CUDA or Compute Unified Device Architecture is a parallel computing architecture developed by Nvidia
NVIDIA
Nvidia is an American global technology company based in Santa Clara, California. Nvidia is best known for its graphics processors . Nvidia and chief rival AMD Graphics Techonologies have dominated the high performance GPU market, pushing other manufacturers to smaller, niche roles...
A graphics processing unit or GPU is a specialized circuit designed to rapidly manipulate and alter memory in such a way so as to accelerate the building of images in a frame buffer intended for output to a display...
s (GPUs) that is accessible to software developers through variants of industry standard programming languages. Programmers use 'C for CUDA' (C with Nvidia extensions and certain restrictions), compiled through a PathScale Open64
Open64
Open64 is an open source, optimizing compiler for the Itanium and x86-64 microprocessor architectures. It derives from the SGI compilers for the MIPS R10000 processor, called MIPSPro. It was initially released in 2000 as GNU GPL software under the name Pro64. The following year, University of...
C is a general-purpose computer programming language developed between 1969 and 1973 by Dennis Ritchie at the Bell Telephone Laboratories for use with the Unix operating system....
compiler, to code algorithms for execution on the GPU. CUDA architecture shares a range of computational interfaces with two competitors -the Khronos Group
Khronos Group
The Khronos Group is a not-for-profit member-funded industry consortium based in Beaverton, Oregon, focused on the creation of open standard, royalty-free APIs to enable the authoring and accelerated playback of dynamic media on a wide variety of platforms and devices...
OpenCL is a framework for writing programs that execute across heterogeneous platforms consisting of CPUs, GPUs, and other processors. OpenCL includes a language for writing kernels , plus APIs that are used to define and then control the platforms...
Microsoft DirectCompute is an application programming interface that supports general-purpose computing on graphics processing units on Microsoft Windows Vista and Windows 7. DirectCompute is part of the Microsoft DirectX collection of APIs and was initially released with the DirectX 11 API but...
. Third party wrappers are also available for Python
Python (programming language)
Python is a general-purpose, high-level programming language whose design philosophy emphasizes code readability. Python claims to "[combine] remarkable power with very clear syntax", and its standard library is large and comprehensive...
Perl is a high-level, general-purpose, interpreted, dynamic programming language. Perl was originally developed by Larry Wall in 1987 as a general-purpose Unix scripting language to make report processing easier. Since then, it has undergone many changes and revisions and become widely popular...
Java is a programming language originally developed by James Gosling at Sun Microsystems and released in 1995 as a core component of Sun Microsystems' Java platform. The language derives much of its syntax from C and C++ but has a simpler object model and fewer low-level facilities...
Ruby is a dynamic, reflective, general-purpose object-oriented programming language that combines syntax inspired by Perl with Smalltalk-like features. Ruby originated in Japan during the mid-1990s and was first developed and designed by Yukihiro "Matz" Matsumoto...
MATLAB is a numerical computing environment and fourth-generation programming language. Developed by MathWorks, MATLAB allows matrix manipulations, plotting of functions and data, implementation of algorithms, creation of user interfaces, and interfacing with programs written in other languages,...
, and IDL, and native support exists in Mathematica
Mathematica
Mathematica is a computational software program used in scientific, engineering, and mathematical fields and other areas of technical computing...
.
CUDA gives developers access to the virtual instruction set and memory of the parallel computational
Parallel computing
Parallel computing is a form of computation in which many calculations are carried out simultaneously, operating on the principle that large problems can often be divided into smaller ones, which are then solved concurrently . There are several different forms of parallel computing: bit-level,...
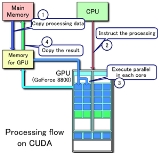
elements in CUDA GPUs. Using CUDA, the latest Nvidia GPUs become accessible for computation like CPUs. Unlike CPUs however, GPUs have a parallel throughput architecture that emphasizes executing many concurrent threads slowly, rather than executing a single thread very quickly. This approach of solving general purpose problems on GPUs is known as GPGPU
GPGPU
General-purpose computing on graphics processing units is the technique of using a GPU, which typically handles computation only for computer graphics, to perform computation in applications traditionally handled by the CPU...
