

Bigram
Encyclopedia
Bigrams or digrams are groups of two written letters, two syllables, or two words, and are very commonly used as the basis for simple statistical analysis of text. They are used in one of the most successful language model
s for speech recognition
. They are a special case of N-gram
.
Gappy bigrams or skipping bigrams are word pairs which allow gaps (perhaps avoiding connecting words, or allowing some simulation of dependencies, as in a dependency grammar
).
Head word bigrams are gappy bigrams with an explicit dependency relationship.
The term is also used in cryptography
, where bigram frequency attacks have sometimes been used to attempt to solve cryptograms. See frequency analysis.
Bigrams help provide the conditional probability of a word given the preceding word, when the relation of the conditional probability
is applied:
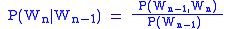
That is, the probability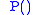 of a word
of a word  given the preceding word
given the preceding word 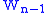 is equal to the probability of their bigram, or the co-occurrence of the two words
is equal to the probability of their bigram, or the co-occurrence of the two words 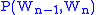 , divided by the probability of the preceding word.
, divided by the probability of the preceding word.
th 1.52% en 0.55% ng 0.18%
he 1.28% ed 0.53% of 0.16%
in 0.94% to 0.52% al 0.09%
er 0.94% it 0.50% de 0.09%
an 0.82% ou 0.50% se 0.08%
re 0.68% ea 0.47% le 0.08%
nd 0.63% hi 0.46% sa 0.06%
at 0.59% is 0.46% si 0.05%
on 0.57% or 0.43% ar 0.04%
nt 0.56% ti 0.34% ve 0.04%
ha 0.56% as 0.33% ra 0.04%
es 0.56% te 0.27% ld 0.02%
st 0.55% et 0.19% ur 0.02%
Language model
A statistical language model assigns a probability to a sequence of m words P by means of a probability distribution.Language modeling is used in many natural language processing applications such as speech recognition, machine translation, part-of-speech tagging, parsing and information...
s for speech recognition
Speech recognition
Speech recognition converts spoken words to text. The term "voice recognition" is sometimes used to refer to recognition systems that must be trained to a particular speaker—as is the case for most desktop recognition software...
. They are a special case of N-gram
N-gram
In the fields of computational linguistics and probability, an n-gram is a contiguous sequence of n items from a given sequence of text or speech. The items in question can be phonemes, syllables, letters, words or base pairs according to the application...
.
Gappy bigrams or skipping bigrams are word pairs which allow gaps (perhaps avoiding connecting words, or allowing some simulation of dependencies, as in a dependency grammar
Dependency grammar
Dependency grammar is a class of modern syntactic theories that are all based on the dependency relation and that can be traced back primarily to the work of Lucien Tesnière. Dependency grammars are distinct from phrase structure grammars , since they lack phrasal nodes. Structure is determined by...
).
Head word bigrams are gappy bigrams with an explicit dependency relationship.
The term is also used in cryptography
Cryptography
Cryptography is the practice and study of techniques for secure communication in the presence of third parties...
, where bigram frequency attacks have sometimes been used to attempt to solve cryptograms. See frequency analysis.
Bigrams help provide the conditional probability of a word given the preceding word, when the relation of the conditional probability
Conditional probability
In probability theory, the "conditional probability of A given B" is the probability of A if B is known to occur. It is commonly notated P, and sometimes P_B. P can be visualised as the probability of event A when the sample space is restricted to event B...
is applied:
That is, the probability
of a word given the preceding word is equal to the probability of their bigram, or the co-occurrence of the two words , divided by the probability of the preceding word.Bigram Frequency in the English language
The most common letter bigrams in the English language are listed below, according to Cornell University Math Explorer's Project which measured over 40,000 words.th 1.52% en 0.55% ng 0.18%
he 1.28% ed 0.53% of 0.16%
in 0.94% to 0.52% al 0.09%
er 0.94% it 0.50% de 0.09%
an 0.82% ou 0.50% se 0.08%
re 0.68% ea 0.47% le 0.08%
nd 0.63% hi 0.46% sa 0.06%
at 0.59% is 0.46% si 0.05%
on 0.57% or 0.43% ar 0.04%
nt 0.56% ti 0.34% ve 0.04%
ha 0.56% as 0.33% ra 0.04%
es 0.56% te 0.27% ld 0.02%
st 0.55% et 0.19% ur 0.02%