

AODE
Encyclopedia
Averaged one-dependence estimators (AODE) is a probabilistic classification learning technique. It was developed to address the attribute-independence problem of the popular naive Bayes classifier
. It frequently develops substantially more accurate classifiers than naive Bayes at the cost of a modest increase in the amount of computation.
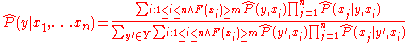
where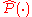 denotes an estimate of
denotes an estimate of 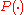 ,
, 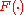 is the frequency with which the argument appears in the sample data and m is a user specified minimum frequency with which a term must appear in order to be used in the outer summation. In recent practice m is usually set at 1.
is the frequency with which the argument appears in the sample data and m is a user specified minimum frequency with which a term must appear in order to be used in the outer summation. In recent practice m is usually set at 1.
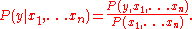
For any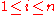 ,
,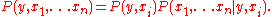
Under an assumption that x1, ... xn are independent given y and xi, it follows that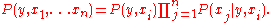
This formula defines a special form of One Dependence Estimator (ODE), a variant of the naive Bayes classifier
that makes the above independence assumption that is weaker (and hence potentially less harmful) than the naive Bayes' independence assumption. In consequence, each ODE should create a less biased estimator than naive Bayes. However, because the base probability estimates are each conditioned by two variables rather than one, they are formed from less data (the training examples that satisfy both variables) and hence are likely to have more variance. AODE reduces this variance by averaging the estimates of all such ODEs.
AODE has computational complexity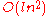 at training time and
at training time and 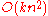 at classification time, where n is the number of features, l is the number of training examples and k is the number of classes. This makes it infeasible for application to high-dimensional data. However, within that limitation, it is linear with respect to the number of training examples and hence can efficiently process large numbers of training examples.
at classification time, where n is the number of features, l is the number of training examples and k is the number of classes. This makes it infeasible for application to high-dimensional data. However, within that limitation, it is linear with respect to the number of training examples and hence can efficiently process large numbers of training examples.
machine learning suite includes an implementation of AODE.
Naive Bayes classifier
A naive Bayes classifier is a simple probabilistic classifier based on applying Bayes' theorem with strong independence assumptions...
. It frequently develops substantially more accurate classifiers than naive Bayes at the cost of a modest increase in the amount of computation.
The AODE classifier
AODE seeks to estimate the probability of each class y given a specified set of features x1, ... xn, P(y | x1, ... xn). To do so it uses the formulawhere
denotes an estimate of , is the frequency with which the argument appears in the sample data and m is a user specified minimum frequency with which a term must appear in order to be used in the outer summation. In recent practice m is usually set at 1.Derivation of the AODE classifier
We seek to estimate P(y | x1, ... xn). By the definition of conditional probabilityFor any
,Under an assumption that x1, ... xn are independent given y and xi, it follows that
This formula defines a special form of One Dependence Estimator (ODE), a variant of the naive Bayes classifier
Naive Bayes classifier
A naive Bayes classifier is a simple probabilistic classifier based on applying Bayes' theorem with strong independence assumptions...
that makes the above independence assumption that is weaker (and hence potentially less harmful) than the naive Bayes' independence assumption. In consequence, each ODE should create a less biased estimator than naive Bayes. However, because the base probability estimates are each conditioned by two variables rather than one, they are formed from less data (the training examples that satisfy both variables) and hence are likely to have more variance. AODE reduces this variance by averaging the estimates of all such ODEs.
Features of the AODE classifier
Like naive Bayes, AODE does not perform model selection and does not use tuneable parameters. As a result, it has low variance. It supports incremental learning whereby the classifier can be updated efficiently with information from new examples as they become available. It predicts class probabilities rather than simply predicting a single class, allowing the user to determine the confidence with which each classification can be made. Its probabilistic model can directly handle situations where some data are missing.AODE has computational complexity
at training time and at classification time, where n is the number of features, l is the number of training examples and k is the number of classes. This makes it infeasible for application to high-dimensional data. However, within that limitation, it is linear with respect to the number of training examples and hence can efficiently process large numbers of training examples.Implementations
The free WekaWeka (machine learning)
Weka is a popular suite of machine learning software written in Java, developed at the University of Waikato, New Zealand...
machine learning suite includes an implementation of AODE.