.
In the computer game industry, in addition to graphics rendering, GPUs are used in game physics calculations
Physics processing unit
A physics processing unit is a dedicated microprocessor designed to handle the calculations of physics, especially in the physics engine of video games. Examples of calculations involving a PPU might include rigid body dynamics, soft body dynamics, collision detection, fluid dynamics, hair and...
(physical effects like debris, smoke, fire, fluids); examples include PhysX
PhysX
PhysX is a proprietary realtime physics engine middleware SDK developed by Ageia with the purchase of ETH Zurich spin-off NovodeX in 2004...
Bullet is an open source physics engine featuring 3D collision detection, soft body dynamics, and rigid body dynamics. It is used in games, and in visual effects in movies. The Bullet physics library is published under the zlib license. Erwin Coumans, its main author, worked for Sony Computer...
. CUDA has also been used to accelerate non-graphical applications in computational biology
Computational biology
Computational biology involves the development and application of data-analytical and theoretical methods, mathematical modeling and computational simulation techniques to the study of biological, behavioral, and social systems...
An order of magnitude is the class of scale or magnitude of any amount, where each class contains values of a fixed ratio to the class preceding it. In its most common usage, the amount being scaled is 10 and the scale is the exponent being applied to this amount...
Berkeley Open Infrastructure for Network Computing
The Berkeley Open Infrastructure for Network Computing is an open source middleware system for volunteer and grid computing. It was originally developed to support the SETI@home project before it became useful as a platform for other distributed applications in areas as diverse as mathematics,...
Distributed computing is a field of computer science that studies distributed systems. A distributed system consists of multiple autonomous computers that communicate through a computer network. The computers interact with each other in order to achieve a common goal...
client.
CUDA provides both a low level API and a higher level API. The initial CUDA SDK was made public on 15 February 2007, for Microsoft Windows
Microsoft Windows
Microsoft Windows is a series of operating systems produced by Microsoft.Microsoft introduced an operating environment named Windows on November 20, 1985 as an add-on to MS-DOS in response to the growing interest in graphical user interfaces . Microsoft Windows came to dominate the world's personal...
Linux is a Unix-like computer operating system assembled under the model of free and open source software development and distribution. The defining component of any Linux system is the Linux kernel, an operating system kernel first released October 5, 1991 by Linus Torvalds...
Mac OS X is a series of Unix-based operating systems and graphical user interfaces developed, marketed, and sold by Apple Inc. Since 2002, has been included with all new Macintosh computer systems...
support was later added in version 2.0, which supersedes the beta released February 14, 2008.
CUDA works with all Nvidia GPUs from the G8x series onwards, including GeForce, Quadro
NVIDIA Quadro
The Nvidia Quadro series of AGP, PCI, and PCI Express graphics cards comes from the NVIDIA Corporation. Their designers aimed to accelerate CAD and DCC , and the cards are usually featured in workstations....
The Tesla graphics processing unit is nVidia's third brand of GPUs. It is based on high-end GPUs from the G80 , as well as the Quadro lineup. Tesla is nVidia's first dedicated General Purpose GPU...
line. CUDA is compatible with most standard operating systems. Nvidia states that programs developed for the G8x series will also work without modification on all future Nvidia video cards, due to binary compatibility.
Background
The GPU, as a specialized processor, addresses the demands of real-time
Real-time computer graphics
Real-time computer graphics is the subfield of computer graphics focused on producing and analyzing images in real time. The term is most often used in reference to interactive 3D computer graphics, typically using a GPU, with video games the most noticeable users...
high-resolution 3D graphics compute-intensive tasks. GPUs have evolved into highly parallel multi core systems allowing very efficient manipulation of large blocks of data. This design is more effective than general-purpose CPUs
Central processing unit
The central processing unit is the portion of a computer system that carries out the instructions of a computer program, to perform the basic arithmetical, logical, and input/output operations of the system. The CPU plays a role somewhat analogous to the brain in the computer. The term has been in...
