, i.e. types.
Control of the alpha level
Since in CFA a significance test is applied in parallel for each configuration c there is a high risk to commit a type I error (i.e. to detect a type or antitype when the null hypothesis is true). The currently most popular method to control this is to use the Bonferroni-adjustment for the α-level (see, for example, Krauth & Lienert, 1973). There are a number of alternative methods to control the α-level. One alternative (Holm, 1979) considers the number of tests already finished when the ith test is performed. Thus, in this method the alpha–level is not constant for all tests.Algorithm in the non-dichotomous case
In our example above we assumed for simplicity that the symptoms are dichotomous. This is however not a necessary restriction. CFA can also be applied for symptoms (or more general attributes of an object) that are not dichotomous but have a finite number of degrees. In this case a configuration is an element of C = S1 x ... x Sm, where Si is the set of the possible degrees for symptom si. For a description of the general CFA algorithm see the introductions into CFA by Krauth and Lienert (1973), von Eye (1990), Lautsch and Weber (1990), or Krauth (1993).Chance model
The assumption of the independence of the symptoms can be replaced by another method to calculate the expected frequencies e(c) of the configurations. Such a method is called a chance model.In most applications of CFA the assumption that all symptoms are independent is used as the chance model. A CFA using that chance model is called first-order CFA. This is the classical method of CFA that is in many publications even considered to be the only CFA method. An example of an alternative chance model is the assumption that all configurations have the same probability. A CFA using that chance model is called zero-order CFA.