In mathematics and computer science, an algorithm is an effective method expressed as a finite list of well-defined instructions for calculating a function. Algorithms are used for calculation, data processing, and automated reasoning...
s where processing of large blocks of data is done in parallel, such as:
The Fast Wavelet Transform is a mathematical algorithm designed to turn a waveform or signal in the time domain into a sequence of coefficients based on an orthogonal basis of small finite waves, or wavelets...
Molecular dynamics is a computer simulation of physical movements of atoms and molecules. The atoms and molecules are allowed to interact for a period of time, giving a view of the motion of the atoms...
simulations is suitable for CUDA implementation.
Advantages
CUDA has several advantages over traditional general-purpose computation on GPUs (GPGPU) using graphics APIs:
Scattered reads – code can read from arbitrary addresses in memory
In computing, shared memory is memory that may be simultaneously accessed by multiple programs with an intent to provide communication among them or avoid redundant copies. Depending on context, programs may run on a single processor or on multiple separate processors...
Scratchpad memory , also known as scratchpad, scatchpad RAM or local store in computer terminology, is a high-speed internal memory used for temporary storage of calculations, data, and other work in progress...
region (up to 48KB per Multi-Processor) that can be shared amongst threads. This can be used as a user-managed cache, enabling higher bandwidth than is possible using texture lookups.
Faster downloads and readbacks to and from the GPU
Full support for integer and bitwise operations, including integer texture lookups
Limitations
Texture rendering is not supported (CUDA 3.2 and up addresses this by introducing "surface writes" to cuda Arrays, the underlying opaque data structure).
Copying between host and device memory may incur a performance hit due to system bus bandwidth and latency (this can be partly alleviated with asynchronous memory transfers, handled by the GPU's DMA engine)
Threads should be running in groups of at least 32 for best performance, with total number of threads numbering in the thousands. Branches in the program code do not impact performance significantly, provided that each of 32 threads takes the same execution path; the SIMD
SIMD
Single instruction, multiple data , is a class of parallel computers in Flynn's taxonomy. It describes computers with multiple processing elements that perform the same operation on multiple data simultaneously...
execution model becomes a significant limitation for any inherently divergent task (e.g. traversing a space partitioning
Space partitioning
In mathematics, space partitioning is the process of dividing a space into two or more disjoint subsets . In other words, space partitioning divides a space into non-overlapping regions...
OpenCL is a framework for writing programs that execute across heterogeneous platforms consisting of CPUs, GPUs, and other processors. OpenCL includes a language for writing kernels , plus APIs that are used to define and then control the platforms...
, CUDA-enabled GPUs are only available from Nvidia
Valid C/C++ may sometimes be flagged and prevent compilation due to optimization techniques the compiler is required to employ to use limited resources.
CUDA (with compute capability 1.x) uses a recursion-free, function-pointer-free subset of the C language, plus some simple extensions. However, a single process must run spread across multiple disjoint memory spaces, unlike other C language runtime environments.
CUDA (with compute capability 2.x) allows a subset of C++ class functionality, for example member functions may not be virtual (this restriction will be removed in some future release). [See CUDA C Programming Guide 3.1 - Appendix D.6]
Double precision (CUDA compute capability 1.3 and above) deviate from the IEEE 754 standard: round-to-nearest-even is the only supported rounding mode for reciprocal, division, and square root. In single precision
Single precision floating-point format
Single-precision floating-point format is a computer number format that occupies 4 bytes in computer memory and represents a wide dynamic range of values by using a floating point....
In computer science, denormal numbers or denormalized numbers fill the underflow gap around zero in floating point arithmetic: any non-zero number which is smaller than the smallest normal number is 'sub-normal'.For example, if the smallest positive 'normal' number is 1×β−n In computer...
Rounding a numerical value means replacing it by another value that is approximately equal but has a shorter, simpler, or more explicit representation; for example, replacing $23.4476 with $23.45, or the fraction 312/937 with 1/3, or the expression √2 with 1.414.Rounding is often done on purpose to...
modes are supported (chop and round-to-nearest even), and those are specified on a per-instruction basis rather than in a control word; and the precision of division/square root is slightly lower than single precision.
Supported GPUs
Compute capability table (version of CUDA supported) by GPU and card. Also available directly from Nvidia
A table of devices officially supporting CUDA (Note that many applications require at least 256 MB of dedicated VRAM, and some recommend at least 96 cuda cores).
see full list here: http://developer.nvidia.com/cuda-gpus
GeForce is a brand of graphics processing units designed by Nvidia. , there have been eleven iterations of the design. The first GeForce products were discrete GPUs designed for use on add-on graphics boards, intended for the high-margin PC gaming market...
GeForce is a brand of graphics processing units designed by Nvidia. , there have been eleven iterations of the design. The first GeForce products were discrete GPUs designed for use on add-on graphics boards, intended for the high-margin PC gaming market...
The Nvidia Quadro series of AGP, PCI, and PCI Express graphics cards comes from the NVIDIA Corporation. Their designers aimed to accelerate CAD and DCC , and the cards are usually featured in workstations....
|-
|Quadro 6000
|-
|Quadro 5000
|-
|Quadro 4000
|-
|Quadro 2000
|-
|Quadro 600
|-
|Quadro FX 5800
|-
|Quadro FX 5600
|-
|Quadro FX 4800
|-
|Quadro FX 4700 X2
|-
|Quadro FX 4600
|-
|Quadro FX 3800
|-
|Quadro FX 3700
|-
|Quadro FX 1800
|-
|Quadro FX 1700
|-
|Quadro FX 580
|-
|Quadro FX 570
|-
|Quadro FX 380
|-
|Quadro FX 370
|-
|Quadro NVS 450
|-
|Quadro NVS 420
|-
|Quadro NVS 295
|-
|Quadro NVS 290
|-
|Quadro Plex 1000 Model IV
|-
|Quadro Plex 1000 Model S4
|}
{| class="standard"
!Nvidia Quadro Mobile
NVIDIA Quadro
The Nvidia Quadro series of AGP, PCI, and PCI Express graphics cards comes from the NVIDIA Corporation. Their designers aimed to accelerate CAD and DCC , and the cards are usually featured in workstations....
|-
|Quadro 5010M
|-
|Quadro 5000M
|-
|Quadro 4000M
|-
|Quadro 3000M
|-
|Quadro 2000M
|-
|Quadro 1000M
|-
|Quadro FX 3800M
|-
|Quadro FX 3700M
|-
|Quadro FX 3600M
|-
|Quadro FX 2800M
|-
|Quadro FX 2700M
|-
|Quadro FX 1800M
|-
|Quadro FX 1700M
|-
|Quadro FX 1600M
|-
|Quadro FX 880M
|-
|Quadro FX 770M
|-
|Quadro FX 570M
|-
|Quadro FX 380M
|-
|Quadro FX 370M
|-
|Quadro FX 360M
|-
|Quadro NVS 320M
|-
|Quadro NVS 160M
|-
|Quadro NVS 150M
|-
|Quadro NVS 140M
|-
|Quadro NVS 135M
|-
|Quadro NVS 130M
|}
{| class="standard"
!Nvidia Tesla
Nvidia Tesla
The Tesla graphics processing unit is nVidia's third brand of GPUs. It is based on high-end GPUs from the G80 , as well as the Quadro lineup. Tesla is nVidia's first dedicated General Purpose GPU...
Maximum x-, y-, or z-dimension of a grid of thread blocks
colspan="5"
Maximum dimensionality of thread block
colspan="5"
Maximum x- or y-dimension of a block
colspan="4"
Maximum z-dimension of a block
colspan="5"
Maximum number of threads per block
colspan="4"
Warp size
colspan="5"
Maximum number of resident blocks per multiprocessor
colspan="5"
Maximum number of resident warps per multiprocessor
colspan="2"
colspan="2"
Maximum number of resident threads per multiprocessor
colspan="2"
colspan="2"
Number of 32-bit registers per multiprocessor
colspan="2"
colspan="2"
Maximum amount of shared memory per multiprocessor
colspan="4"
Number of shared memory banks
colspan="4"
Amount of local memory per thread
colspan="4"
Constant memory size
colspan="5"
Cache working set per multiprocessor for constant memory
colspan="5"
Cache working set per multiprocessor for texture memory
colspan="5"
Maximum width for 1D texture reference bound to a CUDA array
colspan="4"
Maximum width for 1D texture reference bound to linear memory
colspan="5"
Maximum width and number of layers for a 1D layered texture reference
colspan="4"
Maximum width and height for 2D texture reference bound to linear memory or a CUDA array
colspan="4"
colspan="1"
Maximum width, height, and number of layers for a 2D layered texture reference
colspan="4"
Maximum width, height and depth for a 3D texture reference bound to linear memory or a CUDA array
colspan="5"
Maximum number of textures that can be bound to a kernel
colspan="5"
Maximum width for a 1D surface reference bound to a CUDA array
colspan="4" rowspan="3"
Maximum width and height for a 2D surface reference bound to a CUDA array
Maximum number of surfaces that can be bound to a kernel
Maximum number of instructions per kernel
colspan="5"
Architecture specifications
Compute capability (version)
1.0
1.1
1.2
1.3
2.0
2.1
Number of cores for integer and floating-point arithmetic functions operations
colspan="4"
colspan="1"
colspan="1"
Number of special function units for single-precision floating-point transcendental functions
colspan="4"
colspan="1"
colspan="1"
Number of texture filtering units for every texture address unit or Render Output Unit (ROP)
colspan="4"
colspan="1"
colspan="1"
Number of warp schedulers
colspan="4"
colspan="1"
colspan="1"
Number of instructions issued at once by scheduler
colspan="4"
colspan="1"
colspan="1"
For more information please visit this site: http://www.geeks3d.com/20100606/gpu-computing-nvidia-cuda-compute-capability-comparative-table/ and also read Nvidia CUDA programming guide.
Example
This example code in C++ loads a texture from an image into an array on the GPU:
texture tex;
// Unbind the array from the texture
cudaUnbindTexture(tex);
} //end foo
__global__ void kernel(float* odata, int height, int width)
{
unsigned int x = blockIdx.x*blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y*blockDim.y + threadIdx.y;
if (x < width && y < height) {
float c = tex2D(tex, x, y);
odata[y*width+x] = c;
}
}
Below is an example given in Python that computes the product of two arrays on the GPU. The unofficial Python language bindings can be obtained from PyCUDA.
import pycuda.compiler as comp
import pycuda.driver as drv
import numpy
import pycuda.autoinit
mod = comp.SourceModule("""
__global__ void multiply_them(float *dest, float *a, float *b)
{
const int i = threadIdx.x;
dest[i] = a[i] * b[i];
}
""")
multiply_them = mod.get_function("multiply_them")
a = numpy.random.randn(400).astype(numpy.float32)
b = numpy.random.randn(400).astype(numpy.float32)
dest = numpy.zeros_like(a)
multiply_them(
drv.Out(dest), drv.In(a), drv.In(b),
block=(400,1,1))
print dest-a*b
Additional Python bindings to simplify matrix multiplication operations can be found in the program pycublas.
import numpy
from pycublas import CUBLASMatrix
A = CUBLASMatrix( numpy.mat(1,2,3],[4,5,6,numpy.float32) )
B = CUBLASMatrix( numpy.mat(2,3],[4,5],[6,7,numpy.float32) )
C = A*B
print C.np_mat
MATLAB is a numerical computing environment and fourth-generation programming language. Developed by MathWorks, MATLAB allows matrix manipulations, plotting of functions and data, implementation of algorithms, creation of user interfaces, and interfacing with programs written in other languages,...
- Parallel Computing Toolbox, Distributed Computing Server, and 3rd party packages like Jacket
Jacket (software)
Jacket is a numerical computing platform enabling GPU acceleration of MATLAB-based codes. Developed by AccelerEyes, Jacket allows GPU-based matrix manipulations, plotting of functions and data, implementation of algorithms, and interfacing with programs written in other languages, including C, C++,...
The .NET Framework is a software framework that runs primarily on Microsoft Windows. It includes a large library and supports several programming languages which allows language interoperability...
Perl is a high-level, general-purpose, interpreted, dynamic programming language. Perl was originally developed by Larry Wall in 1987 as a general-purpose Unix scripting language to make report processing easier. Since then, it has undergone many changes and revisions and become widely popular...
Python is a general-purpose, high-level programming language whose design philosophy emphasizes code readability. Python claims to "[combine] remarkable power with very clear syntax", and its standard library is large and comprehensive...
Ruby is a dynamic, reflective, general-purpose object-oriented programming language that combines syntax inspired by Perl with Smalltalk-like features. Ruby originated in Japan during the mid-1990s and was first developed and designed by Yukihiro "Matz" Matsumoto...
Java is a programming language originally developed by James Gosling at Sun Microsystems and released in 1995 as a core component of Sun Microsystems' Java platform. The language derives much of its syntax from C and C++ but has a simpler object model and fewer low-level facilities...
Haskell is a standardized, general-purpose purely functional programming language, with non-strict semantics and strong static typing. It is named after logician Haskell Curry. In Haskell, "a function is a first-class citizen" of the programming language. As a functional programming language, the...
The .NET Framework is a software framework that runs primarily on Microsoft Windows. It includes a large library and supports several programming languages which allows language interoperability...
- CUDAfy.NET .NET kernel and host code, CURAND, CUBLAS, CUFFT.
Current CUDA architectures
The current generation CUDA architecture (codename: "Fermi") which is standard on Nvidia's released (GeForce 400 Series
GeForce 400 Series
The GeForce 400 Series is the 11th generation of Nvidia's GeForce graphics processing units. The series was originally slated for production in November 2009, but, after a number of delays, launched on March 26, 2010 with availability following in April 2010....
[GF100] (GPU) 2010-03-27) GPU is designed from the ground up to natively support more programming languages such as C++
C++
C++ is a statically typed, free-form, multi-paradigm, compiled, general-purpose programming language. It is regarded as an intermediate-level language, as it comprises a combination of both high-level and low-level language features. It was developed by Bjarne Stroustrup starting in 1979 at Bell...
. It has eight times the peak double-precision floating-point performance compared to Nvidia's previous-generation Tesla
Nvidia Tesla
The Tesla graphics processing unit is nVidia's third brand of GPUs. It is based on high-end GPUs from the G80 , as well as the Quadro lineup. Tesla is nVidia's first dedicated General Purpose GPU...
GPU. It also introduced several new features including:
up to 1024 CUDA cores and 3.0 billion transistors on the GTX 590
In cryptography, encryption is the process of transforming information using an algorithm to make it unreadable to anyone except those possessing special knowledge, usually referred to as a key. The result of the process is encrypted information...
In computer science and information theory, data compression, source coding or bit-rate reduction is the process of encoding information using fewer bits than the original representation would use....
Distributed Calculations, such as predicting the native conformation of proteins
Virtual reality , also known as virtuality, is a term that applies to computer-simulated environments that can simulate physical presence in places in the real world, as well as in imaginary worlds...
Magnetic resonance imaging , nuclear magnetic resonance imaging , or magnetic resonance tomography is a medical imaging technique used in radiology to visualize detailed internal structures...
In physics, fluid dynamics is a sub-discipline of fluid mechanics that deals with fluid flow—the natural science of fluids in motion. It has several subdisciplines itself, including aerodynamics and hydrodynamics...
The GeForce 8 Series, is the eighth generation of NVIDIA's GeForce line of graphics processing units. The third major GPU architecture developed at NVIDIA, the GeForce 8 represents the company's first unified shader architecture.-Naming:...
The GeForce 9 Series is the ninth generation of NVIDIA's GeForce series of graphics processing units, the first of which was released on February 21, 2008.-Geforce 9300GE :*65nm G98 GPU*PCI-E x16*64 Bit Bus Width*4 ROP, 8 Unified Shaders...
The GeForce 200 Series is the 10th generation of Nvidia's GeForce graphics processing units. The series also represents the continuation of the company's unified shader architecture introduced with the GeForce 8 Series and the GeForce 9 Series. Its primary competition came from ATI's Radeon HD 4000...
The GeForce 400 Series is the 11th generation of Nvidia's GeForce graphics processing units. The series was originally slated for production in November 2009, but, after a number of delays, launched on March 26, 2010 with availability following in April 2010....
The GeForce 500 Series is a family of graphics processing units developed by Nvidia, based on the refreshed Fermi architecture. Nvidia officially announced the GeForce 500 series on 9 November 2010 with the launch of the GeForce GTX 580.- Overview :...
The Nvidia Quadro series of AGP, PCI, and PCI Express graphics cards comes from the NVIDIA Corporation. Their designers aimed to accelerate CAD and DCC , and the cards are usually featured in workstations....
The Tesla graphics processing unit is nVidia's third brand of GPUs. It is based on high-end GPUs from the G80 , as well as the Quadro lineup. Tesla is nVidia's first dedicated General Purpose GPU...
- Nvidia's first dedicated general purpose GPU (graphics processing unit)
General-purpose computing on graphics processing units is the technique of using a GPU, which typically handles computation only for computer graphics, to perform computation in applications traditionally handled by the CPU...
OpenCL is a framework for writing programs that execute across heterogeneous platforms consisting of CPUs, GPUs, and other processors. OpenCL includes a language for writing kernels , plus APIs that are used to define and then control the platforms...
- The cross-platform standard supported by both NVidia and AMD/ATI
Microsoft DirectCompute is an application programming interface that supports general-purpose computing on graphics processing units on Microsoft Windows Vista and Windows 7. DirectCompute is part of the Microsoft DirectX collection of APIs and was initially released with the DirectX 11 API but...
- Microsoft API for GPU Computing in Windows Vista and Windows 7
BrookGPU is the Stanford University graphics group's compiler and runtime implementation of the Brook stream programming language for using modern graphics hardware for non-graphical, general purpose computations...
Sh is a metaprogramming language for programmable GPUs. Programmable GPUs are graphics processing units that execute some operations with higher efficiency than CPUs...
A graphics processing unit or GPU is a specialized circuit designed to rapidly manipulate and alter memory in such a way so as to accelerate the building of images in a frame buffer intended for output to a display...
Stream processing is a computer programming paradigm, related to SIMD , that allows some applications to more easily exploit a limited form of parallel processing...
In the field of computer graphics, a shader is a computer program that is used primarily to calculate rendering effects on graphics hardware with a high degree of flexibility...
Molecular modeling on GPU is the technique of using a graphics processing unit for molecular simulations.In 2007, NVIDIA introduced video cards that could be used not only to show graphics but also for scientific calculations. These cards include many arithmetic units working in parallel...
The AMD FireStream is a stream processor produced by Advanced Micro Devices to utilize the stream processing/GPGPU concept for heavy floating-point computations to target various industries, such as the High Performance Computing , scientific, and financial sectors...
rCUDA is a middleware that enables Computer Unified Device Architecture CUDA remoting over a commodity network. That is, the middleware allows an application to use a CUDA-compatible graphics processing unit installed in a remote computer as if it were installed in the computer where the...
Charles Peete "Charlie" Rose, Jr. is an American television talk show host and journalist. Since 1991 he has hosted Charlie Rose, an interview show distributed nationally by PBS since 1993...
Wen-mei Hwu is a professor at University of Illinois at Urbana-Champaign specializing in compiler design, computer architecture, computer microarchitecture, and parallel processing. He currently holds the Walter J. Sanders III-Advanced Micro Devices Endowed Chair in Electrical and Computer...
Dr David Kirk Ph.D. is Nvidia's Chief Scientist.From June 1996 to January 1997, Dr. Kirk was a software and technical management consultant. From 1993 to 1996, Dr. Kirk was Chief Scientist and Head of Technology for Crystal Dynamics, a video game manufacturing company.From 1989 to 1991, Dr. Kirk...
Molecular dynamics is a computer simulation of physical movements of atoms and molecules. The atoms and molecules are allowed to interact for a period of time, giving a view of the motion of the atoms...
Parallel Computing Center Parallel Computing, using GPU. Creating and porting various application (jCUDA, CUDA C++). Ukraine, Khmelnitskiy National University.
The source of this article is wikipedia, the free encyclopedia. The text of this article is licensed under the GFDL.

.png)